K8s 之 kube-scheduler 源码学习
主要分为四个模块
- 本地部署
- 简介
- 整体架构
- 源码解析
1. 本地部署
-
windows环境需要先安装一个Docker Desktop 下载地址 : https://hub.docker.com/search?type=edition&offering=community
-
下载的版本要和自己本地的k8s源码版本一致.
-
Docker Desktop安装好了, 从阿里云镜像服务下载 Kubernetes 所需要的镜像, 在Windows上,使用 PowerShell 执行:
.\load_images.ps1在Windows上:
如果在Kubernetes部署的过程中出现问题,可以在 C:\ProgramData\DockerDesktop下的service.txt 查看Docker日志, 在 C:\Users\yourUserName\AppData\Local\Docker下的log.txt 查看Kubernetes日志
-
验证 Kubernetes 集群状态
kubectl cluster-info kubectl get nodes -
部署 Kubernetes dashboard
$ kubectl apply -f kubernetes-dashboard.yaml -
配置控制台令牌token
$TOKEN=((kubectl -n kube-system describe secret default | Select-String "token:") -split " +")[1] kubectl config set-credentials docker-for-desktop --token="${TOKEN}" echo $TOKEN这是我的token
eyJhbGciOiJSUzI1NiIsImtpZCI6ImNIZFFSbGl2OFB0Vkt6b20yVFFtOUhCZ1BnT2dQUnFXZkUtZUhSU0JPLVEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkZWZhdWx0LXRva2VuLXZkeGZ6Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImRlZmF1bHQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI3ZGE1ZDM0Zi1kODAzLTQwYTEtODBjNy02ZDk4OWM3ZDIyY2YiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06ZGVmYXVsdCJ9.DflbMdlV5_Wio0CQQjfmnpNJ527tVd2sLVDuuaTXY-djnexKu6_qCfwCovt8CxQdcg5_yPyCxZE_Rk5ep41j9jqAhztwmXTPEJ0cP85Uqm0hEGQCSQUM4MxDbPLw2a5aDwQ8EnNaUNZT4JvFiQBGGFESenUFGx21jpiXtwcwuY7VGlOSSpdB2ia9usx2lJSryMYel0VZ3gyfSnJds7S3LoSULXlsg5ullgNvpxLNxKp6vwywFu90E6o61_8u3FSTFv5eGJGOGrxaI95lZbw2tdll-1Ri_mGkt9rH1X8jS_9U5QFf1HSOQjyKWUQof4q9KibDfpAxinA7Onjgyp_Blw通过如下 URL 访问 Kubernetes dashboard
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ -
开启 API Server 访问代理
kubectl proxy -
先启动本地的kube-scheduler, 支持各种命令行参数, 具体可以参考 :
https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-scheduler/
--leader-elect=true --master=http://127.0.0.1:8001 --v=2启动完打印这行日志代表启动成功.
I0628 20:21:32.365087 3480 leaderelection.go:248] attempting to acquire leader lease kube-system/kube-scheduler... -
先杀掉docker容器里的kube-scheduler, 可能需要尝试多次. 打印下面这行日志代表选主成功
I0628 20:22:36.591608 3480 leaderelection.go:258] successfully acquired lease kube-system/kube-scheduler -
创建一个POD, 本地打印如下日志表示pod分配node成功
I0626 19:16:57.409348 10672 scheduler.go:648] "Successfully bound pod to node" pod="default/hello-world" node="docker-desktop" evaluatedNodes=1 feasibleNodes=1 -
如果申请一个超额的POD, 调度失败打印的日志 :
I0628 20:22:39.428003 3480 factory.go:337] "Unable to schedule pod; no fit; waiting" pod="default/nginx-deployment-77ccb5b6dd-dzvq5" err="0/1 nodes are available: 1 Insufficient cpu."
2. 简介
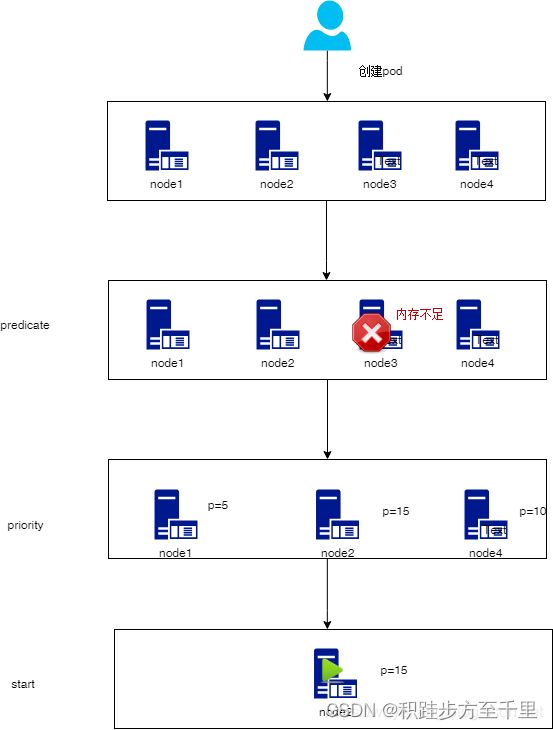
调度器通过 kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。 调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。 调度器会依据下文的调度原则来做出调度选择。
kube-scheduler 给一个 pod 做调度选择包含两个步骤:
- 过滤
- 打分
过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。 例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下, 这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。 如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
例子
3. 整体架构设计

scheduler工作流程:
- scheduler维护待调度的
podQueue并监听APIServer。 - 创建Pod时,我们首先通过APIServer将Pod元数据写入etcd。
- scheduler通过Informer监听Pod状态。添加新的Pod时,会将Pod添加到
podQueue。 - 主程序不断从
podQueue中提取Pods并按照一定的算法将节点分配给Pods。 - 节点上的kubelet也侦听ApiServer。如果发现有新的Pod已调度到该节点,则将通过CRI调用高级容器运行时来运行容器。
- 如果scheduler无法调度Pod,则如果启用了优先级和抢占功能,则首先进行抢占尝试,删除节点上具有低优先级的Pod,然后将要调度的Pod调度到该节点。如果未启用抢占或抢占尝试失败,则相关信息将记录在日志中,并且Pod将添加到
podQueue的末尾。

-
Framework的调度流程是分为两个阶段scheduling cycle和binding cycle. scheduling cycle是同步执行的.
-
同一个时间只有一个scheduling cycle,是线程安全的。
-
binding cycle是异步执行的,同一个时间中可能会有多个binding cycle在运行,是线程不安全的。
设计要点
-
无锁化
-
缓存加速调度
-
可配置化
-
可扩展
4.源码解析
本地运行调度
kubernetes 是一个集群管理平台, kubernetes需要统计整体平台的资源使用情况, 合理的将资源分配给容器使用, 并保证容器生命周期内有足够的资源来保证其运行. 同时, 如果资源发放是独占的, 对于空闲的容器来说占用这没有使用的资源是非常浪费的, 比如CPU。k8s需要考虑如何在优先度和公平性的前提下提供资源的利用率。
limit/request介绍
- 容器使用的最小资源需求, 作为容器调度时资源分配的判断依赖。
- 只有当前节点上可分配的资源量 >= request 时才允许将容器调度到该节点。
- request参数不限制容器的最大可使用资源
limit
- 容器能使用资源的最大值
- 设置为0表示对使用的资源不做限制, 可无限的使用
request 和 limit 关系
request能保证pod有足够的资源来运行, 而limit则是防止某个pod无限制的使用资源, 导致其他pod崩溃. 两者的关系必须满足:
0 <= request <= limit
如果limit=0表示不对资源进行限制, 这时可以小于request。
目前CPU支持设置request和limit,memory只支持设置request, limit必须强制等于request, 这样确保容器不会因为内存的使用量超过request但是没有超过limit的情况下被意外kill掉。
通过命令行创建:
kubectl run nginx --image=nginx --port=80
通过yaml文件创建
kubectl apply -f test-nginx.yaml
查看pod
kubectl get pods
删除pod
kubectl delete pod nginx
查看Pod状态 :
| Value | Description |
|---|---|
| Pending | 系统已经接受pod实例的创建,但其中所包含容器的一个或者多个image还没有创建成功 |
| Running | Pod已经被调度到某个node上,pod包含的所有容器已经创建完成,至少有一个容器正常运行或者处于启动与重启动过程。 |
| Succeeded | Pod中的所有容器正常终止,并且不会再次启动。 |
| Failed | Pod中所有容器已终止运行,至少有一个容器非正常结束,比如退出码非零,被系统强制杀死等。 |
| Unknow | 无法取得pod状态,一般是网络问题引起。 |
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx-deployment-77ccb5b6dd-dzvq5 | 0/1 | Pending | 0 | 3m38s |
kube-scheduler 启动流程
- 命令行参数解析 : NewSchedulerCommand
- 构造scheduler对象 : Setup(ctx, opts, registryOptions…) createFromConfig
- 加载默认的内置调度算法 : GetDefaultConfig
- 选举 : leaderelection.go
- 只有leader才会运行调度 : scheduleOne
kube-scheduler 选举机制
- etcd是整个集群所有状态信息的存储, 而apiserver作为集群入口,本身是无状态的web服务器,多个apiserver服务之间直接负载请求并不需要做选主。
- Controller-Manager和Scheduler作为控制类型的组件,多个kube-scheduler启动时先选举leader,只有 leader 的 schuduler 才会 调用run方法进入调度逻辑,而无需考虑它们之间的数据一致和同步。
- 基本原理其实就是利用通过调用apiServer 更新 endpoints 资源实现一个分布式锁,抢(acqure)到锁的节点成为leader,并且定期更新(renew)。其他进程也在不断的尝试进行抢占,抢占不到则继续等待下次循环。当leader节点挂掉之后,租约到期,其他节点就成为新的leader。
leaderelection.go
扩展点
(1) Queue sort
// QueueSortPlugin is an interface that must be implemented by "QueueSort" plugins.
// These plugins are used to sort pods in the scheduling queue. Only one queue sort
// plugin may be enabled at a time.
type QueueSortPlugin interface {
Plugin
// Less are used to sort pods in the scheduling queue.
Less(*PodInfo, *PodInfo) bool
}
Scheduler中的优先级队列是通过heap实现的,我们可以在QueueSortPlugin中定义heap的比较函数来决定的排序结构。但是需要注意的是heap的比较函数在同一时刻只有一个,所以QueueSort插件只能Enable一个,如果用户Enable了2个则调度器启动时会报错退出。下面是默认的比较函数,可供参考。
// Less is the function used by the activeQ heap algorithm to sort pods.
// It sorts pods based on their priority. When priorities are equal, it uses
// PodQueueInfo.timestamp.
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := pod.GetPodPriority(pInfo1.Pod)
p2 := pod.GetPodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
(2)PreFilter
PreFilter在scheduling cycle开始时就被调用,只有当所有的PreFilter插件都返回success时,才能进入下一个阶段,否则Pod将会被拒绝掉,标识此次调度流程失败。PreFilter类似于调度流程启动之前的预处理,可以对Pod的信息进行加工。同时PreFilter也可以进行一些预置条件的检查,去检查一些集群维度的条件,判断否满足pod的要求。
(3)Filter
Filter插件是scheduler v1版本中的Predicate的逻辑,用来过滤掉不满足Pod调度要求的节点。为了提升效率,Filter的执行顺序可以被配置,这样用户就可以将可以过滤掉大量节点的Filter策略放到前边执行,从而减少后边Filter策略执行的次数,例如我们可以把NodeSelector的Filter放到第一个,从而过滤掉大量的节点。Node节点执行Filter策略是并发执行的,所以在同一调度周期中多次调用过滤器。
Filter插件的功能如下:
-
NodePorts: 检查Pod请求的端口在Node是否可用; (NodePorts.go)
-
NodeLabel: 根据配置的标签过滤Node; (node_label.go)
-
NodeAffinity: 实现了Node选择器和节点亲和性
-
InterPodAffinity: 实现Pod之间的亲和性和反亲和性;
-
NodeName: 检查Pod指定的Node名称与当前Node是否匹配;
-
NodeResourcesFit: 检查Node是否拥有Pod请求的所有资源;
-
NodeUnscheduleable: 过滤Node.Spec.Unschedulable值为true的Node;
-
NodeVolumeLimits: 检查Node是否满足CSI卷限制;
-
PodTopologySpread: 实现Pod拓扑分布;
-
ServiceAffinity: 检查属于某个服务(Service)的Pod与配置的标签所定义的Node集合是否适配,这个插件还支持将属于某个服务的Pod分散到各个Node;
-
TaintToleration: 实现了污点和容忍度;
-
VolumeBinding: 检查Node是否有请求的卷,是否可以绑定请求的卷;
-
VolumeRestrictions: 检查挂载到Node上的卷是否满足卷Provider的限制;
-
VolumeZone: 检查请求的卷是否在任何区域都满足;
(4) PostFilter
新的PostFilter的接口定义在1.19的版本才发布,主要是用于处理当Pod在Filter阶段失败后的操作,例如抢占逻辑就是postFilter的一个实现.
PostFilterPlugin插件在过滤后调用,但仅在Pod没有满足需求的Node时调用。
抢占机制基本流程如下:
- 判断是否有关闭抢占机制,如果关闭抢占机制则直接返回。
- 获取调度失败pod的最新对象数据。
- 执行抢占算法
Algorithm.Preempt,返回预调度节点和需要被剔除的pod列表。 - 将抢占算法返回的node添加到pod的
Status.NominatedNodeName中,并删除需要被剔除的pod。 - 当抢占算法返回的node是nil的时候,清除pod的
Status.NominatedNodeName信息。
整个抢占流程的最终结果实际上是更新Pod.Status.NominatedNodeName属性的信息。如果抢占算法返回的节点不为空,则将该node更新到Pod.Status.NominatedNodeName中,否则就将Pod.Status.NominatedNodeName设置为空。
(5) PreScore
PreScore在之前版本称为PostFilter,现在修改为PreScore,主要用于在Score之前进行一些信息生成。此处会获取到通过Filter阶段的节点列表,我们也可以在此处进行一些信息预处理或者生成一些日志或者监控信息。
(6) Score
Scoring扩展点是scheduler v1版本中Priority的逻辑,目的是为了基于Filter过滤后的剩余节点,根据Scoring扩展点定义的策略挑选出最优的节点。
Scoring扩展点分为两个阶段:
- 打分:打分阶段会对Filter后的节点进行打分,scheduler会调用所配置的打分策略
- 归一化: 不同的分数有不同的权重, 进行加权计算得出一个最终得分
ScorePlugin插件功能如下:
- NodeLabel: 根据配置的标签过滤Node; (node_label.go)
- NodeResourcesLeastAllocation: 调度Pod时,选择资源分配较少的Node; (LeastAllocated.go)
- NodeResourcesMostAllocation: 调度Pod时,选择资源分配较多的Node; (MostAllocated.go)
- NodeResourcesBalancedAllocation: 调度Pod时,选择资源分配更为均匀的Node; (BalancedAllocation.go)
- ImageLocality: 选择已经存在Pod运行所需容器镜像的Node,这样可以省去下载镜像的过程,对于镜像非常大的容器是一个非常有价值的特性,因为启动时间可以节约几秒甚至是几十秒;
- InterPodAffinity: 实现Pod之间的亲和性和反亲和性;
- NodeAffinity: 实现了Node选择器和节点亲和性
- NodePreferAvoidPods: 基于Node的注解 scheduler.alpha.kubernetes.io/preferAvoidPods打分;
- RequestedToCapacityRatio: 根据已分配资源的配置函数选择偏爱Node;
- PodTopologySpread: 实现Pod拓扑分布;
- SelectorSpread: 对于属于Services、ReplicaSets和StatefulSets的Pod,偏好跨多节点部署;
- ServiceAffinity: 检查属于某个服务(Service)的Pod与配置的标签所定义的Node集合是否适配,这个插件还支持将属于某个服务的Pod分散到各个Node;
- TaintToleration: 实现了污点和容忍度;
其他扩展点可以见 : https://kubernetes.io/zh/docs/concepts/scheduling-eviction/scheduling-framework/
关键类
调度要做的事, 其实就是合理利用各种资源, 把Pod分配到合适的Node上
NodeInfo
type NodeInfo struct
NodeInfo是node的聚合信息,主要包括:
-
node *v1.Node node的结构体
-
Pods []*PodInfo:当前node上pod的数量
-
UsedPorts HostPortInfo:已分配的端口
-
Requested *Resource : 已分配的所有资源的总和
Resource
type Resource struct {
MilliCPU int64
Memory int64
EphemeralStorage int64
AllowedPodNumber int
ScalarResources map[v1.ResourceName]int64
}
调度的方法入口
func (sched *Scheduler) scheduleOne(ctx context.Context)
schedule framework
// frameworkImpl is the component responsible for initializing and running scheduler
// plugins.
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
clientSet clientset.Interface
kubeConfig *restclient.Config
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
profileName string
extenders []framework.Extender
framework.PodNominator
parallelizer parallelize.Parallelizer
// Indicates that RunFilterPlugins should accumulate all failed statuses and not return
// after the first failure.
runAllFilters bool
}
generic_scheduler.go
过滤
func (g *genericScheduler) findNodesThatFitPod(ctx context.Context, extenders []framework.Extender, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error)
打分
func prioritizeNodes(
ctx context.Context,
extenders []framework.Extender,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
nodes []*v1.Node, // 对所有的node进行打分
) (framework.NodeScoreList, error)