G4周:CGAN,手势生成
本文为365天深度学习训练营 中的学习记录博客
原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习框架Pytorch 1.8.0+cu111
一、CGAN介绍
条件生成对抗网络(Conditional Generative Adversarial Network,简称cGAN)是一种深度学习模型,属于生成对抗网络(GAN)的一种变体。它的基本思想是通过训练生成器和判别器两个网络,使生成器能够生成与给定条件相匹配的合成数据,而判别器则负责区分真实数据和生成数据。cGAN在生成器和判别器的结构上引入了条件信息,使得生成过程可以受到外部条件的控制。
cGAN的结构包括两个主要部分:
-
生成器(Generator): 生成器负责从随机噪声和条件信息中生成合成数据。与普通的生成器不同的是,cGAN的生成器除了接收随机噪声作为输入,还接受一个条件向量,这个条件向量可以是任何有助于生成特定类型数据的信息,例如类别标签、图像特征等。生成器的目标是生成尽可能逼真的数据,使得判别器难以区分生成的数据和真实数据。
-
判别器(Discriminator): 判别器负责区分生成器生成的数据和真实数据。它接收真实数据和生成器生成的数据,通过学习鉴别两者的差异,从而推动生成器生成更逼真的数据。与生成器一样,判别器也接收条件向量,以帮助区分不同条件下的数据。
cGAN的训练过程是一个动态平衡的过程。生成器和判别器相互竞争,通过对抗的方式逐渐提升生成器生成真实样本的能力,同时判别器也不断提高对生成样本和真实样本的辨别能力。
cGAN在图像生成、图像编辑、风格转换等任务上取得了显著的成果,其能够根据给定条件生成具有语义信息的合成数据,为许多应用领域提供了强大的工具。
条件生成对抗网络(cGAN)有一些显著的特点,使其在许多任务中表现出色。以下是一些关键特点:
-
条件输入: cGAN引入了条件输入,使得生成器可以受到外部条件的指导。这个条件可以是任何形式的信息,例如类别标签、文本描述、图像特征等。这使得生成的结果更有针对性和语义合理性。
-
有监督学习: 由于条件信息的引入,cGAN在一些任务中可以进行有监督学习。通过提供真实样本的标签作为条件,生成器可以学习生成与给定标签相对应的合成数据,从而在特定任务上取得更好的性能。
-
图像到图像的转换: cGAN在图像生成任务中表现出色,特别是在图像到图像的转换任务上,例如图像翻译、风格迁移、超分辨率等。通过条件信息,生成器可以更好地理解并保留输入图像的语义结构。
-
样本多样性: cGAN的生成过程是基于随机噪声的,因此可以生成多样性的结果。在相同的条件下,生成器可以产生多个不同但符合条件的合成样本。
-
对抗训练: cGAN通过生成器和判别器的对抗训练,使得两者相互竞争,逐渐提升生成器的能力同时提高判别器的辨别能力。这种对抗训练的方式有助于生成更逼真的合成数据。
-
无监督学习: 虽然cGAN可以进行有监督学习,但它也可以在无监督设置下进行训练。在无监督学习中,生成器可以学习从随机噪声中生成逼真的数据,而无需额外的条件信息。
总体而言,cGAN以其能够根据条件信息生成具有高语义合理性和多样性的数据而著称,广泛应用于图像生成和转换任务。
二、准备工作
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets,transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torchsummary import summary
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')1、导入数据
train_transform = transforms.Compose([
transforms.Resize(int(128* 1.12)), ## 图片放大1.12倍
transforms.RandomCrop((128, 128)), ## 随机裁剪成原来的大小
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
train_dataset = datasets.ImageFolder(root='E:/GAN/G3/rps/', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=6)Resize与RandomCrop:将图像先放大再随机裁剪,有利于防止过拟合,获得更好的泛化能力。
ToTensor(): 将图像转换为 PyTorch 的张量(tensor)格式。
Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]): 对图像进行标准化,将其像素值归一化到 [-1, 1] 的范围。这里的参数分别是均值和标准差。
2、数据可视化
def show_images(dl):
for images,_ in dl:
fig,ax = plt.subplots(figsize=(10,10))
ax.set_xticks([]);ax.set_yticks([])
ax.imshow(make_grid(images.detach(),nrow=16).permute(1,2,0))
break
show_images(train_loader)
这段代码定义了一个名为 show_images 的函数,该函数接受一个 DataLoader 对象 dl 作为参数。在函数内部,通过迭代 DataLoader 中的每个批次数据(images,_),进行以下操作:
- 创建一个图形对象
fig和轴对象ax,设置图形大小为 (10,10)。 - 禁用坐标轴的刻度。
- 使用
make_grid函数将批次中的图像以16列的形式排列,并通过permute(1,2,0)调整维度顺序以适应 Matplotlib 图像显示的需求。 - 通过
ax.imshow在轴上显示调整后的图像。 - 使用
break语句,只显示 DataLoader 中的第一个批次,然后退出循环。

三、构建模型
latent_dim = 100
n_classes = 3
embedding_dim = 100weights_init用于权重初始化。
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 如果当前层是卷积层(类名中包含 'Conv' )
if classname.find('Conv') != -1:
# 使用正态分布随机初始化权重,均值为0,标准差为0.02
torch.nn.init.normal_(m.weight, 0.0, 0.02)
# 如果当前层是批归一化层(类名中包含 'BatchNorm' )
elif classname.find('BatchNorm') != -1:
# 使用正态分布随机初始化权重,均值为1,标准差为0.02
torch.nn.init.normal_(m.weight, 1.0, 0.02)
# 将偏置项初始化为全零
torch.nn.init.zeros_(m.bias)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中
# n_classes:条件标签的总数
# embedding_dim:嵌入空间的维度
self.label_conditioned_generator = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量
nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度
)
# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中
# latent_dim:潜在向量的维度
self.latent = nn.Sequential(
nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度
nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射
)
# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像
self.model = nn.Sequential(
# 反卷积层1:将合并后的向量映射为64x8x8的特征图
nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化
nn.ReLU(True), # ReLU激活函数
# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图
nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图
nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图
nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),
nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),
nn.ReLU(True),
# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像
nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),
nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内
)
def forward(self, inputs):
noise_vector, label = inputs
# 通过条件标签生成器将标签映射为嵌入向量
label_output = self.label_conditioned_generator(label)
# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并
label_output = label_output.view(-1, 1, 4, 4)
# 通过潜在向量生成器将噪声向量映射为潜在向量
latent_output = self.latent(noise_vector)
# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并
latent_output = latent_output.view(-1, 512, 4, 4)
# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图
concat = torch.cat((latent_output, label_output), dim=1)
# 通过生成器的主要结构将合并后的特征图生成为RGB图像
image = self.model(concat)
return image
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)
a = torch.ones(100)
b = torch.ones(1)
b = b.long()
a = a.to(device)
b = b.to(device)import torch
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量
self.label_condition_disc = nn.Sequential(
nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量
nn.Linear(embedding_dim, 3*128*128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量
)
# 定义主要的鉴别器模型
self.model = nn.Sequential(
nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1
nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力
nn.Conv2d(64, 64*2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*2, 64*4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2
nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理
nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险
nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量
nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值
)
def forward(self, inputs):
img, label = inputs
# 将类别标签转换为特征向量
label_output = self.label_condition_disc(label)
# 重塑特征向量为与图像尺寸相匹配的特征张量
label_output = label_output.view(-1, 3, 128, 128)
# 将图像特征和标签特征拼接在一起作为鉴别器的输入
concat = torch.cat((img, label_output), dim=1)
# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果
output = self.model(concat)
return output
-
条件标签的嵌入层:
self.label_condition_disc是一个包含两个层的序列。首先是一个嵌入层 (nn.Embedding),用于将类别标签编码为固定长度的向量。然后是一个线性层 (nn.Linear),将嵌入的向量转换为与图像尺寸相匹配的特征张量。
-
主要的鉴别器模型:
self.model是一个包含卷积层、批量归一化层、LeakyReLU激活函数、全连接层等的序列,构成了整个鉴别器的主体部分。- 输入通道为6,其中包括图像和经过嵌入层处理后的标签通道数。这是因为通过嵌入层后,标签被转换为一个与图像尺寸相匹配的特征张量。
- 通过卷积层和下采样,网络逐渐减小特征图的空间尺寸。
- 使用LeakyReLU激活函数,有助于网络对输入中的负值的感知能力。
- 批量归一化层有助于训练的稳定性和收敛速度。
- 使用
Flatten将最终的特征图展平为一维向量,用于后续的全连接层处理。 - Dropout层用于减少过拟合风险。
- 最后的全连接层将特征向量映射到输出维度为1的向量,而Sigmoid激活函数用于输出范围限制在0到1之间的概率值。
-
前向传播方法 (
forward):- 接受输入
inputs,其中包含图像img和标签label。 - 类别标签通过条件标签的嵌入层转换为特征向量,并重塑为与图像尺寸相匹配的特征张量。
- 将图像特征和标签特征在通道维度上拼接在一起,形成最终的输入。
- 通过鉴别器模型进行前向传播,得到输出结果,即对输入图像的鉴别结果。
- 接受输入
总体而言,这个鉴别器模型是一个基于卷积神经网络的条件GAN的组成部分,其设计旨在处理包含条件信息的图像数据。它通过将标签嵌入到特征向量中,并将其与图像特征拼接在一起,从而允许生成器和鉴别器之间的条件信息传递。
四、训练模型
1、损失函数
adversarial_loss = nn.BCELoss()
def generator_loss(fake_output, label):
gen_loss = adversarial_loss(fake_output, label)
return gen_loss
def discriminator_loss(output, label):
disc_loss = adversarial_loss(output, label)
return disc_loss2、优化器
learning_rate = 0.0002
G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))3、训练模型

# 设置训练的总轮数
num_epochs = 100
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []
# 循环进行训练
for epoch in range(1, num_epochs + 1):
# 初始化每轮训练中判别器和生成器损失的临时列表
D_loss_list, G_loss_list = [], []
# 遍历训练数据加载器中的数据
for index, (real_images, labels) in enumerate(train_loader):
# 清空判别器的梯度缓存
D_optimizer.zero_grad()
# 将真实图像数据和标签转移到GPU(如果可用)
real_images = real_images.to(device)
labels = labels.to(device)
# 将标签的形状从一维向量转换为二维张量(用于后续计算)
labels = labels.unsqueeze(1).long()
# 创建真实目标和虚假目标的张量(用于判别器损失函数)
real_target = Variable(torch.ones(real_images.size(0), 1).to(device))
fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))
# 计算判别器对真实图像的损失
D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)
# 从噪声向量中生成假图像(生成器的输入)
noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)
noise_vector = noise_vector.to(device)
generated_image = generator((noise_vector, labels))
# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)
output = discriminator((generated_image.detach(), labels))
D_fake_loss = discriminator_loss(output, fake_target)
# 计算判别器总体损失(真实图像损失和假图像损失的平均值)
D_total_loss = (D_real_loss + D_fake_loss) / 2
D_loss_list.append(D_total_loss)
# 反向传播更新判别器的参数
D_total_loss.backward()
D_optimizer.step()
# 清空生成器的梯度缓存
G_optimizer.zero_grad()
# 计算生成器的损失
G_loss = generator_loss(discriminator((generated_image, labels)), real_target)
G_loss_list.append(G_loss)
# 反向传播更新生成器的参数
G_loss.backward()
G_optimizer.step()
# 打印当前轮次的判别器和生成器的平均损失
print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % (
(epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)),
torch.mean(torch.FloatTensor(G_loss_list))))
# 将当前轮次的判别器和生成器的平均损失保存到列表中
D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))
G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))
if epoch%10 == 0:
# 将生成的假图像保存为图片文件
save_image(generated_image.data[:50], './images/sample_%d' % epoch + '.png', nrow=5, normalize=True)
# 将当前轮次的生成器和判别器的权重保存到文件
torch.save(generator.state_dict(), './training_weights/generator_epoch_%d.pth' % (epoch))
torch.save(discriminator.state_dict(), './training_weights/discriminator_epoch_%d.pth' % (epoch))-
总轮次和损失记录初始化:
num_epochs设置总的训练轮次。D_loss_plot和G_loss_plot是用于存储每轮训练中判别器和生成器损失的列表。
-
训练循环:
- 外层循环遍历每个训练轮次。
- 内层循环遍历训练数据加载器中的每个批次。
-
判别器训练(Discriminator Training):
- 清空判别器的梯度缓存。
- 将真实图像数据和标签移到GPU(如果可用)。
- 计算判别器对真实图像的损失(
D_real_loss)。 - 从噪声向量中生成假图像,并计算判别器对假图像的损失(
D_fake_loss)。 - 计算判别器总体损失(
D_total_loss),是真实图像损失和假图像损失的平均值。 - 反向传播更新判别器的参数。
-
生成器训练(Generator Training):
- 清空生成器的梯度缓存。
- 从噪声向量中生成假图像。
- 计算生成器的损失(
G_loss),这个损失是判别器对生成图像的输出与真实标签之间的误差。 - 反向传播更新生成器的参数。
-
打印和记录损失:
- 在每个训练轮次结束时,打印判别器和生成器的平均损失。
- 将当前轮次的判别器和生成器的平均损失保存到列表中。
-
可选的保存操作:
- 每隔10个训练轮次,生成一些假图像并将它们保存为图片文件。
- 将当前轮次的生成器和判别器的权重保存到文件。
这段代码的目标是通过训练生成器和判别器来生成逼真的图像,其中生成器试图生成足够逼真的图像以欺骗判别器,而判别器则试图区分真实图像和生成图像。在训练的过程中,两者通过对抗学习逐渐提高性能。
五、生成指定图像
from numpy.random import randint, randn
from numpy import linspace
from matplotlib import pyplot as plt, gridspec
import numpy as np
# Assuming 'generator' and 'device' are defined earlier in your code
generator.load_state_dict(torch.load('E:/GAN/G4/generator_epoch_300.pth'), strict=False)
generator.eval()
interpolated = randn(100)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)
label = 0
labels = torch.ones(1) * label
labels = labels.to(device).unsqueeze(1).long()
predictions = generator((interpolated, labels))
predictions = predictions.permute(0, 2, 3, 1).detach().cpu()
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
plt.figure(figsize=(8, 3))
pred = (predictions[0, :, :, :] + 1) * 127.5
pred = np.array(pred)
plt.imshow(pred.astype(np.uint8))
plt.show()
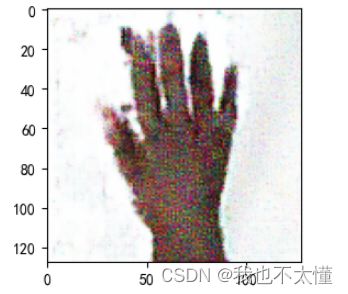
从已训练的生成器(generator)中加载参数,生成一张图像,并使用 Matplotlib 显示生成的图像。假设在代码的其他地方已经定义了生成器(generator)和设备(device)。这段代码加载预训练的生成器参数,并将生成器设置为评估模式(eval())。
生成一个包含 100 个随机数的噪声向量(interpolated),将其转换为 PyTorch 张量并移到指定的设备上。同时,创建一个标签(label)并将其转换为 PyTorch 张量,最后在设备上调整形状和数据类型。
使用生成器和生成的噪声与标签生成图像,并将图像的通道顺序调整为 Matplotlib 所需的顺序(通常是 HWC - Height, Width, Channel)。然后将图像的计算图分离(detach())并移动到 CPU 上。
创建一个 Matplotlib 图形对象,将生成的图像进行处理,然后使用 plt.imshow 显示图像。最后,通过 plt.show() 将图形显示出来。