Python每日一练(数据分析篇)——第37天:数据清洗
文章目录
- 1. 去掉信息不全的用户
- 2. 修补缺失的用户数据
- 3. 解决牛客网用户重复的数据
- 4. 统一最后刷题日期的格式
- 《100天精通Python》专栏推荐白嫖80g Python全栈视频
1. 去掉信息不全的用户
描述: 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
运营同学正在做用户调研,为了保证调研的可靠性,想要去掉那些信息不全的用户,即去掉有缺失数据的行,请你帮助他去掉后输出全部数据。

实现代码:
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder.dropna(how = 'any'))
运行结果:

2. 修补缺失的用户数据
描述: 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
运营同学拿到了这份用户文件,但是由于系统BUG,出现了部分缺失的值,请你使用当前的最大年份填充缺失的毕业年份(“Graduate_year”),用Python填充缺失的常用语言(“Language”),用成就值的均值(四舍五入保留整数)填充缺失的成就值(“Achievement_value”)。
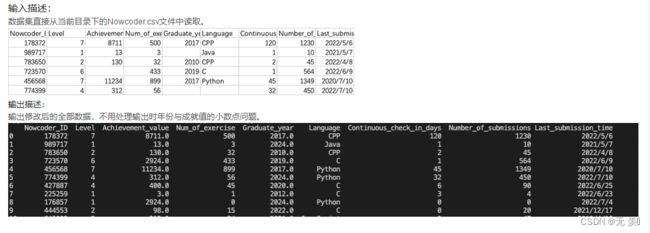
实现代码:
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
max_year=Nowcoder['Graduate_year'].max()
achieve_avg=Nowcoder['Achievement_value'].mean()
print(Nowcoder.fillna({'Graduate_year':max_year,'Language':'python','Achievement_value':achieve_avg}))
运行结果:

3. 解决牛客网用户重复的数据
描述: 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
牛牛拿到这份文件的时候一脸懵逼,因为系统错误将很多相同用户的数据输出了多条,导致文件中有很多重复的行,请先检查每一行是否重复,然后输出删除重复行后的全部数据。
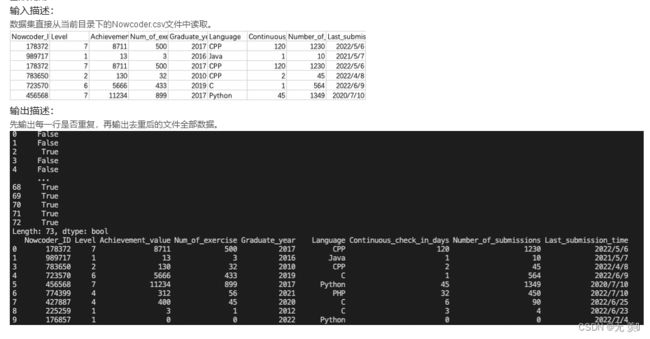
实现代码:
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 1000)
pd.set_option('display.max_rows', None)
print(Nowcoder.duplicated(subset=None, keep='first'))
print(Nowcoder.drop_duplicates())
运行结果:

4. 统一最后刷题日期的格式
描述: 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
运营同学发现最后一次提交题目日期这一列有各种各样的日期格式,这对于他分析用户十分不友好,你能够帮他输出用户ID、等级以及统一后的日期吗?(日期格式统一为yyyy-mm-dd)

实现代码:
import pandas as pd
#read_csv自带参数parse_dates,讲字段为datetime
df = pd.read_csv('Nowcoder.csv', sep=',', dtype=object,parse_dates=['Last_submission_time'])
pd.set_option('display.width', 1000)
pd.set_option('display.max_rows', None)
print(df[['Nowcoder_ID','Level','Last_submission_time']])
运行结果:

《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等

