数据分析——快递电商
一、任务目标
1、任务
总体目的——对账
本项目解决同时使用多个快递发货,部分隔离区域出现不同程度涨价等情形下,如何快速准确核对账单的问题。
1、在订单表中新增一列【运费差异核对】来表示订单运费实际有多少差异,结果为数值。
2、将整个核对过程包装为一个OrderCheck类,方便后续直接调用它进行数据核对。
二、数据形式
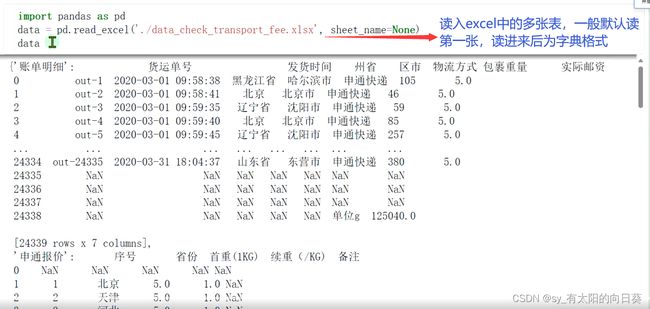
1、图像呈现
账单形式
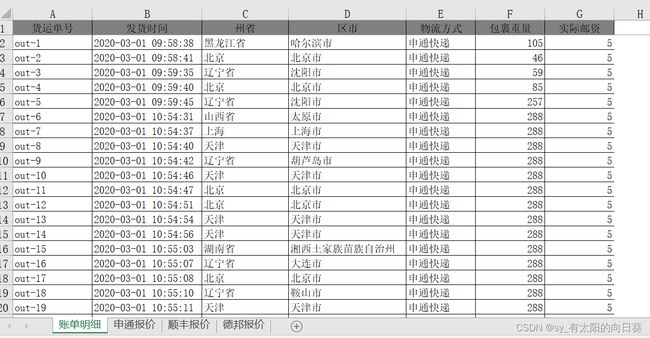
邮寄费(不同公司)
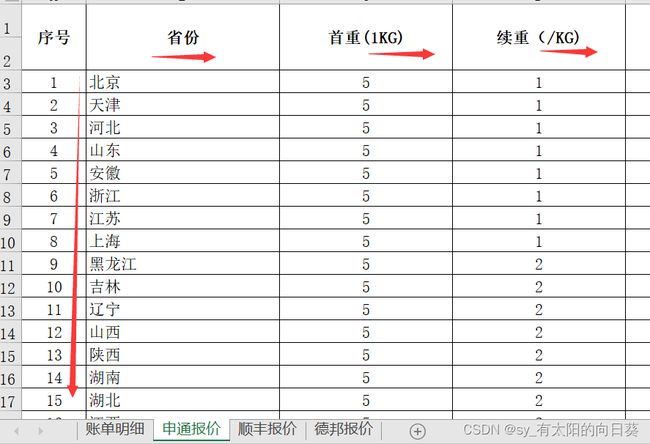
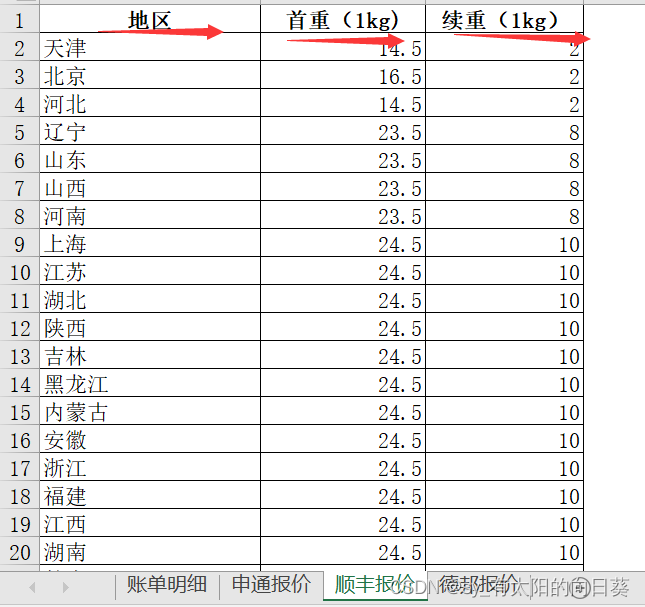
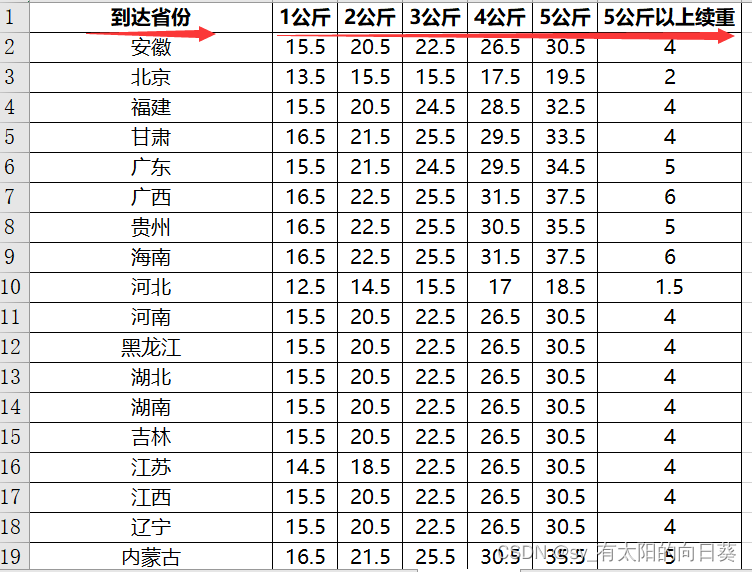
2、文字描述
一个excel文件中有四个表,第一张是账单形式,后面是不同公司的计费方式
每个公司的信息不同(如送达地址的描述、包裹重量单位等),需要统一
三、分析步骤
1、导入数据
3.1.1存在问题
问题一:
由于原数据表中有空格,或最后有总计、数据源等不规则信息导致的,需要进行处理

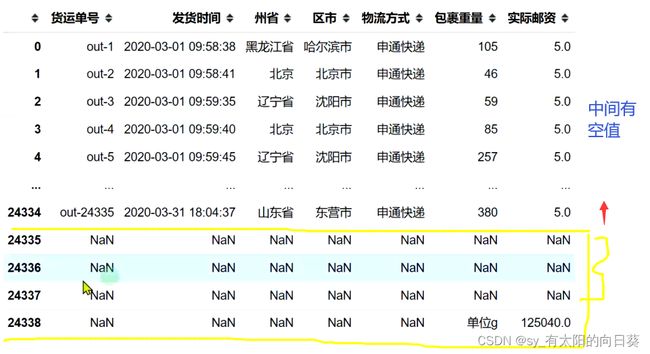
问题二:
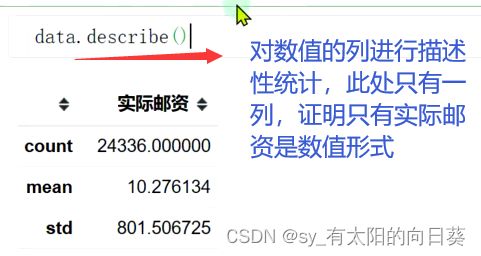
用describe()查看数值信息,发现只有邮资是纯数值,则需要对其他属性的数据进行数值转换
本数据源中,理应只有包裹重量和实际邮资是数值
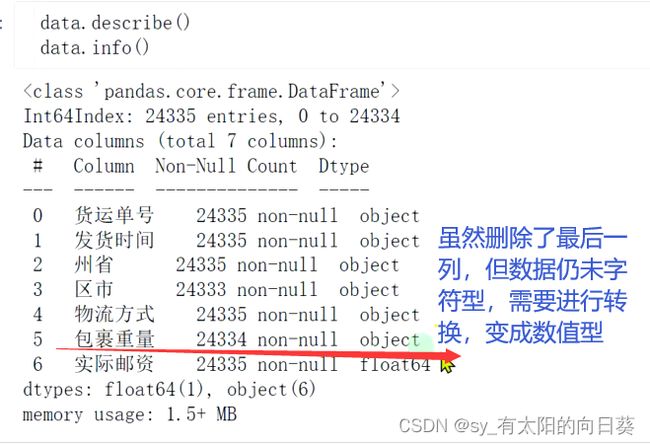
但由于包裹重量的最后一行是单位(整个表最后的统计部分),不能被统计为数值

3.1.2解决方案
1、处理空行和空值
思路1:用loc定位删除空行
缺点:若新加入表,则行索引会改变,定位也就改变了
思路2:删除重复值
因为有三行空值,可先删除重复的空行
缺点:前面有数据的部分也许也会有重复值,容易导致数据缺失
思路3:统计每一行空值,判断需要删除的行



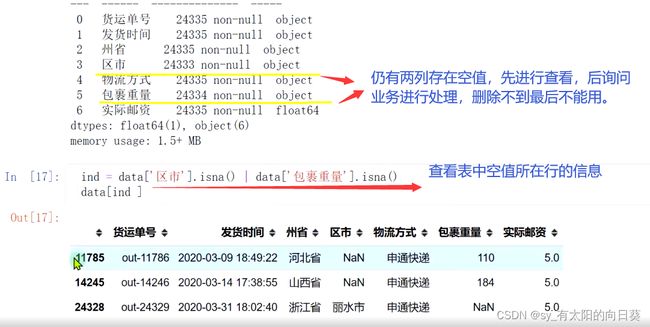

2、数据类型转换

3.1.3
语法扩展
2、数据处理
3.2.1计算运费
方法一:for循环算每一行
分析:根据地区、快递公司、重量计算运费
问题1:地区不统一
每个表的“地区”描述形式不一样



处理1:
1、读入所有表


2、统一各个表的名称
一张表:
reaname(,inplace=True)
![]()
多张表:


问题2:内容不统一
每个表省份的内容不一样
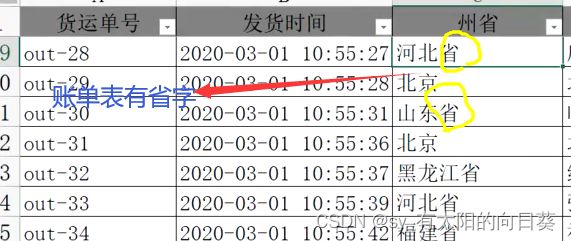
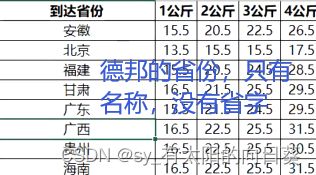
处理2:

问题3:单位不统一
每个表首重续重的写法不同,需要统一
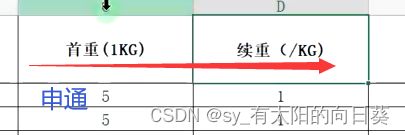
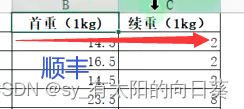
处理3:

问题4:时间是object型,而非数值型
不能直接用于时间的比较和计算,需要转换
处理4:

进一步分析
1、取出所需数据
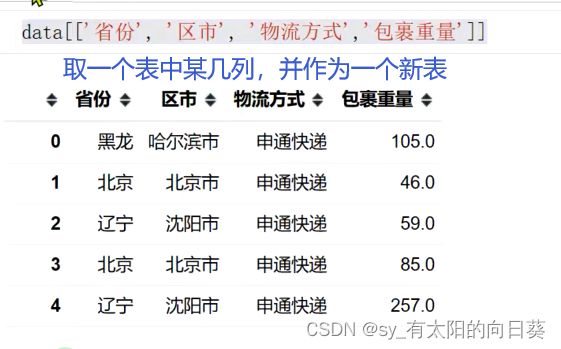



2、计算每一行的运费
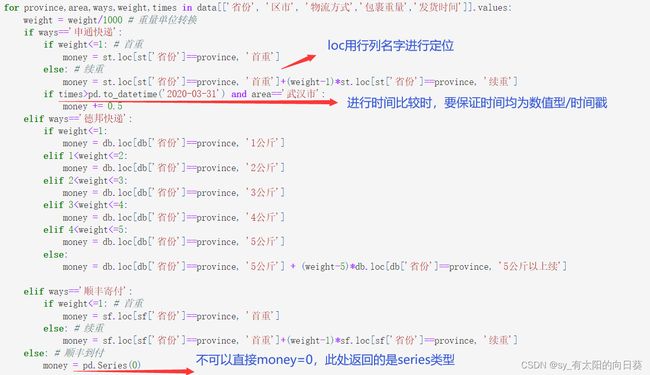
一个小问题,关于money的取值
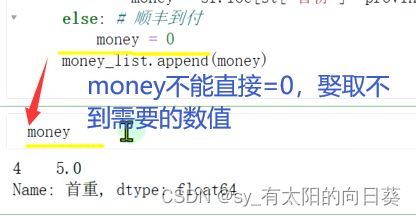


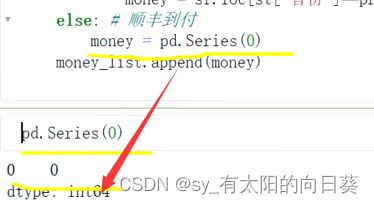
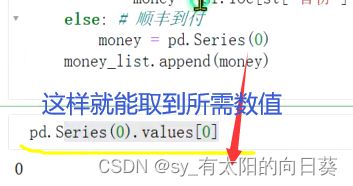
方法二:apply()算某一行
暂未开发
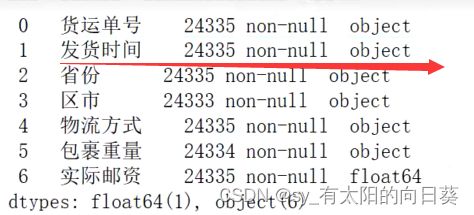
3、数据分析
3.3.1将计算结果放入一个列表
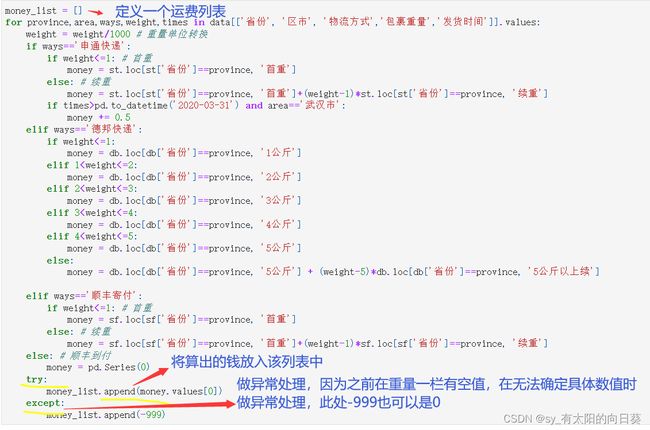
3.3.2将所需数据加入表中
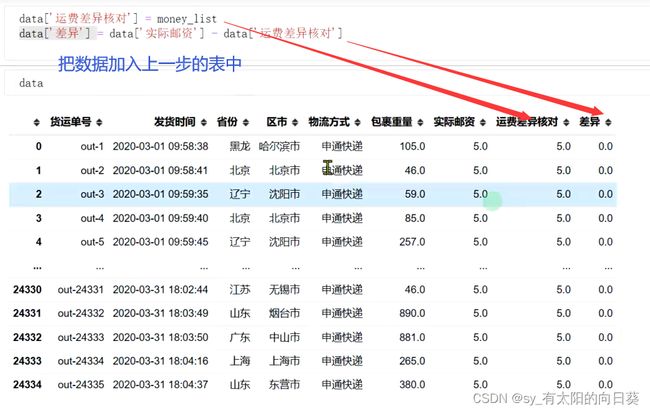
4、封装类
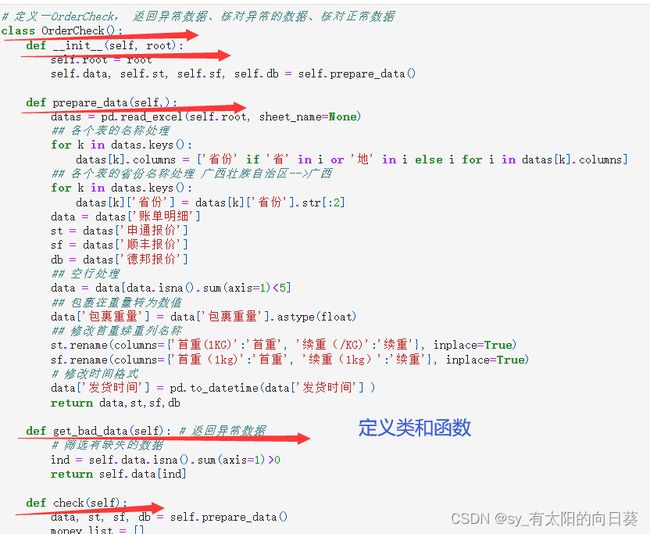
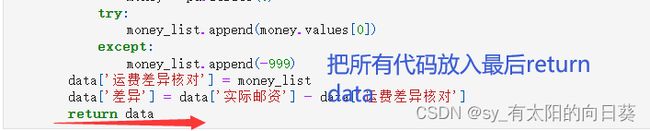
5、运行检查得结论
1、调用
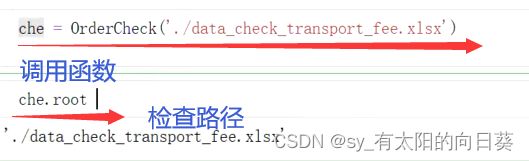
2、检查是否成功
3、数据异常
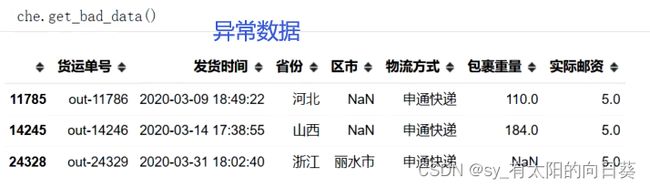
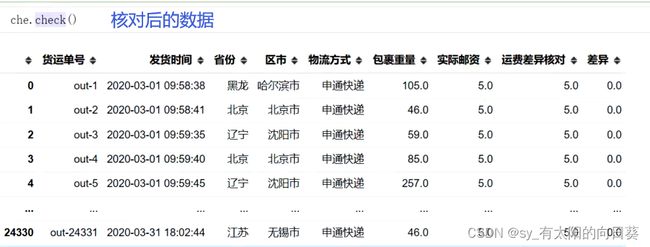
4、 核对后的数据
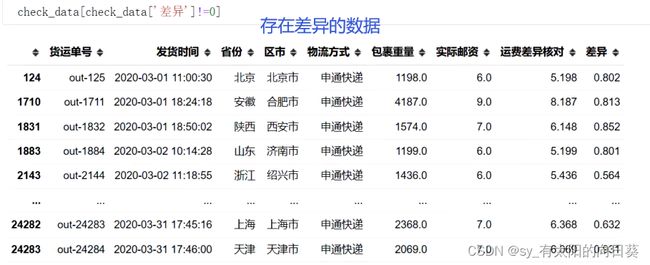
5、 存在差异的数据
四、总体代码
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
datas = pd.read_excel('./data_check_transport_fee.xlsx', sheet_name=None)
datas.keys()
# 各个表的名称处理
for k in datas.keys():
datas[k].columns = ['省份' if '省' in i or '地' in i else i for i in datas[k].columns]
# 各个表的省份名称处理 广东省---->广东
for k in datas.keys():
datas[k]['省份'] = datas[k]['省份'].str[:2]
#把每张表拿出来
data = datas['账单明细']
st = datas['申通报价']
sf = datas['顺丰报价']
db = datas['德邦报价']
# 空行处理
data = data[data.isna().sum(axis=1)<5]
data.shap
# 筛选有缺失的数据
ind = data.isna().sum(axis=1)>0
data[ind ]
# 包裹在重量转为数值
data['包裹重量'] = data['包裹重量'].astype(float)
# 修改首重续重列名称
st.rename(columns={'首重(1KG)':'首重', '续重(/KG)':'续重'}, inplace=True)
sf.rename(columns={'首重(1kg)':'首重', '续重(1kg)':'续重'}, inplace=True)
# 修改时间格式
data['发货时间'] = pd.to_datetime(data['发货时间'] )
money_list = []
for province,area,ways,weight,times in data[['省份', '区市', '物流方式','包裹重量','发货时间']].values:
weight = weight/1000 # 重量单位转换
if ways=='申通快递':
if weight<=1: # 首重
money = st.loc[st['省份']==province, '首重']
else: # 续重
money = st.loc[st['省份']==province, '首重']+(weight-1)*st.loc[st['省份']==province, '续重']
if times>pd.to_datetime('2020-03-31') and area=='武汉市':
money += 0.5
elif ways=='德邦快递':
if weight<=1:
money = db.loc[db['省份']==province, '1公斤']
elif 1广西
for k in datas.keys():
datas[k]['省份'] = datas[k]['省份'].str[:2]
data = datas['账单明细']
st = datas['申通报价']
sf = datas['顺丰报价']
db = datas['德邦报价']
## 空行处理
data = data[data.isna().sum(axis=1)<5]
## 包裹在重量转为数值
data['包裹重量'] = data['包裹重量'].astype(float)
## 修改首重续重列名称
st.rename(columns={'首重(1KG)':'首重', '续重(/KG)':'续重'}, inplace=True)
sf.rename(columns={'首重(1kg)':'首重', '续重(1kg)':'续重'}, inplace=True)
# 修改时间格式
data['发货时间'] = pd.to_datetime(data['发货时间'] )
return data,st,sf,db
def get_bad_data(self): # 返回异常数据
# 筛选有缺失的数据
ind = self.data.isna().sum(axis=1)>0
return self.data[ind]
def check(self):
data, st, sf, db = self.prepare_data()
money_list = []
for province,area,ways,weight,times in data[['省份', '区市', '物流方式','包裹重量','发货时间']].values:
weight = weight/1000 # 重量单位转换
if ways=='申通快递':
if weight<=1: # 首重
money = st.loc[st['省份']==province, '首重']
else: # 续重
money = st.loc[st['省份']==province, '首重']+(weight-1)*st.loc[st['省份']==province, '续重']
if times>pd.to_datetime('2020-03-31') and area=='武汉市':
money += 0.5
elif ways=='德邦快递':
if weight<=1:
money = db.loc[db['省份']==province, '1公斤']
elif 1 五、总结
5.1难点总结
1、异常值处理
询问业务、手动填补、try
2、名称、内容、单位、数值类型的统一
3、重量计算
用定位实现,要注意取不到最后一行的需要+1
4、类的书写和函数定义
取值需要多尝试,要清楚的判断数值类型,输出类型,用value或多套data,或者分开取
5.2方案总结
5.2.1思维总结
1、对于订单、账单等含有多种数值、涉及计算的数据源,需要多次用info()查看数据类型,确保类型为纯数值,方便后续处理
2、拿到数据源后,要根据目标or要得到的分析结果,判断表中的有效信息数据为哪些,并取出来
3、找表之间的关系时,想到表连接,或内容匹配(如:河北省与河北,都有河北二字,就取相同值)
5.2.2方法总结
1、数值转换
2、空值处理
isna()
3、将数据加入列表再加入表
4、数值获取
········太多了都在上面了