如何对 Databend 进行基准测试

Databend 的设计目标之一就是保持最佳性能,为了更好观测和评估性能,社区不光提供一套简单的本地基准测试方案,还建立了可视化的持续基准测试。
本地基准测试
hyperfine 是一种跨平台的命令行基准测试工具,支持预热和参数化基准测试。Databend 建议使用 hyperfine 通过 ClickHouse / MySQL 客户端执行基准测试,本文将使用 MySQL 客户端来介绍它。
前期准备:
进行本地基准测试之前,必须完成以下几项准备工作:
- 参照 Docs - Deploy Databend 1 完成部署。
- 安装 MySQL 客户端。
- 根据 hyperfine - installation2 的提示安装 hyperfine。
设计基准测试套件:
根据你的数据集特征和关键查询设计 SQL 语句,如果需要预先加载数据,请参考 Docs - Load Data 3 。
为方便示范,这里选用 Continuous Benchmarking - Vectorized Execution Benchmarking4 列出的 10 条语句,保存到 bench.sql 中。
SELECT avg(number) FROM numbers_mt(100000000000)
SELECT sum(number) FROM numbers_mt(100000000000)
SELECT min(number) FROM numbers_mt(100000000000)
SELECT max(number) FROM numbers_mt(100000000000)
SELECT count(number) FROM numbers_mt(100000000000)
SELECT sum(number+number+number) FROM numbers_mt(100000000000)
SELECT sum(number) / count(number) FROM numbers_mt(100000000000)
SELECT sum(number) / count(number), max(number), min(number) FROM numbers_mt(100000000000)
SELECT number FROM numbers_mt(10000000000) ORDER BY number DESC LIMIT 10
SELECT max(number), sum(number) FROM numbers_mt(1000000000) GROUP BY number % 3, number % 4, number % 5 LIMIT 10
复制代码使用 bash 脚本简化流程:
下面给出一个 benchmark.sh 范本,可以简化整个基准测试流程:
#!/bin/bash
WARMUP=3
RUN=10
export script="hyperfine -w $WARMUP -r $RUN"
script=""
function run() {
port=$1
sql=$2
result=$3
script="hyperfine -w $WARMUP -r $RUN"
while read SQL; do
n="-n "$SQL" "
s="echo "$SQL" | mysql -h127.0.0.1 -P$port -uroot -s"
script="$script '$n' '$s'"
done <<< $(cat $sql)
script="$script --export-markdown $result"
echo $script | bash -x
}
run "$1" "$2" "$3"
复制代码在这个脚本中:
- 使用 -w/--warmup & WARMUP 在实际基准测试之前运行 3 次程序执行来预热。
- 使用 -r/--runs & RUN 要求执行 10 次基准测试。
- 允许指定 Databend MySQL 兼容服务的端口。
- 允许指定输入的 SQL 文件,以及输出时的 Markdown 文件。
在使用前需要先运行 chmod a+x ./benchmark.sh 赋予其可执行权限。用法如下所示:
./benchmark.sh
复制代码 执行基准测试并获取结果:
在这个例子中,MySQL 兼容服务的端口是 3307 ,基准测试用到的 SQL 文件为 bench.sql , 预期的输出在 databend-hyperfine.md 。
./benchmark.sh 3307 bench.sql databend-hyperfine.md
复制代码当然,你可以根据自己的配置和需要进行调整。
注意:下面的示例是在 AMD Ryzen 9 5900HS & 16GB RAM 配置下运行产生,仅供参考。
终端中的输出如下所示:
Benchmark 1: "SELECT avg(number) FROM numbers_mt(100000000000)"
Time (mean ± σ): 3.486 s ± 0.016 s [User: 0.003 s, System: 0.002 s]
Range (min … max): 3.459 s … 3.506 s 10 runs
复制代码最终的结果会保存在 databend-hyperfine.md 中,如下所示。

持续基准测试
Databend 的持续基准测试由 GitHub Action + Vercel + DatabendCloud 强力驱动,在 datafuselabs/databend-perf 5 这个 repo 中开源了源代码和 Workflow。
基本介绍
项目布局:
.
├── .github/workflows # 持续集成工作流
├── benchmarks # YAML 格式的 SQL Query 测试套件
├── collector # 分类存放性能数据
├── front # 可视化前端
├── reload # YAML 格式的 Data Load 测试套件
└── script # 数据预处理脚本
复制代码Workflow:
持续基准测试工作流定时计划执行,Perf Workflow 会在每天 00:25 UTC(北京时间 08:25)执行,Reload Workflow 会在每周五 08:25 UTC(北京时间 16:25)执行。
- 通过 GitHub API 获取当前日期和最新版本的 TAG 。
- 利用 perf-tool 和 DatabendCloud 进行交互,运行测试。
- 持久化性能数据到 databend-perf 这一 repo 中 。
- 执行脚本处理数据,使之生成前端需要的格式。
- 构建前端,完成可视化。
测试套件:
databend-perf 中的测试套件分为 Query Benchmark 和 Load Benchmark 两类,前者放在 benchmarks 目录下,后者放在 reload 目录下。测试用 YAML 格式定义:
metadata:
table: numbers
statements:
- name: Q1
query: "SELECT avg(number) FROM numbers_mt(10000000000);"
复制代码metadata 中的 table 字段是必须的,且分配给每类 benchmark 的值都唯一。statements 则只需要指定 name 和 query 。
向量化执行基准测试:
定义在 benchmarks/numbers.yaml ,一组数值计算 SQL,利用 Databend 的 numbers 表函数提供百亿级别的数据量。完整语句也可以在 Continuous Benchmarking - Vectorized Execution Benchmarking6 查看。
Ontime 常见分析场景基准测试:
定义在 benchmarks/ontime.yaml ,一组常见的空中交通分析 SQL ,基于美国交通部公开的 OnTime 数据集,共计 202,687,654 条记录。当前此基准测试不包含 JOIN 语句,Q5、Q6、Q7 均采用优化后的形式。完整语句也可以在 Continuous Benchmarking - Ontime Benchmarking 7查看。
Ontime 数据集载入基准测试:
定义在 reload/ontime.yaml ,同样基于美国交通部公开的 OnTime 数据集,通过 s3 进行 COPY INTO 。
关键语句:
COPY INTO ontime FROM 's3:///m_ontime/'
credentials=(aws_key_id='AWS_KEY_ID' aws_secret_key='AWS_SECRET_KEY')
pattern ='.*[.]csv' file_format=(type='CSV' field_delimiter='\t' record_delimiter='\n' skip_header=1);
复制代码 上面 SQL 语句中的 m_ontime/ 目录即为数据集:由原来 60.8 GB 数据全部合并后,再拆分成 100 个大小相近的文件。
数据处理:
基准测试得到的数据是 Json 格式的,会分类存放到 collector 这个目录下。metadata 部分是包含表、版本、机器规格的信息;schema 部分则是对每条语句执行情况的统计,包括中位数、平均数等。示例:
{
"metadata":{
"table":"numbers",
"tag":"v0.7.92-nightly",
"size":"Large"
},
"schema":[
{
"name":"Q1",
"sql":"SELECT avg(number) FROM numbers_mt(10000000000);",
"min":0.305,
"max":0.388,
"median":0.354,
"std_dev":0.02701407040784487,
"read_row":10000000000,
"read_byte":80000000000,
"time":[
0.315,
0.326,
...
],
"error":[
],
"mean":0.34774024905853534
},
...
]
}
复制代码经由 stript/transform.go 处理,为每个查询的对应图表聚合数据,主要强调最大、最小、均值、中位数四个指标。
示例:
{
"title":"Q1",
"sql":"SELECT avg(number) FROM numbers_mt(10000000000);",
"lines":[
{
"name":"min",
"data":[
3.084,
3.097,
3.043,
...
],
...
}
],
"version":[
"v0.7.0-nightly",
"v0.7.1-nightly",
"v0.7.2-nightly",
...
],
"legend":[
"min",
...
],
"xAxis":[
"2022-03-28",
"2022-03-29",
"2022-03-30",
...
],
}
复制代码可视化:
目前可视化方案采用 React + Echarts 实现,每个图表都对应上面处理得到的一个 Json 文件。在添加新的基准测试后,无需修改前端即可展现新的图表。
Graphs:
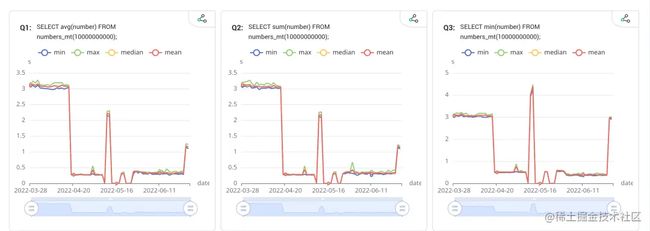
- 以折线图的形式展示性能变化,并支持通过拖动图表下方的选择器调整展示的时间区间。
- 横轴为日期,纵轴为执行用时,鼠标悬浮到上方即可查看当次执行的信息。
Compare:
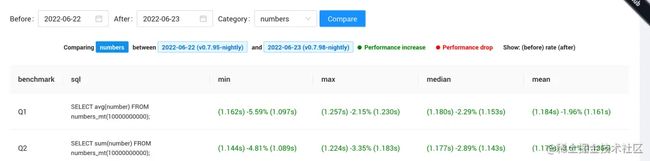
- 支持任选两天对比执行用时的变化,以百分比形式展示。
Status:

- 关注当前最新性能测试结果中各指标的情况,以柱型图展示。
- 横轴为不同类型,纵轴为执行用时。
后续优化
目前 perf.databend.rs 为 Databend 提供了基本的持续性能监控方案,但仍然需要关注以下几个方向的内容:
- 选取更有代表性的指标:执行次数较少(只有 10 次),可供选择的指标可能不够具有代表性。例如:将次数提高到 100 次以获取 P90 来替代当前使用的中位数可能是比较合适的。
- 增加性能测试场景的覆盖:后续可以继续新增对其他数据集和场景的性能测试,比如 ssb 、hits 。
- 丰富性能监控的方向:监控 IO 和网络性能表现,对部分重点查询提供额外的性能评估,比如解析 Json 的性能表现。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
-
Databend 文档:databend.rs/
-
Twitter:twitter.com/Datafuse_La…
-
Slack:datafusecloud.slack.com/
-
Wechat:Databend
-
GitHub :github.com/datafuselab…
 文章首发于公众号:Databned
文章首发于公众号:Databned
Footnotes
-
databend.rs/doc/deploy ↩
-
github.com/sharkdp/hyp… ↩
-
databend.rs/doc/load-da… ↩
-
databend.rs/doc/contrib… ↩
-
github.com/datafuselab… ↩
-
databend.rs/doc/contrib… ↩
-
databend.rs/doc/contrib… ↩