心脏病数据集(入门级)
一、数据准备
首先导入需要的库:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt然后导入数据集,我用的是非常典型的一个心脏病数据集(数据来自Kaggle),如下图: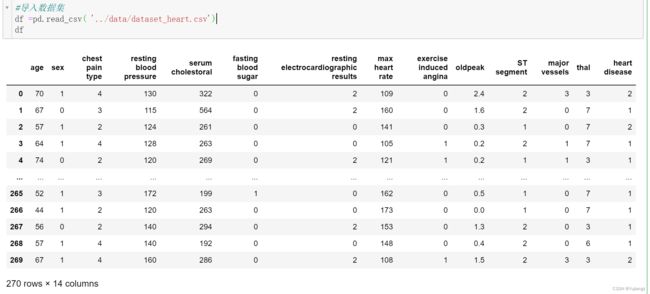 为了解更多数据集的数据类型,最值等特征:
为了解更多数据集的数据类型,最值等特征:
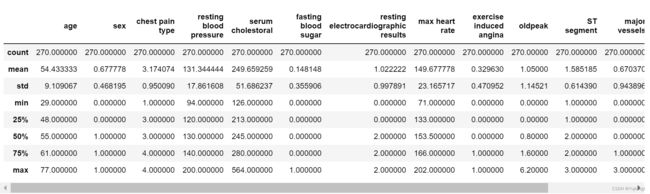
df.info()df.describe()输出如下:
二、数据清洗
判断是否有重复值、缺失值、异常值
(一)重复值
#重复值判断
df.duplicated()我们得到的是布尔值(每行一个)中间一般不会展示完,所以要确定是否有行重复,或者要得到重复值的行数,需要用value.counts( ):
df.duplicated().value_counts() 输出如下,可以看到没有行重复:![]()
(二)缺失值
#缺失值判断
df.isnull()同样输出有省略的布尔值,为全面看到每列是否存在缺失和缺失个数,调用函数:
df.isnull().any()
df.isnull().sum()输出如下,可以看到没有缺失值:


为了处理缺失值,我构造了新的一列全是空值,然后对第一个进行赋值,得到的新的数据集打印如下: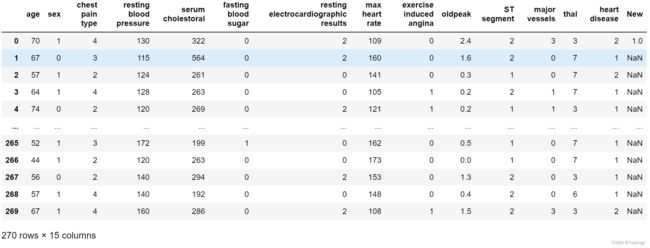
这个时候,我们已经发现new列99%都是空值,就可以直接删除,这里how='any'指的是只要出现一个缺失值就删除,axis=1指的是按照列的顺序,inplace=True是指在原数据上直接修改并保存:
#.dropna()删除
df.dropna(how='any', axis=1, inplace=True)上一步也可以在缺失值处用均值,中位数,指定数据等进行填充:
#df1 = df.fillna(df.mean())
#df1 = df.fillna(1)(三)异常值
我先用了箱线图法,后面发现有部分异常点我无法判断是心脏病患者的特诊,还是不符合常识的异常情况,所以我选择直接观察(在没有掌握另外几种异常值检测方法的情况下),顾名思义,直接观察数据集的特征,这里就不赘述了。
三、数据可视化处理
(一)探索变量之间的相关性
#heatmap
plt.figure(figsize=(12,10))
#单色系/冷暖色
#corr()
sns.heatmap(df.corr(),annot=True, square=True,fmt='.2f',cmap='coolwarm')
plt.show() (二)探索患病情况和患病比例
(二)探索患病情况和患病比例
#显示字体
plt.rcParams['font.sans-serif']=['SimHei']
fig = plt.figure(figsize=(10, 4))
ax1 = fig.add_subplot(1, 2, 1)
#bar chart
#value.counts()
ax1 = sns.barplot(x=df['heart disease'], y=df['heart disease'].value_counts())
plt.title('Disease Rate', fontsize=14)
plt.xlabel('type\n (1=Disease-free, 2=Diseased)')
plt.ylabel('number')
#pie chart
ax2 = fig.add_subplot(1, 2, 2)
ax2.pie(df['heart disease'].value_counts(), labels=df['heart disease'].value_counts().index, autopct='%1.1f%%',
shadow=True, startangle=90)
plt.title('Pie Chart Of Disease Rate')
plt.show()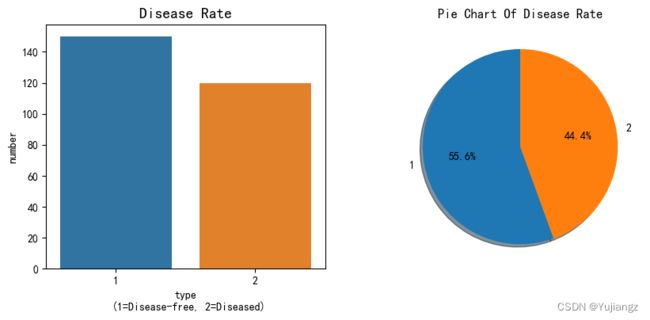 (三)查看样本的年龄分布
(三)查看样本的年龄分布
#barchart
df['age'].value_counts()
sns.barplot(x=df['age'].value_counts().index,y=df['age'].value_counts().values)
plt.xlabel('Age')
plt.ylabel('Number')
plt.title('Age Distribution')
#调整x轴上的标签距离
plt.xticks(rotation=45, ha='right')
plt.show()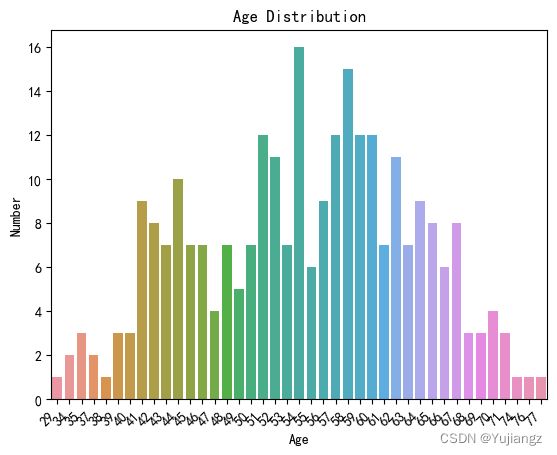
(四)探索max heart rate(达到的最大心率),年龄和是否患病三者之间的关系
sns.scatterplot(x=df.age[df['heart disease']==1], y=df['max heart rate'][df['heart disease'] == 1], color="red")
sns.scatterplot(x=df.age[df['heart disease']==2], y=df['max heart rate'][df['heart disease'] == 2], color="green")
plt.legend(["Diseased", "Disease-free"])
plt.title('the change of max heart rate with difference of age and deisease')
plt.xlabel('Age')
plt.ylabel('max heart rate')
plt.show()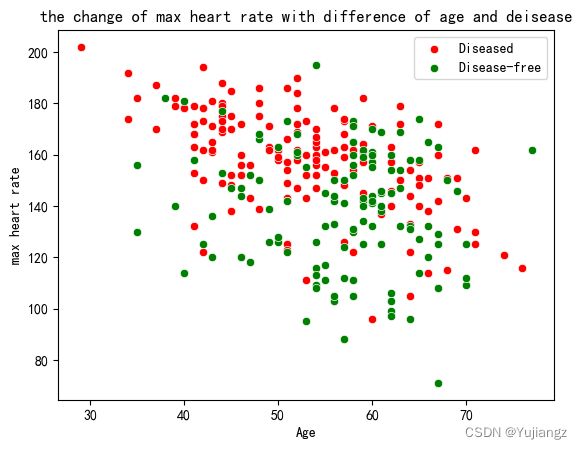
(五)四种疼痛类型的占比
fig, ax = plt.subplots(figsize=(10, 4))
#pie chart
ax.pie(df['chest pain type'].value_counts(), labels=df['chest pain type'].value_counts().index, autopct='%1.1f%%',
shadow=True, startangle=90)
plt.title('Pie Chart')
plt.show()
四、一些自问自答
Q1: 中年心脏病人哪种胸痛类型更多?
#创建空new_disDf
new_distDf = pd.DataFrame()
#转换数据类型
df['age'] = df['age'].astype(int)
# 用pd.cut() 将年龄进行分割
new_distDf['age_range'] = pd.cut(x = df['age'],
bins = [0,16,30,60,100],
include_lowest = True, right=False,
labels = ['Children','Youth','Middle-aged','Elderly'])
# 将原数据集的age合并到age_distDf中
new_distDf = pd.concat([new_distDf['age_range'], df['heart disease'], df['chest pain type']], axis=1)
new_distDf
#选取middle-aged
new_distDf[new_distDf['age_range']=='Middle-aged']
sns.countplot(data=new_distDf,x='chest pain type',hue='heart disease',palette='Set2')
plt.xlabel('胸痛类型\n(1.0=没有症状, 2.0=非典型心绞痛;3.0=非心绞痛,4.0=典型心绞痛')
plt.show()
 Q2: 心脏病对荧光染色的主要血管数有什么影响?
Q2: 心脏病对荧光染色的主要血管数有什么影响?
sns.countplot(data=df, x='major vessels', hue='heart disease')
plt.xlabel('major vessels\n荧光染色的主要血管数(0~3)')
plt.ylabel('Count')
plt.show()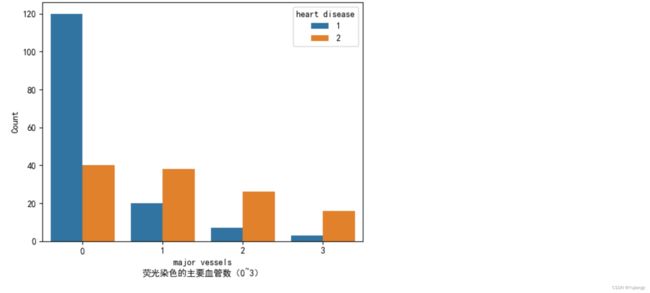 Q3: 病人和普通人的静息血压最值,中位值的区别?
Q3: 病人和普通人的静息血压最值,中位值的区别?
df['heart disease'].replace({1: 'disease-free', 2: 'diseased'}, inplace=True)
sns.boxplot(x=df['heart disease'], y=df['resting blood pressure'])
plt.title("静息血压")
plt.ylabel("数值")
plt.show()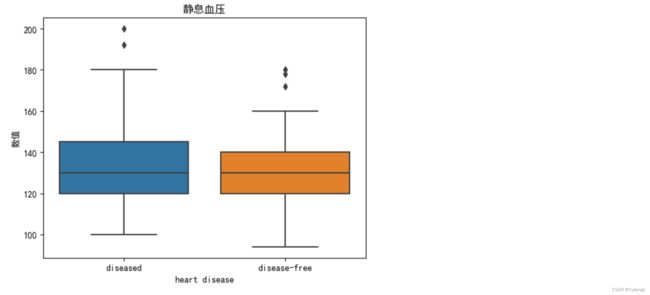 Q4: 达到最大心率,运动峰值ST段的斜率和是否患病三者之间的关系?
Q4: 达到最大心率,运动峰值ST段的斜率和是否患病三者之间的关系?
plt.figure(figsize=(15,5))
#散点图
sns.swarmplot(x=df['ST segment'], y=df['max heart rate'], hue=df['heart disease'], palette='viridis')
plt.xlabel('运动峰值ST段的斜率')
plt.ylabel('达到最大心率')
plt.show() Q5: 不同性别的患者比例?
Q5: 不同性别的患者比例?
fig, ax = plt.subplots(figsize=(10, 4))
ax.pie(df['sex'].value_counts(), labels=df['sex'].value_counts().index, autopct='%1.1f%%',
shadow=True, startangle=90)
plt.title('Pie Chart Of Sex Rate\n (0:女性,1:男性)')
plt.show()
五、模型预测(新手版)
先导入构造随机森林进行数据预测需要的库:
from sklearn.ensemble import RandomForestClassifier # bagging的随机森林
from sklearn.tree import DecisionTreeClassifier # 决策树模型
from sklearn.model_selection import train_test_split # 训练集划分
from sklearn import tree
from sklearn.metrics import accuracy_score#切分训练集和测试集
#random_state:确保每次运行时算法基于相同的随机数种子生成结果
x_train, x_test, y_train, y_test = train_test_split(df.drop(labels='heart disease', axis=1), df['heart disease'], test_size=0.2, random_state=10)
#建立模型
model = RandomForestClassifier(max_depth= 5)
#用训练数据训练模型
#fit()
model = model.fit(x_train,y_train)
feature_names = [i for i in x_train.columns]
feature_names
#转换数据类型为string
y_train_str = y_train.astype('str')
y_train_str[y_train_str == '1'] = 'no disease'
y_train_str[y_train_str == '2'] = 'disease'
#将series转化为nump数组
y_train_str = y_train_str.values
y_train_str[:5]
arr=df.values.astype(np.float32)
arr
score = model.score(x_test,y_test)
score
到这里就已经初步建立好模型,进行了训练集训练, 接下来对测试集进行模拟:
#使用训练好的模型进行预测
predictions = model.predict(x_test)
predictions这里尤其注意最后进行accuracy准确度测试的时候要求两者形式一样,需要调整统一形式:
#调整predictions 和 y_test 的格式问题
str_predictions = np.where(predictions == 1, 'no disease', 'disease')
str_predictions[str_predictions == 1] = 'no disease'
str_predictions[str_predictions == 2] = 'disease'
str_predictions
y_test
y_test.to_numpy() 准确率是评估模型性能的重要指标之一,但仅凭准确率不能完整地判断模型的吻合程度。通过综合考虑准确率、精确率、召回率、F1 分数等评估指标,可以更全面地评估模型的性能和泛化能力。
准确率是评估模型性能的重要指标之一,但仅凭准确率不能完整地判断模型的吻合程度。通过综合考虑准确率、精确率、召回率、F1 分数等评估指标,可以更全面地评估模型的性能和泛化能力。
六、参考资料
机器学习:心脏病分类预测(基于python) - 知乎 (zhihu.com)
基于Kaggle心脏病数据集的数据分析和分类预测-StatisticalLearning统计学习实验报告_中科豆的博客-CSDN博客
数据分析实战:利用python对心脏病数据集进行分析 - 知乎 (zhihu.com)
(35条消息) 机器学习项目实战:基于随机森林进行心脏病分类(含多种模型解释方法)_Weiyaner的博客-CSDN博客
五分钟速通随机森林(附实战案例与数据集) - 知乎 (zhihu.com)
感谢!