指针和数组笔试题解析
目录
一、基本定义
二、一维整型数组
三、字符串数组
四、二维数组
五、指针面试题
一、基本定义
做题之前我们要首先了解
数组的意义:
1. 特殊情况一:sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
2. 特殊情况二:&数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
3. 除此之外所有的数组名都表示首元素的地址。
sizeof的定义:
sizeof是C语言的一种单目操作符,如C语言的其他操作符++、--等。sizeof操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
strlen的定义:
strlen是C语言标准函数库中的标准函数,其功能是:计算字符串的长度,strlen所作的仅仅是一个计数器的工作,它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符'\0'为止,然后返回计数器值(长度不包含'\0')。
二、一维整型数组
// 一维数组int a [] = { 1 , 2 , 3 , 4 };printf ( "%d\n" , sizeof ( a )); // 16第一种特殊情况:sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。数组类型为:int [4],表示数组存储了4个int类型的值-->4*4 = 16个字节。printf ( "%d\n" , sizeof ( a + 0 )); // 4/8数组名表示首元素的地址,+0还是表示首元素的地址,地址的大小为4/8个字节printf ( "%d\n" , sizeof ( * a )); // 4a表示首元素地址,*a表示首元素地址解引用,为首元素1,类型为int,占4个字节.printf ( "%d\n" , sizeof ( a + 1 )); // 4/8a表示首元素地址,+1之后表示第二个元素的地址,地址的大小占4/8个字节.printf ( "%d\n" , sizeof ( a [ 1 ])); //4a[1]表示访问第二个元素,与*(a+1)表示的含义相同,第二个元素为2,类型为int,整型在内存中占4个字节,结果为4printf ( "%d\n" , sizeof ( & a )); //4/8第二种特殊情况:&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,只要是地址,所占的内存就为4/8字节.printf ( "%d\n" , sizeof ( *& a )); //16*&a-->a,则为sizeof(a),这里的数组名表示整个数组,计算的是整个数组的大小,为16个字节&a -- > int (*)[4], *&a -- > *(int (*)[4]) ,占16个字节printf ( "%d\n" , sizeof ( & a + 1 )); //4/8&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&a+1则表示跳过了整个数组,如下图所示,&a+1指向的是最后一个元素之后的地址,地址的大小为4/8字节printf ( "%d\n" , sizeof ( & a [ 0 ])); //4/8a[0]表示数组首元素,&a[0]表示数组首元素的地址,地址的大小为4/8字节printf ( "%d\n" , sizeof ( & a [ 0 ] + 1 )); //4/8&a[0]表示数组首元素的地址,&a[0]+1表示数组第二个元素的地址,地址大小为4/8字节代码运行结果:
x64: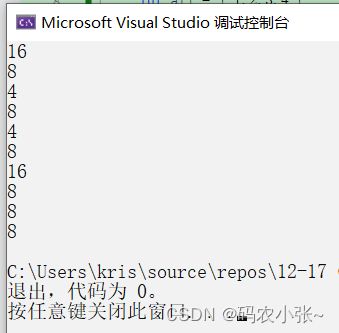 x86(32位计算机):
x86(32位计算机):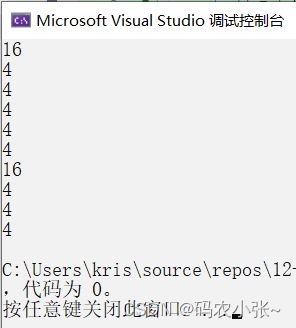
三、字符串数组
char arr [] = { 'a' , 'b' , 'c' , 'd' , 'e' , 'f' };printf ( "%d\n" , sizeof ( arr )); //6第一种特殊情况:sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,该数组类型为char [6],表示数组存储了6个char类型的数据--->6*1=6个字节。printf ( "%d\n" , sizeof ( arr + 0 )); //4/8arr表示数组首元素的地址,arr+0还是表示数组首元素的地址,地址的大小为4/8个字节。printf ( "%d\n" , sizeof ( * arr )); //1arr表示首元素地址,*arr表示首元素地址解引用,为首元素‘a’,类型为char,占1个字节.printf ( "%d\n" , sizeof ( arr [ 1 ])); //1arr[1]表示访问第二个元素,与*(a+1)表示的含义相同,第二个元素为'b', 类型为char,占1个字节.printf ( "%d\n" , sizeof ( & arr )); //4/8第二种特殊情况:&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,只要是地址,所占的内存就为4/8字节.printf ( "%d\n" , sizeof ( & arr + 1 )); //4/8&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&arr+1则表示跳过了整个数组,如下图所示,&arr+1指向的是最后一个元素之后的地址,地址的大小为4/8字节printf ( "%d\n" , sizeof ( & arr [ 0 ] + 1 )); //4/8&arr[0]表示数组首元素的地址,&arr[0]+1表示数组第二个元素的地址,地址所占大小为4/8字节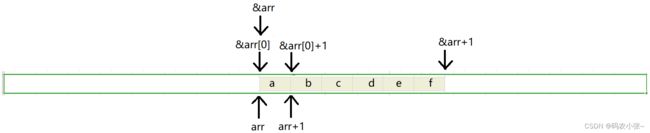 代码运行结果:x64:
代码运行结果:x64: x86(32位计算机):
x86(32位计算机):
strlen是一个计数器,它从内存的某个位置开始扫描,直到碰到第一个字符串结束符'\0'为止,然后返回计数器值(长度不包含'\0')。char arr [] = { 'a' , 'b' , 'c' , 'd' , 'e' , 'f' };printf ( "%d\n" , strlen ( arr )); //随机值数组名为数组首元素的地址,由于字符串arr中没有‘\0’,所以求长度时会从数组首元素一直往后找,直到找到‘\0’为止,又因为产生的结构为随机值,所以从数组首元素到‘\0’的元素的个数也为随机值。printf ( "%d\n" , strlen ( arr + 0 )); //随机值数组名为数组首元素的地址,arr+0之后也为数组首元素的地址,字符串arr中没有‘\0’,所以从数组首元素到‘\0’的元素的个数为随机值。printf ( "%d\n" , strlen ( * arr )); //报错*arr表示数组首元素‘a’,strlen()函数传递的参数应该为一个地址,当我们传递的为‘a’时,‘a’的ASCII码值为97,将97作为地址传参,strlen()就会从97这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。printf ( "%d\n" , strlen ( arr [ 1 ])); //报错arr[1]表示数组首元素‘b’,‘b’的ASCII码值为98,将98作为地址传参,strlen()就会从98这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。printf ( "%d\n" , strlen ( & arr )); //随机值&数组名,这里的数组名表示整个数组,为char(*)[6],取出的是整个数组的地址,数组地址和首元素地址是相同的,那么将数组地址传递给strlen()函数之后,依然从数组第一个元素开始向后统计,结果为一个随机值。printf ( "%d\n" , strlen ( & arr + 1 )); //随机值&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&arr+1则表示跳过了整个数组,如下图所示,&arr+1指向的是最后一个元素之后的地址,将&arr+1作为参数传递给strlen函数,表示从最后一个元素之后开始向后统计,结果为一个随机值。printf ( "%d\n" , strlen ( & arr [ 0 ] + 1 )); //随机值&arr[0]表示数组首元素的地址,&arr[0]+1表示数组第二个元素的地址,将&arr[0]+1作为参数传递给strlen函数,表示从 第二个元素开始向后统计,结果为一个随机值,比从首元素开始统计的值少1。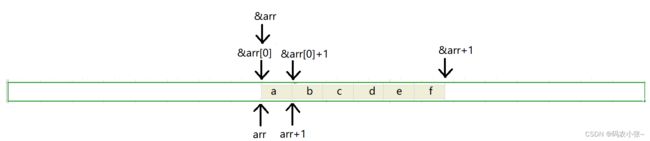 代码运行结果:
代码运行结果:(省略了两个报错的结果)
char arr [] = "abcdef" ;printf ( "%d\n" , sizeof ( arr )); //7第一种特殊情况:sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,该数组类型为char [7](包含‘\0’),表示数组存储了7个char类型的数据--->7*1=7个字节。printf ( "%d\n" , sizeof ( arr + 0 )); //4/8arr表示数组首元素的地址,arr+0还是表示数组首元素的地址,地址的大小为4/8个字节。printf ( "%d\n" , sizeof ( * arr )); //1arr表示首元素地址,*arr表示首元素地址解引用,为首元素‘a’,类型为char,占1个字节.printf ( "%d\n" , sizeof ( arr [ 1 ])); //1arr[1]表示访问第二个元素,与*(a+1)表示的含义相同,第二个元素为'b', 类型为char,占1个字节.printf ( "%d\n" , sizeof ( & arr )); //4/8第二种特殊情况:&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,只要是地址,所占的内存就为4/8字节.printf ( "%d\n" , sizeof ( & arr + 1 )); //4/8&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&arr+1则表示跳过了整个数组,如下图所示,&arr+1指向的是最后一个元素之后的地址,地址的大小为4/8字节printf ( "%d\n" , sizeof ( & arr [ 0 ] + 1 )); //4/8&arr[0]表示数组首元素的地址,&arr[0]+1表示数组第二个元素的地址,地址所占大小为4/8字节 代码运行结果:x64:
代码运行结果:x64: x86(32位计算机):
x86(32位计算机):
char arr [] = "abcdef" ;(字符串最后的元素以\0作为结尾)printf ( "%d\n" , strlen ( arr )); //6数组名为数组首元素的地址,所以求长度时会从数组首元素一直往后找,直到找到‘\0’为止,字符串最后隐含‘\0’,所以从数组首元素到‘\0’的元素的个数为6。printf ( "%d\n" , strlen ( arr + 0 )); //6arr + 0为数组首元素的地址,从数组首元素一直往后找,直到找到‘\0’为止,从数组首元素到‘\0’的元素的个数为6。printf ( "%d\n" , strlen ( * arr )); //err*arr表示数组首元素‘a’,strlen()函数传递的参数应该为一个地址,当我们传递的为‘a’时,‘a’的ASCII码值为97,将97作为地址传参,strlen()就会从97这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。printf ( "%d\n" , strlen ( arr [ 1 ])); //errarr[1]表示数组首元素‘b’,‘b’的ASCII码值为98,将98作为地址传参,strlen()就会从98这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。printf ( "%d\n" , strlen ( & arr )); //6&数组名,这里的数组名表示整个数组的地址,为char(*)[7],取出的是整个数组的地址,数组地址和首元素地址是相同的,那么将数组地址传递给strlen()函数之后,依然从数组第一个元素开始向后统计,结果为6.printf ( "%d\n" , strlen ( & arr + 1 )); //随机值&数组名,这里的数组名表示整个数组的地址,取出的是整个数组的地址,&arr+1则表示跳过了整个数组,如下图所示,&arr+1指向的是最后一个元素之后的地址,将&arr+1作为参数传递给strlen函数,表示从最后一个元素之后开始向后统计,结果为一个随机值。printf ( "%d\n" , strlen ( & arr [ 0 ] + 1 )); //5&arr[0]表示数组首元素的地址,&arr[0]+1表示数组第二个元素的地址,将&arr[0]+1作为参数传递给strlen函数,表示从 第二个元素开始向后统计,结果为5,比从首元素开始统计的值少1。代码运行结果:
(省略了两个报错的结果)
char * p = "abcdef" ;(这里的指针p中存放的是字符串首元素‘a’的地址)printf ( "%d\n" , sizeof ( p )); //4/8p是一个指针变量, 指针p中存放的是字符串首元素‘a’的地址,指针变量大大小为4/8printf ( "%d\n" , sizeof ( p + 1 )); //4/8p是一个指针变量, 指针p中存放的是字符串首元素‘a’的地址,则p+1表示第二个元素‘b’的地址,指针变量大小为4/8字节printf ( "%d\n" , sizeof ( * p )); //1指针p中存放的是字符串首元素‘a’的地址,*p表示取出首元素,首元素为‘a’,首元素的类型为char。大小为1字节。printf ( "%d\n" , sizeof ( p [ 0 ])); //1指针p中存放的是字符串首元素‘a’的地址 ,p [0]表示访问首元素,与*(p+0)表示的含义相同,首元素为‘a’, 类型为char,占1个字节.printf ( "%d\n" , sizeof ( & p )); //4/8&p表示取出p的地址,类型为char **,只要是地址,所占大小为4/8字节printf ( "%d\n" , sizeof ( & p + 1 )); //4/8&p表示取出p的地址,&p+1表示跳过char *对象(p),如下图所示,地址所占大小为4/8字节。printf ( "%d\n" , sizeof ( & p [ 0 ] + 1 )); //4/8p [0]表示访问首元素,&p[0]表示取出首元素的地址,&p[0]+1表示首元素的地址+1,加上一个char *类型,结果表示取出第二个元素‘b’的地址,地址所占大小为4/8字节 代码运行结果:x64:
代码运行结果:x64: x86(32位计算机):
x86(32位计算机):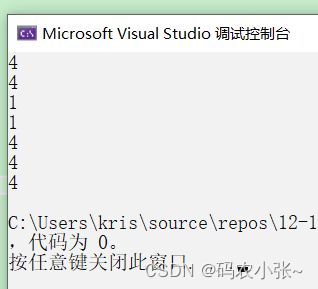
char * p = "abcdef" ;(这里的指针p中存放的是字符串首元素‘a’的地址) printf ( "%d\n" , strlen ( p )); //6指针p中存放的是字符串首元素‘a’的地址,所以求长度时会从数组首元素一直往后找,直到找到‘\0’为止,字符串最后隐含‘\0’,所以从数组首元素到‘\0’的元素的个数为6。printf ( "%d\n" , strlen ( p + 1 )); //5p+1表示第二个元素‘b’的地址,从数组第二个元素一直往后找,直到找到‘\0’为止,从数组第二个元素到‘\0’的元素的个数为5,比从首元素开始统计的值少1。printf ( "%d\n" , strlen ( * p )); //err*p表示取出首元素,首元素为‘a’, strlen()函数传递的参数应该为一个地址,当我们传递的为‘a’时,‘a’的ASCII码值为97,将97作为地址传参,strlen()就会从97这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。
printf ( "%d\n" , strlen ( p [ 0 ])); //errp [0]表示访问首元素,与*(p+0)表示的含义相同,首元素为‘a’,strlen()函数传递的参数应该为一个地址,当我们传递的为‘a’时,‘a’的ASCII码值为97,将97作为地址传参,strlen()就会从97这个地址开始统计字符串的长度,这就是非法访问内存了,编译器会报错。printf ( "%d\n" , strlen ( & p )); //随机值&p表示取出p的地址,从p的地址开始向后数,直到找到‘\0’为止,又因为产生的结构为随机值,所以从数组首元素到‘\0’的元素的个数也为随机值。printf ( "%d\n" , strlen ( & p + 1 )); //随机值&p表示取出p的地址,&p+1表示跳过char *对象(p),如下图所示,从该地址开始向后数,直到找到‘\0’为止,又因为产生的结构为随机值,所以从数组首元素到‘\0’的元素的个数也为随机值。printf ( "%d\n" , strlen ( & p [ 0 ] + 1 )); //5&p[0]+1表示 取出第二个元素‘b’的地址,从数组第二个元素一直往后找,直到找到‘\0’为止,从数组第二个元素到‘\0’的元素的个数为5,比从首元素开始统计的值少1。
代码运行结果:
(省略了两个报错的结果)
四、二维数组
int a [ 3 ][ 4 ] = { 0 };printf ( "%d\n" , sizeof ( a )); //48第一种特殊情况:sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,该数组类型为int [3][4],表示数组存储了3行7列个int类型的数据--->3*4*4=48个字节。printf ( "%d\n" , sizeof ( a [ 0 ][ 0 ])); //4a[0][0]表示访问第一行第一列元素,该元素类型为int,占4个字节。printf ( "%d\n" , sizeof ( a [ 0 ])); //16a[0]作为第一行一维数组数组名,表示第一行一维数组首元素的地址。特殊情况一:单独放在sizeof操作符中,a[0]表示第一行整个一维数组,计算的是整个一维数组的大小,类型为int [4],表示该一维数组存储了4个int类型的数据--->4*4 = 16个字节。printf ( "%d\n" , sizeof ( a [ 0 ] + 1 )); //4/8a[0]作为第一行一维数组数组名,没有单独放在sizeof中,也没有&,所以表示第一行一维数组首元素的地址,也就是a[0][0]的地址,a[0]+1则表示a[0][1]的地址,为4/8个字节。printf ( "%d\n" , sizeof ( * ( a [ 0 ] + 1 ))); //4a[0]+1表示a[0][1]的地址, * ( a [ 0 ] + 1 ) 则表示访问a[0][1]的数据,该数据的类型为int,占4个字节的大小。printf ( "%d\n" , sizeof ( a + 1 )); //4/8a表示二维数组首元素的地址,则为第一行一维数组的地址,a+1就是第二行一维数组的地址,地址大小为4/8个字节。printf ( "%d\n" , sizeof ( * ( a + 1 ))); //16a+1表示第二行一维数组的地址,类型为int(*)[4], * ( a + 1 )表示访问第二行一维数组, 计算的是整个一维数组的大小,类型为int [4],表示该一维数组存储了4个int类型的数据--->4*4 = 16个字节;*(a+1) --> a[1] --> 第二行数组 --> sizeof(a[1]),为16个字节;printf ( "%d\n" , sizeof ( & a [ 0 ] + 1 )); //4/8a[0]作为第一行一维数组数组名,表示第一行一维数组首元素的地址。特殊情况一:&数组名,这里的数组名表示整个数组,取出的是 第一行整个一维数组的地址, & a [ 0 ] + 1取出的是 第二行整个一维数组的地址,地址的大小为4/8.printf ( "%d\n" , sizeof ( * ( & a [ 0 ] + 1 ))); //16& a [ 0 ] + 1取出的是 第二行整个一维数组的地址, * ( & a [ 0 ] + 1 )表示访问 第二行一维数组,计算的是整个一维数组的大小,类型为int [4],表示该一维数组存储了4个int类型的数据--->4*4 = 16个字节;printf ( "%d\n" , sizeof ( * a )); //16a表示二维数组首元素的地址,则为第一行一维数组的地址,*a表示访问第一行一维数组,*a--> *(a+0) --> a[0],计算的是一维数组的大小,4*4 = 16个字节;printf ( "%d\n" , sizeof ( a [ 3 ])); //16a[3]表示访问数组第四行一维数组,发生越界访问,但是由于sizeof操作符计算的是操作符大小只由操作数的类型决定,a[3]类型为int [4],4*4 = 16个字节; 代码运行结果:x64:
代码运行结果:x64: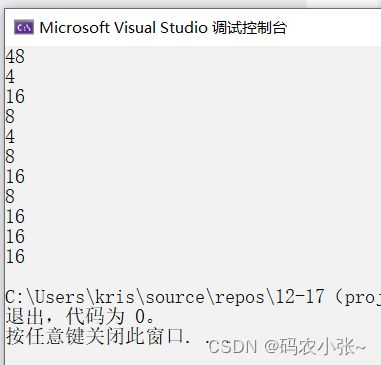 x86(32位计算机):
x86(32位计算机):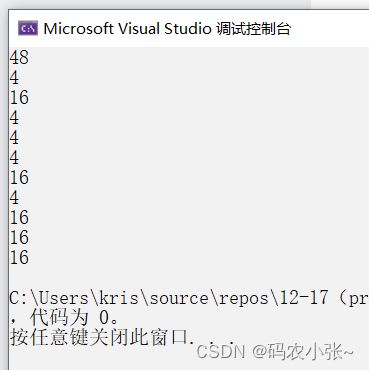
五、指针面试题
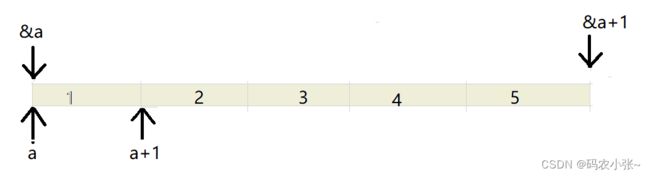
笔试题 1 :int main (){int a [ 5 ] = { 1 , 2 , 3 , 4 , 5 };int * ptr = ( int * )( & a + 1 );printf ( "%d,%d" , * ( a + 1 ), * ( ptr - 1 ));return 0 ;}// 程序的结果是什么?
a表示数组首元素的地址,*(a+1)表示取出第二个元素,为2;
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&a+1则表示跳过了整个数组,如下图所示,&a+1指向的是最后一个元素之后的地址,ptr存放的是最后一个元素之后的地址,*(ptr-1)则表示取出最后一个元素为5.
 代码运行结果:
代码运行结果:
笔试题 2:struct Test{int Num ;char * pcName ;short sDate ;char cha [ 2 ];short sBa [ 4 ];} * p= 0x100000 ;// 假设 p 的值为 0x100000 。 如下表表达式的值分别为多少?// 已知,结构体 Test 类型的变量大小是 20 个字节int main (){printf ( "%p\n" , p + 0x1 );printf ( "%p\n" , ( unsigned long ) p + 0x1 );printf ( "%p\n" , ( unsigned int* ) p + 0x1 );return 0 ;}
p + 0x1:
p的类型为(struct Test *),+1之后表示p的值加上一个(struct Test )所占的字节大小,结构体的大小为20字节,20的十六进制值为14,所以结果,00 10 00 14;
(unsigned long)p + 0x1:
表示将p强转为整型,变为一个整型,加上1之后为00 10 00 01;
(unsigned int*)p + 0x1:
表示将p强转为整型指针,指针加1表示加上一个指针类型所占大小,又因为p的类型为(int*),所以p+1表示跳过4个字节,结果为00100004
代码运行结果:

笔试题3:
int main (){int a [ 4 ] = { 1 , 2 , 3 , 4 };int * ptr1 = ( int * )( & a + 1 );int * ptr2 = ( int * )(( int ) a + 1 );printf ( "%x,%x" , ptr1 [ - 1 ], * ptr2 );return 0 ;}
&a+1表示跳过整个数组之后的地址,所以ptr指针变量中存储最后一个元素之后的地址,ptr[-1]---> *(ptr-1)表示访问最后一个元素的数据,结果为4;
(int)a+1表示将a强转为整型,再加一之后的值如下图所示,假设(int)a的值为0x 00 12 ff 40,那么加一之后则变为0x 00 12 ff 41,int *ptr2 = (int *)((int)a + 1);表示再将该值转换为地址存入ptr2中,*ptr表示从0x0012ff41位置开始读取,ptr类型为(int *),一次读取4字节,当小端存储时,低地址存放地位,实际值为0x02 00 00 00,结果为2000000.


笔试题4:
#include
数组表示应使用{ },题目中使用(,)为逗号表达式,取最右侧的值为结果,实际数组存储的值如下图所示,a[0]作为第一行一维数组数组名表示第一行一维数组首元素的地址,也就是a[0][0]的地址,求p[0]等价于*(p+0)等价于*p,*p表示访问a[0][0]的数据。

笔试题5
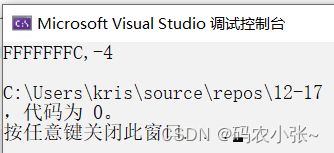
int main (){int a [ 5 ][ 5 ];int ( * p )[ 4 ];p = a ;printf ( "%p,%d\n" , & p [ 4 ][ 2 ] - & a [ 4 ][ 2 ], & p [ 4 ][ 2 ] - & a [ 4 ][ 2 ]);return 0 ;}
&p[4][2]和&a[4][2]的位置如下图所示,指针减指针得到的是个数为-4,所以%d打印结果-4,;%p打印的是地址,由于在计算机存储的是补码,-4的补码为11111111 11111111 11111111 11111100,转换为16进制为ff ff ff fc,%p打印的值为ff ff ff fc.

笔试题6
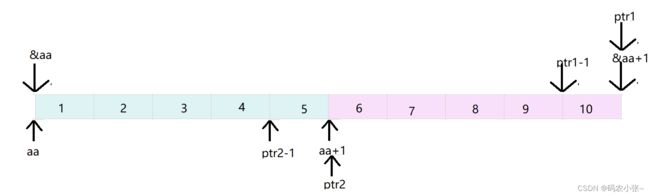
int main (){int aa [ 2 ][ 5 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 };int * ptr1 = ( int * )( & aa + 1 );int * ptr2 = ( int * )( * ( aa + 1 ));printf ( "%d,%d" , * ( ptr1 - 1 ), * ( ptr2 - 1 ));return 0 ;}
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址,&aa+1表示跳过整个数组之后的地址,*(ptr-1)表示访问最后一个元素;
aa表示二维数组首元素的地址,则为第一行一维数组的地址,aa+1就是第二行一维数组的地址。*(aa+1) --> aa[1] --> &aa[1][0],ptr中存储第二行数组首元素的地址,*(ptr2-1)则表示访问上一行最后一个元素。
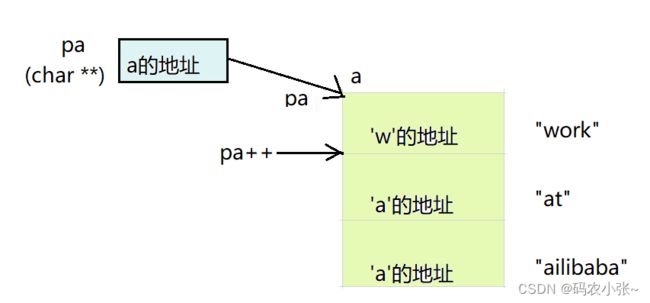
笔试题 7#include
指针数组中元素指向的是字符串的首地址,pa指向的是a的地址,pa++指向的是指针数组的第二个元素,*pa表示访问第二个元素,第二个元素存储的是‘a’首地址,打印之后可以得到“at”。