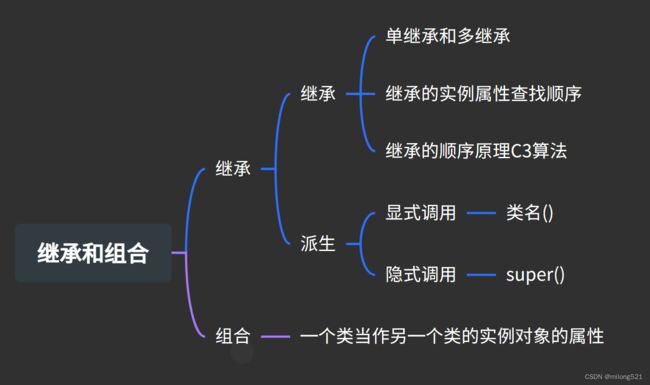
Python 面向对象之继承和组合
【一】继承
【1】概念
- 继承是面向对象的三大特征之一
- 继承允许一个类继承另一个类的属性和方法
- 继承可以使代码重用,解决类与类之间代码重复的问题
【2】代码解释
class PeaShooter:
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def twist_body(self):
print(f"{self.name}在扭动身体")
def shoot(self):
print(f"{self.name}发射了一颗豌豆")
class DoublePeaShooter:
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def twist_body(self):
print(f"{self.name}在扭动身体")
def shoot(self):
print(f"{self.name}发射了两颗豌豆")
- 可以看到这两个类之间有太多重复的内容了,所以使用在创建双发射手的时候使用继承
- 可以直接继承他们的属性(名字和攻击力),继承方法(扭动身体的方法),重写方法(攻击)
class PeaShooter:
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def twist_body(self):
print(f"{self.name}在扭动身体")
def shoot(self):
print(f"{self.name}发射了一颗豌豆")
class DoublePeaShooter(PeaShooter):
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def shoot(self):
print(f"{self.name}发射了两颗豌豆")
plant_one = DoublePeaShooter("双发射手", 20)
print(plant_one.name)
plant_one.twist_body()
plant_one.shoot()
- python支撑多继承,新建的类可以继承一个或者多个父类
- 多继承的例子,我们来简单的写以下豌豆僵尸
- 豌豆僵尸继承了豌豆射手类和僵尸类

class PeaShooter:
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def shoot(self):
print(f"{self.name}发射了一颗豌豆")
class Zombie:
def __init__(self, name, health):
self.name = name
self.health = health
def walk(self):
print(f"{self.name}正在前进")
class ZombiePeashooter(Zombie, PeaShooter):
def __init__(self, name, attack_value, health):
self.name = name
self.health = health
self.attack_value = attack_value
special_zombies = ZombiePeashooter("豌豆射手僵尸", 20, 100)
print(special_zombies.name)
print(special_zombies.health)
special_zombies.shoot()
special_zombies.walk()
【3】经典类和新式类
- 经典类:没有继承
object类的所有子类
- 新式类:继承了
object类的子类
- 在
Python3中如果不写继承关系那么就将默认继承object类,所以**Python3里面都是新式类**
【二】实例属性查找顺序
【1】不存在隐藏属性(简单继承)
- 先从自己的**
__dict__**中查找
- 然后从对象所在的类中查找
- 然后去父类中查找
- 最后去**
object中查找,没有就要报错**了
class A:
only1 = "在父类A"
only2 = "在父类A"
only3 = "在父类A"
class B(A):
only1 ="在对象所在类B"
only2 ="在对象所在类B"
def __int__(self):
self.only1 = "在实例化方法中"
b = B()
print(b.only1)
print(b.only2)
print(b.only3)
【2】存在隐藏属性时(简单继承)
- 父类的隐藏属性或者方法无法被子类查找到,因为属性或方法的变形发生在每个类的定义阶段,子类无法知道父类的属性或方法是否变形
class A:
__only = "类A的私有属性"
def __only_func(self):
print("类A的私有方法")
class B(A):
...
b = B()
b.__only
b.__only_func()
- 思考题:父类调用和子类同名的私有方法,这个会执行父类的还是子类的私有方法?
class A:
def __only_func(self):
print("类A的私有方法")
self.__only_func()
def run(self):
print(self)
self.__only_func()
class B(A):
def __only_func(self):
print("类B的私有方法")
- 答案:会执行夫类的私有方法,因为此时父类中的self实例虽然是子类的实例,但是父类中的私有方法调用已经产生了变形,变形结果是父类的方法,所以会执行父类的私有方法
class A:
def __only_func(self):
print("类A的私有方法")
def run(self):
print(self)
self.__only_func()
class B(A):
def __only_func(self):
print("类B的私有方法")
b = B()
b.run()
【三】继承顺序原理
【0】补充:广度优先搜索和深度优先搜索

(1)广度优先搜索
- 广度优先搜索(
BFS)是一种图形搜索算法,用于遍历或搜索图数据结构的所有节点。在广度优先搜索中,从图的起始节点开始,首先访问起始节点,然后依次访问其相邻节点,接着访问这些相邻节点的相邻节点,以此类推。
- 个人总结,从起始节点开始一次遍历相邻的节点并保存这些节点的信息(这些节点的相邻节点),在遍历完其实节点的所有相邻节点以后,以起始节点遍历的第一个节点当作新的起始节点继续访问其相邻节点并保存信息,一次循环往复**(一层一层往外拨)**
- 左边的视图,以G为起始节点遍历得到E和F,G遍历完以后遍历E的相邻节点得到C,然后遍历F的相邻节点得到D。。。所以顺序是**
GEFCDAB**
- 右边的视图,以F为起始节点遍历得到D和E,F遍历完以后遍历D的相邻节点得到A,然后遍历E的相邻节点得到C。。。所以顺序是**
FDEACB**
(2)深度优先搜索
- 深度优先搜索(
DFS)是一种图形搜索算法,用于遍历或搜索图数据结构的所有节点。在深度优先搜索中,从图的起始节点开始,首先访问起始节点,然后沿着图的一条路径一直访问到最深的节点,直到无法继续深入为止,然后回溯到前一个节点,继续探索其他路径。
- 个人总结,从起始节点开始沿着第一个相邻节点开始往下走,直到遇到岔路口是保存岔路信息,一次循环往复,直到走到底时,返回上一个分叉路口,走另一条路,继续循往复,最终按照这个总的逻辑循环执行**(一条路走到底返回继续一条路走到底)**
- 左边的视图,以G为起始节点遍历时,是一个分叉路口,保存分叉路口信息,沿着第一个节点E开始遍历,由于后面是直线直接走到底,然后返回分叉路口信息,走另一个路口,所以顺序是**
GECAFDB**
- 右边的视图,以F为起始节点遍历时,是一个分叉路口,保存分叉路口信息,沿着第一个节点D开始遍历,由于后面是直线直接走到底,然后返回分叉路口信息,走另一个路口,所以顺序是**
FDAECB**
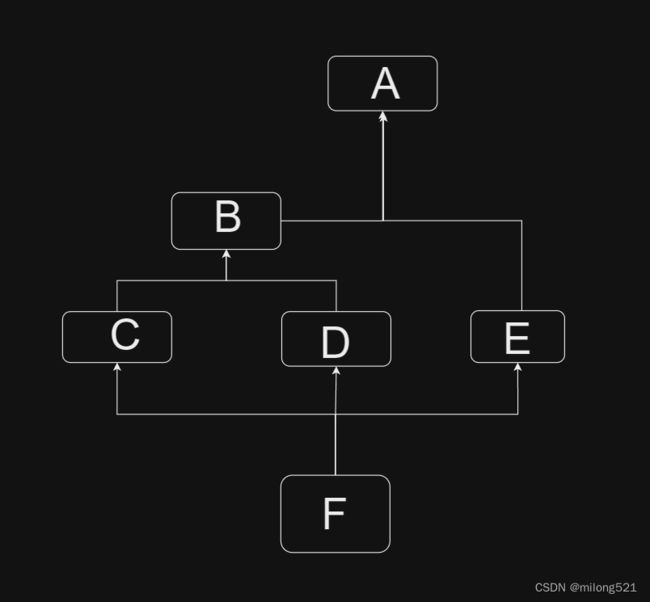
(3)简单练习
- 广度优先搜索(F出发):
FCDEBA
- 深度优先搜索(F出发):
FCBADE
【1】类的继承顺序
(1)概念解释
- 继承的顺序在python中是由
C3线性化算法来确定的,也被称为C3算法
C3算法基本原则:
- 线性化: 对于每个类,将其父类的线性化合并,再加上类本身,形成该类的线性化。
- 合并: 在线性化的过程中,需要合并多个线性化的顺序。合并的规则是从左到右,依次取各个线性化中的第一个类,检查它在其他线性化中是否也位于第一个位置,如果是,就去掉这个类,继续检查下一个位置,直到找到一个不位于其他线性化首位置的类,将其添加到结果中。
- 个人总结(理不理解都不重要):在不管object类的情况下(看着简单点),先将所有的砖石(菱形)继承关系处理(处理方法:砖石顶部先不管,将砖石身和砖石底部按照深度优先搜索遍历,遍历的结果变成一条直线放在该位置),在处理完所有砖石(菱形)继承关系以后,此时的继承关系图应该像树根一样,最后按照深度优先搜索即可
- 上述三个视图的继承关系
- 视图1:
GECAFDB
- 视图2:
FDAECB
- 视图3:
FCDBEA
- 根据视图3结果:可以看到它既不是深度优先搜索也不是广度优先搜索
(2)mro()方法查看继承顺序
- 为什么上面说理不理解都不重要呢,因为可以使用**
mro()方法直接得到继承继承顺序**
__mro__返回的是元组mro()返回的是列表
class A():
pass
class B(A):
pass
class C(B):
pass
class D(B):
pass
class E(A):
pass
class F(C, D, E):
pass
print(F.mro(), type(F.mro()))
print(F.__mro__, type(F.__mro__))
print("".join([i.__name__ for i in F.mro()]))
【4】派生
【1】概念
- 派生通常指的是通过已经有的类创建新的类,新的类继承了已有类的特性(属性和方法),并且可以在此基础上太你家新的特性或修改已有的特性
- 派生的方式有两种:
- 第一种是通过类名显示调用父类的属性或方法(类名调用)
- 第二种是使用
super()隐式调用(函数super)
- super是给新式类用的
python2中使用super(类名,self).属性
【2】代码
class PeaShooter:
def __init__(self, name, attack_value):
self.name = name
self.attack_value = attack_value
def shoot(self):
print(f"{self.name}发射了一颗豌豆")
class DoublePeaShooter(PeaShooter):
def __init__(self, name, attack_value):
super().__init__(name, attack_value)
def shoot(self):
print(f"{self.name}发射了一颗豌豆")
super().shoot()
【五】组合
【1】概念
- 组合:组合是一种设计模式,它允许一个类包含其他类的对象,使得一个类的实例可以拥有其他类的对象,从而形成更加复杂的结构。
- 在一个类中以另一个类的对象作为属性,称为类的组合
- 组合和继承都是解决代码的重用性问题
- 继承是一种是的关系,谁是谁的
- 组合是一种有的关系,谁有谁
【2】代码演示
class SpecialPea:
def __init__(self, name, special_str):
self.pea_name = name
self.special_str = special_str
def introduce_pea(self):
print(f"我的特殊豌豆是{self.pea_name}, 功能是{self.special_str}")
class Peashooter:
def __init__(self, name):
self.name = name
if "火焰" in name:
self.pea = SpecialPea("火焰豌豆", "烧伤")
elif "寒冰" in name:
self.pea = SpecialPea("寒冰豌豆", "减速")
shooter1 = Peashooter("寒冰豌豆射手")
shooter2 = Peashooter("火焰豌豆射手")
print(shooter1.pea.pea_name)
shooter1.pea.introduce_pea()
print(shooter2.pea.pea_name)
shooter2.pea.introduce_pea()
【六】总结