深入浅出XTTS:Oracle数据库迁移升级利器
演讲大纲:
1. 什么是XTTS
2. 适用场景
3. XTTS的基本操作步骤
4. XTTS案例分享
今天主要跟大家分享一下XTTS,在网上曾看过相关讨论,但发现按网上讲的那些去实际操作的话,还是会遇到一些坑,并不能实际落下来,所以今天想跟大家分享一些实战干货.
一、什么是XTTS
XTTS其实是从TTS来的,TTS大家做过吗?
TTS其实也是传输数据的一种手段,传输数据的时候可能用过EXP的方式,再往后可能用数据泵导入导出一些数据,或者去做备份然后再恢复.其实还有一种方式是用TTS,TTS就是传输表空间,把表空间传输出去,数据从一个库传输到另外一个库,而XTTS是在TTS基础上做了一些更新,支持了跨平台,再有一个可以支持增量备份.
因为过去传统的TTS是不支持增量的,可以想象一下,一个表空间从一个库拷贝到另外一个库,转移过程当中业务新增的数据是有所丢失的.
二、适用场景
1.数据泵
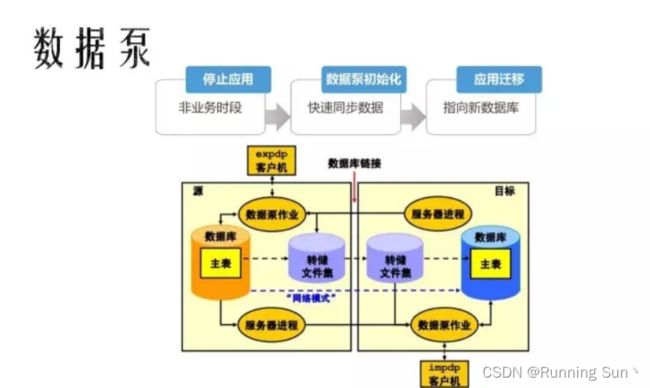
这种方式进行数据迁移,为了保证应用不丢数据,做的时候需要把应用停掉,停完应外之后数据没有更新了,可以能保证所有业务表的一致性,这种方式操作起来其实是最简单的,它比较适用的场景就是数据量比较小、数据大概在5T以下,使用数据泵会方便很多.
2.GoldenGate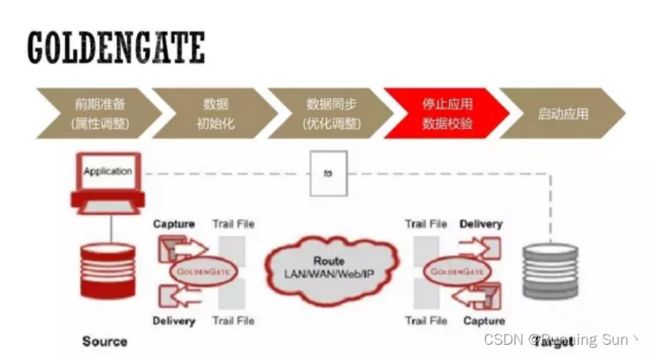
再往下一种就是在做一些重要的大型系统,对它进行迁移时,往往会使用GoldenGate,它迁移的时间很短,刚才使用数据泵时需要提前把应用停掉,或者允许迁移过程中的数据丢失,但是对于GoldenGate而言,在准备的阶段数据一直是同步的,只有业务正式割接时才把业务停掉,切换连接串,切到新的库上,停机时间十分短暂.
3.XTTS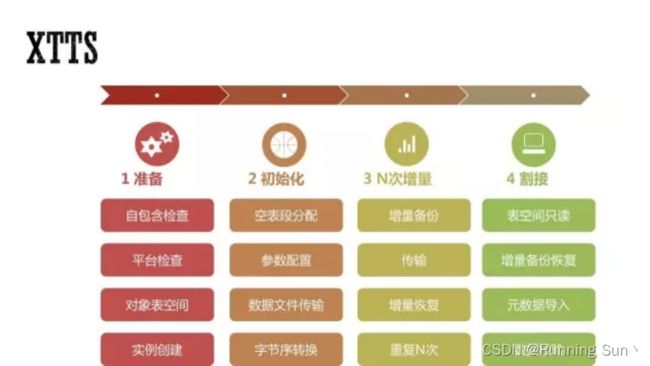
再看一下XTTS,XTTS其实也是类似于GoldenGate的方式,也是前期要有一个准备,有一个数据的初始化,数据初始化之后,它是后续作为一个增量的恢复,把初始化之后的那些变更数据,使用增量的备份和恢复,去把之前的数据往前补上,到最后应用切换时,把最后一次小增量再补回来.这样保证割接的时间便会比较短暂.
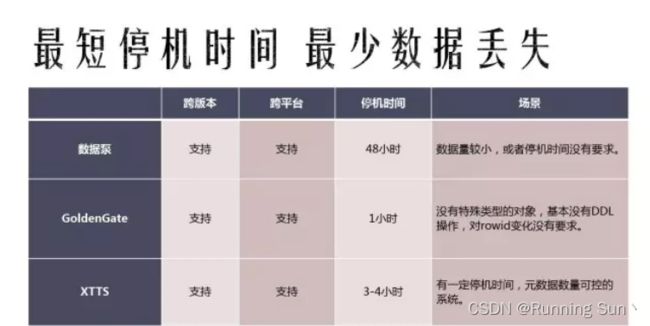
最短停机时间,最少数据丢失的一种,这是甲方的诉求.那么来总结下三种方式:
数据泵、GoldenGate、XTTS这三种方式都是支持跨版本、跨平台、停机时间,对于GoldenGate来说它的停机时间是最短的,数据泵是停机时间最长,XTTS是介于这两者之间的,后面会进行更深入的讨论,看一下XTTS实际的步骤,在看完这个步骤之后,就可以看到时间具体花在哪.
三、XTTS的基本操作步骤
对于现在很多大型企业来说,现在有一个很大的环境是去IOE,但O是很难去掉的一个东西,而I和E其实是很多厂商开始实施的事情,这里就有一个很重要的点就是跨平台,平台会从以前的小机迁移到x86,所以需要考虑到跨平台的问题.
1.TTS的基本步骤
A、将源端数据库表空间设置为READ ONLY模式.
B、传输数据文件到目标系统.
C、转换数据文件为目标系统的字节序.
D、在源端导出元数据,并在目标端导入.
E、将目标端的数据库表空间设置为READ WRITE.
讲解XTTS前可以先看一下TTS,很多同学想必都用过TTS.TTS操作起来很简单,第一步是把源端的表空间设置为READ ONLY,把源端的数据文件传输到目标端,拷贝过去就可以,拷贝过去之后会牵扯到转换字节序的问题,然后是在源端对源数据做一个元数据的导出,在目标端把元数据再导入,导入之后目标端就已经能看到用户的数据,最后把目标端表空间置为READ WRITE.
2.XTTS的基本步骤
A、将源端数据文件传输到目标系统.
B、转换数据文件为目标系统的字节序.
C、在源端创建增量备份,并传输到目标端.
D、在目标端恢复增量别分.
E、重复多次操作C和D步骤.
F、将源端数据库表空间设置为READ ONLY模式.
G、最后一次执行C和D步骤.
H、在源端导出元数据,并在目标端导入.
I、将目标端的数据库表空间设置为READ WRITE.
再看到XTTS的步骤,猛的看上去这个步骤比TTS多了很多,但其实它中间变化很少,其实E这个步骤写的是重复C和D,G这部分也是重复C和D,真正多的步骤是在源端进行一个增量的备份,把它传输到目标端,在目标端做一个增量的恢复.
谈谈做TTS具体存在哪些问题.把源端的一个表空间置成了READ ONLY,这时已经不能提供正常业务了,对于5乘8的系统来说,对它的影响其是比较小的,可以接受这种情况的.但对于7*24小时的业务来说,不可能在迁移的过程中随便的停掉源端的业务,这种肯定不能接受的,这个时候就需要迁移的过程当中尽量保证业务是可用的,而XTTS就可以保证源端的业务迁移前一直可用.
3.XTTS的参数设置

XTTS涉及到的参数,乍一看感觉比较多,其实可以分成两部分的参数,XTTS可以使用两种方法去传输数据.个人是建议使用DBMS_FILE_TRANSFER数据包的方式去做.
第一个是平台号,可以通过语句从源端数据库里面查询到.
第二个是源端的数据文件目录,第三个是目标端的一个目录,第四个是目标端创建的db_link,剩下几个是源端备份保存路径,目标端备份文件的保存路径,还有目标端增量备份的路径.
底下这两个都叫目标端文件的路径,这两个有什么区别呢?
这个目标端备份的路径可以理解为,你迁移完之后,你数据文件所在的路径,即迁移完之后,把数据从这边迁移到了这边,新的数据文件在目录里面就是它的目录
backupondest是增量备份文件目录,增量备份文件是从源端产生的,是源端做完第一次初始化之后,源端需要对这段时间做一个增量的备份,而这些备份集放在这个目录里面.
4.XTTS案例
1).XTTS案例-准备
下面讲一个简单的例子,看一下XTTS操作是什么样的,首先第一步是在源端,源端执行如下命令:
§ 源端运行perl脚本,操作命令
$ORACLE_HOME/perl/bin/perl xttdriver.pl –S
该操作将生成xttnewdatafiles.txt、getfile.sql两个文件.
2).XTTS案例-数据文件拷贝
首先需要在配置信息里面,把这些信息做好配置,做好配置之后可以在源端执行 - S操作,当然在这个位置需要设置上要传输哪一些表空间,执行完 - S会生成两个文件.然后,要把生成的那两个文件传输到目标端,传输到目标端之后执行 - G这个参数,会把源端数据文件抽到目标端.
目标端执行命令:

3).XTTS案例-进行第1次增量备份
因为抽取过程往往是比较费时的,所以需要把这一段时间的数据再追回来,追回来时在源端做一次增量备份,这个备份指的是从第一次拽数据文件到做本次增量备份的时间段内新增的数据,执行如下命令,这样执行完了文件的备份,目录底下生成三个文件,做增量恢复的时候需要把它产生的文件,以及增量备份级同时拷到目标端.
$ORACLE_HOME/perl/bin /perl xttdriver.pl –i
该命令将对xtt.properties参数文件中指定的表空间,使用进行一个增量备份,同时会生成tsbkupmap.txt、incrbackups.txt、xttplan.txt三个文件.
备份的数据是从做xttdriver.pl -S时在xttplan.txt文件中记录的SCN开始的.备份完成后需要将这3个文件连同增量备份集一起传输到目标端.
4).XTTS案例-进行第1此增量恢复
拷贝到目标端后,就执行一下 - r操作,完了之后把增量备份恢复到了目标端.然后回到源端执行Pl - s操作,确认了增量备份已经完成了恢复,这样下次再做增量备份时,就从上一次做增量备份的点继续往后去做备份.

但是如果一套库上有多个实例的话,在执行该步骤之前,需要对环境变量进行确认,如检查当前ORACLE_SID是否是需要执行的SID,否则可能会恢复到其他实例上.(并非是真实的恢复,因为其他实例跟这个备份集没有任何关系,但恢复的过程会在其他实例上进行一遍,如关闭/启动数据库,包括增量恢复的日志都会在另一个数据库上显示.)如果发生了这种事情,不用紧张,调整好环境变量,再执行一次perl xttdriver.pl –r即可.误操作的实例不受影响.
5).XTTS案例-进行SCN推进
解释下 - s这个过程.
假设初始化数据文件时SCN号是100,做增量时SCN号是200,这之间数据是从100到200之间,如果做完 - s之后再做增量备份,这个SCN号就变成200了.如果不做 - s,就意味着在源端做恢复的时候,有可能出现了异常,没有恢复成功,这会再去做增量备份,还是从100开始往后做.
$ORACLE_HOME/perl/bin/ perl xttdriver.pl –s
该命令将修改FROM_SCN,用于确定下一次增量备份的起点.
建议在【目标端】每次做完recover动作后,【源端】就执行一次该命令,以免遗忘.
6).XTTS案例-最后的增量备份和恢复
最后一次做备份及恢复时有很重要的一步,就是把源端的表空间设成RARD ONLY,再做一次备份和恢复,这样就完成了数据文件传输的过程.最后的步骤还是元数据的导入,最后这个步骤和TTS步骤几乎是一样的.导出和导入的命令也是很简单.
【原库端】表空间设置为READ ONLY
alter tablespace XXXX read only;
【原库端】做最后一次增量备份
perl xttdriver.pl –i
【目标端】做最后一次增量恢复
perl xttdriver.pl –r
在执行完恢复操作后,脚本会自动将目标库重启,不需要人工干预,如果出现到mount状态出现异常,根据情况手工执行后续命令.
刚才说的是理想的实验环境过程,通过这个过程大家可以简单了解XTTS整个过程,而从这个过程大家会发现XTTS其实是很简单的一个过程,第一步是写配置文件,配置文件里面写好的一些系统里的信息,它的平台号,写上传输哪一些表空间,以及设置一些文件的源端的地址,目标端的地址配备好之后,然后去执行一些后面的参数,都是很简单的一些操作,下面就考虑一些实际当中的一些案例.
四、XTTS案例分享
1.运营商环境
首先是目标端是生产库,第二个是源端的数据量是20TB+,每天归档量是1TB+,本地空间不足2TB,网络单进程是35MB/S,业务中断时间是3小时内,业务中断时间这么短,数据量比较大的情况下,第一时间就会考虑GoldenGate,因为它的数据是实时传输的,最后保证最后中断时间比较短.
大家入行业时大概都听说过DBA是比较清闲的一份事业,这个其实是每个人刚入行时的愿景,实际工作当中往往碰不到,尤其遇到这种需求时.在这种情况下,如果用GoldenGate的话,就需要把数据库里的每一个用户去分组做一个导出,导出完之后再去目标端做一个个恢复,恢复完之后建立了某几个用户的连接之后再循环操作.再加上每次传出数据量只有1TB,网络速度又不是很高,时间和工作量是一个很大的情况.基本上至少要两周的时间才能完成GoldenGate的搭建,这样再过一段时间稳定之后,业务方才会去允许你做正式的割接,这个工作量可能大家都深有体会.实际上, XTTS可以较轻松地解决这个问题.
首先,数据量虽然是20TB,但是调用dbms_file_transfer包,可以很轻松地把源端数据文件传输到目标端,传输的过程当中人为不需要干预的,周末的时候让它传输文件就好了,一个周末传完数据文件之后,周一来了之后对它进行从周五到周一这段时间增量数据做一个恢复就OK,只要保证在正式迁移的那一天,差的数据比较少的情况下就可以完成迁移的工作.
但XTTS也并非完美,它存在一个问题,就是在它做恢复时,就是刚才看到的那个步骤需要重启数据库,这个案例里面对的问题是目标端数据库也是一个生产库,这种情况下如何破解呢?很简单.

只需要创建一个pfile就可以了,这样在做数据文件恢复的过程中,就不会影响到的生产环境.再有一个问题就是考虑如何把整个最后增量的备份和恢复时间缩短到可控的时间(三个小时之内).
2.如何加速XTTS
来看一下这个XTTS整个的时间流程,准备阶段、初始化和N次增量备份恢复,这些都是迁移之前的,只需要考虑实际停业务的时间,这段时间做表空间只读,增量备份恢复,元数据导入,数据校验.知道表空间的只读和数据的校验,这两个时间是固定的,表空间只读速度很快,关键的时间点是增量的备份和恢复的时间,以及元数据的导入时间.

这是一个实际的案例,在做增量备份时,一天的数据,因为它每天的归档量是1T,每24个小时业务数据需要备份的时间是6个小时,这种情况下再加上网络速度,备份是需要6小时,传输这些增量备份时间也需要6小时,恢复需要4个小时,时间一加是6+6+4就是16个小时,整个备份恢复的时间是一个很长的时间,换句话说,完全不可能缩减到3小时以内.
其实可以利用Oracle的一些特性,比方说它有一个BCT的特性,可以开启BCT的特性,它做增量备份时,它只会扫描有变更的数据块,这样就可以加速备份的时间.开启的方式也很简单,执行如下命令就直接开启,需要注意的目录需要共享的目录.
再有一个问题就是关于传输的问题,有了增量备份,增量备份放在源端,放在源端之后,传输备份也是需要一定时间.刚刚看到实际环境里面,网络环境是35兆每秒,对于24小时数据,产生的备份文件也是1T,拿1T除以35兆每秒,时间也很长,如何优化传输的时间呢?
这里面有一个小技巧,就是在RMAN里面开启并行,表空间最多对应那么多分片,这样有了分片之后就可以开不同的进程传输数据文件.

为什么说这个有意义呢?
因为在生产环境里面,发现有一些表空间会比其他表空间大很多,就是它的容量很不均匀,有可能一个表空间的大小就可以超过其它表空间很多倍,虽然是一口气对十几个表空间做迁移的工作,但那一个表空间传输的时间是最长的.经过开启并行之后,把一个表空间分成8个片,分组进行传输,这样就可以加快传输的速度.
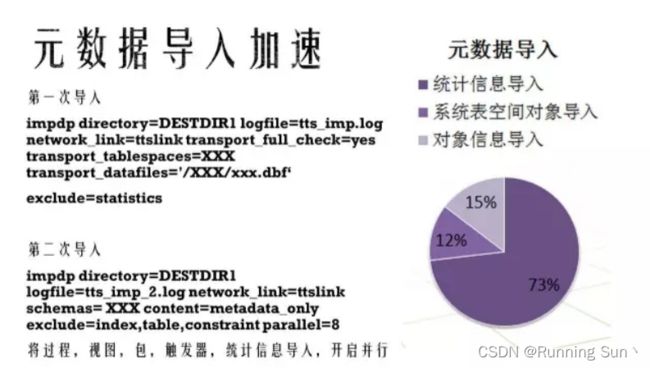
再有一个是要考虑元数据导入的时间,正常情况下,元数据导入的时间73%花在统计信息导入这一块.这块有一个小的技巧可加入统计信息导入,就是第一次导入这个元数据的时候,把统计信息排除,排除掉之后可以快速地第二次导入,第二次导入时会加入一个并行,这一块就可以很快速地导入这些文件.同时这一步可以把之前没有导入的这些过程,视图、包、触发器这些信息也可以导入进去.表空间里面只包含表、索引这些东西,但下面这些东西其实是存在系统表空间里的,系统表空间没有通过XTTS做迁移,所以这部分数据如果不导入的话是丢失的.
3.迁移前的准备
最后再来看看整个XTTS在前期准备当中还需要做哪一些工作.
首先是对象的统计,跟业务确认需要传输哪一些数据,哪一些表空间是迁移的对象.
第二个是源端字符集的检查.
第三个是检查表有没有空段.
第四个是失效对象检查.
第五是基于XMLSchema的HMLType对象检查.
第六个是目标端创建检查用DBlink.
第七个是检查源数据库的目标库具有重复名称的表空间.
最后是检查是否存在应用用户建在systmwem、sysaux、users上的情况.
然后表空间自包含的检查,所有表空间里面是否都是自包含的,对表新旧环境role,对比新旧环境profile,在新环境当中对比并创建用户,生成恢复用户默认表空间和临时表空间的脚本,创建非默认的temep表空间,最后一部分是软件包上传.
五、总结
简单总结一下,XTTS支持跨平台迁移,操作起来十分方便,使用XTTS之后就可以让DBA过上一个理想中的生活,轻松完成迁移工作.最后,它的停机时间较短.
建议大家在做迁移的时候减少批次,批次越多,增量备份的数据越少,数据越少,最后停机时间越短,但是这个过程如果做太多就越容易出错.谢谢大家!
Q&A
Q1:完成增量备份的时候,假如说要恢复时,能不能用归档的方法?
A1:在XTTS里面是不可以的.
Q2:如果说加快传输方式的就要开并行,如果有20t,如果开并行有可能影响现有生产?
A2:没错,初始化传输数据文件的时候可以开并行,做增量备份的时候也可以开并行,这两个是不一样的.其实这个影响主要是网络传输那一块,看实际的网络带宽.
Q3:并行开完了以后传输速度是加快,生产不停机可能会影响现在生产,会出现等待事件.
A3:做并行的时候,肯定是先要测试网络和磁盘性能最大可以开到几个并行,可以开到最大并行减N的方式来保证生产,肯定要给生产留一点空间的.
Q4:EXP导出的时候,有可能会遇到ora-01555的问题.
A4:没错,但是导出原数据的过程出现的时间很小的,而且表空已经设置为read only,表空间的没有被使用,所以不会出现ora-01555.
Q5:之前说传输,从源端到目标端有一个重启,那块没听太懂.
A5:XTTS在执行 - l的时候,会导致目标和数据库自动重启到写nomount状态下恢复数据文件,这个过程中,可以创建另外一个实例来做恢复这个事情,只有真正的到元数据导入这个步骤的时候,再切换到实际的目标库就可以了.