图像预处理——transforms
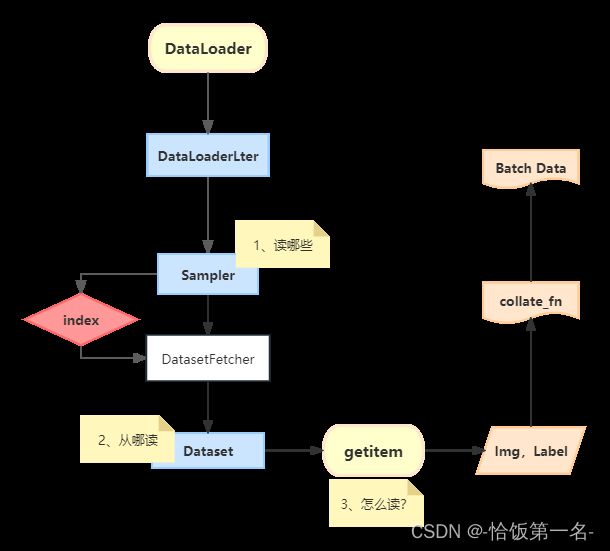
一、transforms 运行机制
torchvision是PyTorch的一个扩展库,提供了许多计算机视觉相关的工具和功能。下面是关于torchvision中常用模块的介绍:
torchvision.transforms:提供了一系列常用的图像预处理方法,用于对图像进行变换、缩放、裁剪、旋转、翻转等操作。例如,ToTensor将PIL图像或numpy数组转换为Tensor,Normalize对图像进行标准化处理,RandomCrop随机裁剪图像等。torchvision.datasets:包含了一些常用的数据集的dataset实现,方便用户加载和使用。例如,MNIST是一个手写数字数据集,CIFAR-10是一个包含10个类别的彩色图像数据集,ImageNet是一个大规模的图像数据集等。这些数据集可以方便地用于训练和评估模型。torchvision.models:提供了一些常用的预训练模型,可以用于图像分类、目标检测、图像分割等任务。这些模型包括了经典的网络结构,如AlexNet、VGG、ResNet、GoogLeNet等。用户可以通过加载预训练模型,快速搭建和使用这些模型。torchvision.utils:提供了一些辅助函数和工具,用于计算机视觉任务中的常见操作。例如,make_grid可以将多张图像拼接成一个网格显示,save_image可以将Tensor保存为图像文件,draw_bounding_boxes可以在图像上绘制边界框等。
torchvision.transforms
torchvision.transforms模块提供了一系列常用的图像预处理方法,用于对图像进行各种变换和操作。以下是一些常用的图像预处理方法:
- 数据中心化(Data normalization):
Normalize(mean, std):对图像进行均值和标准差的归一化处理。
- 数据标准化(Data standardization):
ToTensor():将PIL图像或numpy数组转换为Tensor,并将像素值缩放到[0, 1]范围内。
- 缩放(Resizing):
Resize(size):将图像的大小调整为指定的尺寸。RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.333)):随机裁剪并缩放图像到指定的尺寸。
- 裁剪(Cropping):
CenterCrop(size):从图像的中心裁剪出指定大小的区域。RandomCrop(size):随机裁剪图像的一部分。
- 旋转(Rotation):
RandomRotation(degrees):随机旋转图像一定角度。
- 翻转(Flipping):
RandomHorizontalFlip(p=0.5):以给定的概率随机水平翻转图像。RandomVerticalFlip(p=0.5):以给定的概率随机垂直翻转图像。
- 填充(Padding):
Pad(padding):在图像周围填充指定数量的像素。
- 噪声添加(Noise adding):
RandomNoise():向图像中添加随机噪声。
- 灰度变换(Grayscale transformation):
Grayscale(num_output_channels=1):将图像转换为灰度图像。
- 线性变换(Linear transformation):
RandomAffine(degrees, translate=None, scale=None, shear=None):随机仿射变换图像。
- 亮度、饱和度及对比度变换(Brightness, saturation, and contrast transformation):
AdjustBrightness(brightness_factor):调整图像的亮度。AdjustSaturation(saturation_factor):调整图像的饱和度。AdjustContrast(contrast_factor):调整图像的对比度。
这些方法可以根据需要组合使用,以实现对图像进行预处理和增强的目的。
transforms.Normalize
功能:逐channel的对图像进行标准化
output = (input - mean) / std
• mean:各通道的均值
• std:各通道的标准差
• inplace:是否原地操作
transforms.Normalize(mean, std, inplace=False)是torchvision.transforms模块中的一个图像预处理方法,用于对图像进行数据中心化(data normalization)的操作。
参数说明:
mean:用于数据中心化的均值,可以是一个标量或一个长度为图像通道数的列表/元组。如果图像是灰度图像,只需要提供一个标量;如果图像是彩色图像,需要提供每个通道的均值。std:用于数据中心化的标准差,可以是一个标量或一个长度为图像通道数的列表/元组。如果图像是灰度图像,只需要提供一个标量;如果图像是彩色图像,需要提供每个通道的标准差。inplace:是否原地操作,默认为False。如果设置为True,则会直接修改输入的Tensor,否则会返回一个新的Tensor。
数据中心化(data normalization)是一种常用的图像预处理操作,通过将图像的每个像素减去均值并除以标准差,将图像的像素值归一化到均值为0、标准差为1的范围内。这样做的目的是消除不同图像之间的亮度差异,使得图像在训练过程中更容易收敛。
使用示例:
import torchvision.transforms as transforms
# 定义均值和标准差
mean = [0.5, 0.5, 0.5] # RGB图像的均值
std = [0.5, 0.5, 0.5] # RGB图像的标准差
# 定义Normalize变换
normalize = transforms.Normalize(mean=mean, std=std)
# 对图像进行数据中心化
normalized_image = normalize(image)
上述示例中,mean和std分别表示RGB图像的均值和标准差。normalize是一个Normalize对象,可以将其应用于图像数据,实现数据中心化的操作。最终得到的normalized_image是一个经过数据中心化处理后的图像。
代码示例
"""
# @file name : transforms_methods_1.py
# @author : siuser
# @brief : transforms方法(一)
"""
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import numpy as np
import torch
import random
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
path_lenet = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "model", "lenet.py"))
path_tools = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "tools", "common_tools.py"))
assert os.path.exists(path_lenet), "{}不存在,请将lenet.py文件放到 {}".format(path_lenet, os.path.dirname(path_lenet))
assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools,
os.path.dirname(path_tools))
import sys
# 获取当前文件所在目录的绝对路径
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__) + os.path.sep + ".." + os.path.sep + "..")
# 将hello_pytorch_DIR添加到sys.path中,以便可以导入该目录下的模块
sys.path.append(hello_pytorch_DIR)
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed, transform_invert
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = {"1": 0, "100": 1}
# ============================ step 1/5 数据 ============================
# 获取数据集划分的路径
split_dir = os.path.abspath(os.path.join("..", "..", "data", "rmb_split"))
# 检查数据集划分路径是否存在,如果不存在则抛出异常
if not os.path.exists(split_dir):
raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir))
# 训练集路径
train_dir = os.path.join(split_dir, "train")
# 验证集路径
valid_dir = os.path.join(split_dir, "valid")
import torchvision.transforms as transforms
norm_mean = [0.485, 0.456, 0.406] # RGB图像的均值
norm_std = [0.229, 0.224, 0.225] # RGB图像的标准差
# 定义训练集的数据预处理操作
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为224x224
# 1 CenterCrop
# transforms.CenterCrop(512), # 512,将图像从中心位置裁剪为指定的大小,即将图像的宽度和高度都调整为512像素
# 2 RandomCrop
# transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
# 3 RandomResizedCrop
# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
# 4 FiveCrop
# transforms.FiveCrop(112),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 5 TenCrop
# transforms.TenCrop(112, vertical_flip=False),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 1 Horizontal Flip
# transforms.RandomHorizontalFlip(p=1),
# 2 Vertical Flip
# transforms.RandomVerticalFlip(p=0.5),
# 3 RandomRotation
# transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation
transforms.ToTensor(), # 将图像转换为Tensor类型
transforms.Normalize(mean=norm_mean, std=norm_std) # 对图像进行数据中心化
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整图像大小为224x224像素
transforms.ToTensor(), # 将图像转换为张量格式,将像素值从0-255映射到0-1之间
transforms.Normalize(norm_mean, norm_std) # 对图像张量进行标准化处理,使用给定的均值和标准差进行归一化
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform) # 构建训练数据集实例
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform) # 构建验证数据集实例
# 构建DataLoader
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # 构建训练数据加载器
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE) # 构建验证数据加载器
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # 获取输入数据和标签
img_tensor = inputs[0, ...] # 获取第一个样本的图像张量
img = transform_invert(img_tensor, train_transform) # 将图像张量转换为图像
plt.imshow(img) # 显示图像
plt.show() # 显示图像窗口
plt.pause(0.5) # 暂停0.5秒
plt.close() # 关闭图像窗口
# bs, ncrops, c, h, w = inputs.shape
# for n in range(ncrops):
# img_tensor = inputs[0, n, ...] # C H W
# img = transform_invert(img_tensor, train_transform)
# plt.imshow(img)
# plt.show()
# plt.pause(1)
os.path.abspath(file)
os.path.abspath(__file__)用于获取当前文件的绝对路径。
__file__是Python中的一个内置变量,表示当前文件的路径。os.path.abspath()函数可以将相对路径转换为绝对路径。
以下是一个示例代码,展示了如何使用os.path.abspath(__file__)获取当前文件的绝对路径:
import os
# 获取当前文件的绝对路径
file_path = os.path.abspath(__file__)
print(file_path)
在这个示例中,os.path.abspath(__file__)会返回当前文件的绝对路径,并将其赋值给file_path变量。然后,通过print()函数打印出file_path的值,即当前文件的绝对路径。
assert os.path.exists(path_lenet)
assert是Python中的一个关键字,用于在程序中进行断言(assertion)。断言是一种用于检查程序中的假设条件是否成立的方法。它是一种声明,用于确保在程序执行过程中某个特定的条件为真。如果断言条件为真,则程序继续执行;如果断言条件为假,则断言语句会抛出AssertionError异常,并中断程序的执行。
os.path.exists()是os.path模块中的一个函数,用于检查指定路径的文件或目录是否存在。它接受一个路径作为参数,并返回一个布尔值,表示指定路径是否存在。如果路径存在,则返回True;如果路径不存在,则返回False。
sys.path.append和os.path.join的区别
sys.path.append()和os.path.join()都是Python中用于处理路径的函数,但它们的作用和用法有所不同。
sys.path.append()是用于将路径添加到Python解释器搜索模块的路径列表中。在Python中,当你导入一个模块时,解释器会按照一定的顺序搜索模块所在的路径。sys.path是一个包含搜索路径的列表,sys.path.append()可以将指定的路径添加到这个列表的末尾,使得解释器能够搜索到该路径下的模块。
例如,如果你有一个自定义的模块,放在/path/to/my_module/目录下,你可以使用sys.path.append('/path/to/my_module/')将该路径添加到搜索路径中,然后就可以通过import my_module来导入该模块了。
os.path.join()是用于将多个路径组合成一个完整的路径。它接受多个路径作为参数,并根据当前操作系统的规则将它们连接起来。这个函数会自动处理不同操作系统的路径分隔符,确保生成的路径是正确的。
例如,假设你有两个路径'/path/to/directory/'和'file.txt',你可以使用os.path.join('/path/to/directory/', 'file.txt')来将它们连接起来,生成完整的路径'/path/to/directory/file.txt'。
总结一下:
sys.path.append()用于将路径添加到Python解释器搜索模块的路径列表中,以便能够导入该路径下的模块。os.path.join()用于将多个路径组合成一个完整的路径,确保生成的路径是正确的。