爬虫实战3-js逆向入门:以黑猫投诉平台为例
目录
引言
逆向过程
步骤一:找到参数对应js代码位置
步骤二:分析参数值的生成逻辑
步骤三:确定函数u的具体内容
步骤四:使用python实现请求参数的生成
投诉信息爬取
引言
下面是一张主流网页加密方法的思维导图,本文将介绍的黑猫投诉平台网站使用的即是请求头加密。
从开发者工具中抓包的结果来看,该网页的json数据包的请求参数中rs和signature两个参数在下拉后得到的新数据包中是动态变化的,而ts参数过一段时间会发生变化(推测应该是和时间戳相关的参数)。接下来就通过js逆向获取这几个参数的生成方法,并实现爬取投诉信息。
逆向过程
步骤一:找到参数对应js代码位置
由于用rs搜索容易重复,这里搜索signature参数,其中只有一个js文件中包含该变量名。
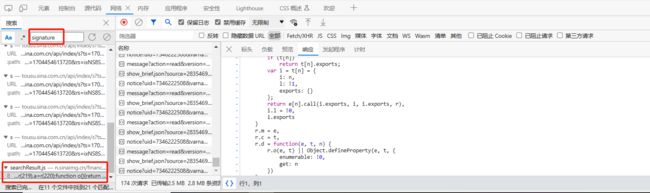
在js代码中再次搜索该变量名,发现共找到14个,为了找到真正的signature参数位置,对可能是该参数的位置打上断点,挨个尝试后确定获得signature参数值的位置在下图所示位置,实际是变量g的值。同时也可以清楚的看到ts和rs的值分别等于l和p两个变量的值。

步骤二:分析参数值的生成逻辑
从代码中很清楚的看到g的值通过这段代码赋予:var g = u([l, p, b, h, c, d["type" + e]].sort().join("")),也就是将这几个变量l, p, b, h, c, d["type" + e]排序后组成一个新的字符串,并将该字符串传入函数u,得到返回值即为g的值。
再往上找寻找上面几个变量的值的生成方式,可以发现在下图所示代码中,这些变量被创建和赋值。首先l变量确实是当前时间戳得到的值(l的值也是ts参数的值,印证了一开始的猜想);b是一个常数,值为"$d6eb7ff91ee257475%";h的值是PAGE_CONFIG对象的keywords属性的值,实际上从右边作用域可以看到就是我们的搜索关键字,值为"外卖 食品安全";c的值为10,它其实就是请求参数中的page_size的值;e的值从右边作用域也可以看到值为1,刷新网页该值不变,因此d["type" + e]的值可以确定为1;
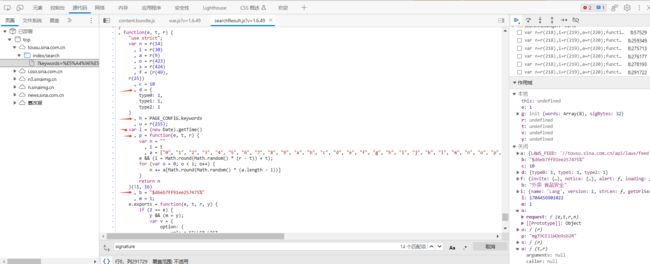
最后是p的值,也是请求参数rs的值,它是一个函数的返回值,不需要管这个函数是干什么的,用chatgpt把这段代码转为python代码即可,转换之前还需找到e和t的值是什么,也从右边发现两者值不变,分别是1和4,但e在代码中用于判断,因此转为python值其实是True,如下得到p值得生成方法,实质就是生成16位得随机字符串:
def generate_random_string(e=True, t=4, r=16):
chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
length = t if not e else random.randint(t, r)
return ''.join(random.choice(chars) for _ in range(length))步骤三:确定函数u的具体内容
将断点打到u函数的位置,跳到函数定义的位置


通过反复地打断点跟进,最终确定其执行的实际上是如下两个函数,其实质是执行了一次SHA-256 哈希算法。

知道他执行的是SHA-256 哈希算法后直接使用python对应的hashlib库中的方法即可。
步骤四:使用python实现请求参数的生成
直接放出代码
def generate_random_string(e=True, t=4, r=16):
chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
length = t if not e else random.randint(t, r)
return ''.join(random.choice(chars) for _ in range(length))
def get_sha256(value):
"""
sha256加密
:param value: 加密字符串
:return: 加密结果转换为16进制字符串,并大写
"""
hsobj = hashlib.sha256()
hsobj.update(value.encode("utf-8"))
return hsobj.hexdigest()
ts=str(int(time.time() * 1000))#ts,时间戳
l=ts
rs=generate_random_string(True, 4, 16)
p=rs#rs
b = '$d6eb7ff91ee257475%'
h='外卖 食品安全'#keywords
c='10'#page_size
d=str(i)#d["type" + e]=page
signature=''.join(sorted([l, p, b, h, c, d]))
signature=get_sha256(signature)
params = {
'ts': ts,
'rs': rs,
'signature': signature,
'keywords': h,
'page_size': c,
'page': d,
}到这里请求参数就构造完成了。
投诉信息爬取
下面是投诉信息的爬取,把cookies和headers复制下来,使用get方法获得每条投诉对应的具体信息页面的url,然后从该url中爬取需要的信息,我这里只需要投诉时间、结束时间和投诉编号,完整代码如下:
import requests
import random
import hashlib
import time
import json
from bs4 import BeautifulSoup
cookies = {
#自己复制
}
headers = {
#自己复制
}
#[l, p, b, h, c, d["type" + e]].sort().join("")
def generate_random_string(e=True, t=4, r=16):
chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
length = t if not e else random.randint(t, r)
return ''.join(random.choice(chars) for _ in range(length))
def get_sha256(value):
"""
sha256加密
:param value: 加密字符串
:return: 加密结果转换为16进制字符串,并大写
"""
hsobj = hashlib.sha256()
hsobj.update(value.encode("utf-8"))
return hsobj.hexdigest()
requests.packages.urllib3.disable_warnings()
sessions=requests.session()
data=[]
number=0
for i in range(1,101):#1524
print(i)
url_list=[]
if len(data)%50==0 and len(data)!=0:
time.sleep(60)
while True:
ts=str(int(time.time() * 1000))#ts,时间戳
l=ts
rs=generate_random_string(True, 4, 16)
p=rs#rs
b = '$d6eb7ff91ee257475%'
h='外卖 食品安全'#keywords
c='10'#page_size
d=str(i)#d["type" + e]=page
signature=''.join(sorted([l, p, b, h, c, d]))
signature=get_sha256(signature)
params = {
'ts': ts,
'rs': rs,
'signature': signature,
'keywords': h,
'page_size': c,
'page': d,
}
try:
response = sessions.get('https://tousu.sina.com.cn/api/index/s',cookies=cookies,
headers=headers,params=params,verify=False,allow_redirects=False)
response=json.loads(response.text)['result']['data']['lists']
#print(response)
for n in range(len(response)):
if response[n]['main']['evaluate_u']==None:
number+=1
continue
else:
url=response[n]['main']['url']
url_list.append(url)
number+=1
break
except Exception as e:
print(e,response.text,i)
time.sleep(300)
continue
for url in url_list:
while True:
try:
response = sessions.get('https:'+url,cookies=cookies,headers=headers,verify=False,allow_redirects=False)
soup = BeautifulSoup(response.text, 'html.parser')
u_date_elements = soup.find_all(class_='u-date')
u_list=soup.find('ul', class_='ts-q-list')
c_num=u_list.find_all('li')[0].text
endtime=u_date_elements[2].text
starttime=u_date_elements[6].text
data.append([starttime,endtime,c_num])
break
except Exception as e:
print(e,response.text,i)
time.sleep(60)
continue
data=pd.DataFrame(data,columns=['starttime','endtime','c_num'])