(20)Linux初始文件描述符
前言:本章我们介绍 O_WRONLY, O_TRUNC, O_APPEND 和 O_RDONLY。之后我们开始讲解文件描述符。
一、系统传递标记位
1、O_WRONLY
C 语言在 w 模式打开文件时,文件内容是会被清空的,但是 O_WRONLY 好像并非如此?
代码演示:当前我们的 log.txt 内有 5 行数据,现在我们执行下面的代码:
1 #include
2 #include
3 #include
4 #include
5 #include
6 #include // 需引入头文件
7 int main()
8 {
9 umask(0); // umask现在就为0,听我的,别听操作系统的umask了
10 int fd = open("log.txt", O_WRONLY | O_CREAT, 0666); // 八进制表示
11 if (fd < 0) {
12 perror("open");
13 return 1;
14 }
15 printf("fd:%d\n",fd);
16 int cnt=2;
17 const char* str="666666\n";
18 while(cnt--){
19 write(fd,str,strlen(str));
20 }
21
22 close(fd);//关闭文件
23
24 return 0;
25 } 运行结果:

我们以前在 C 语言中,w 会覆盖把全部数据覆盖,每次执行代码可都是会清空文件内容的。
而我们的 O_WRONLY 似乎没有全部覆盖,曾经的数据被保留了下来,并没有清空!
其实,没有清空根本就不是读写的问题,而是取决于有没有加 O_TRUNC 选项!
因此,只有 O_WRONLY 和 O_CREAT 选项是不够的:
- 如果想要达到 w 的效果还需要增添 O_TRUNC
- 如果想到达到 a 的效果还需要 O_APPEND
2、 O_TRUNC 截断清空(对标 w)
在我们打开文件时,如果带上 O_TRUNC 选项,那么它将会清空原始文件。
如果文件存在,并且打开是为了写入,O_TRUNC 会将该文件长度缩短 (truncated) 为 0。
也就是所谓的 截断清空 (Truncate Empty) ,我们默认情况下文件系统调用接口不会清空文件的,
但如果你想清空,就需要给 open() 接口 带上 O_TRUNC 选项:
代码演示:让 open() 达到 fopen 中 "w" 模式的效果
1 #include
2 #include
3 #include
4 #include
5 #include
6 #include // 需引入头文件
7 int main()
8 {
9 umask(0); // umask现在就为0,听我的,别听操作系统的umask了
10 int fd = open("log.txt", O_WRONLY | O_CREAT|O_TRUNC, 0666); // 八进制表示
11 if (fd < 0) {
12 perror("open");
13 return 1;
14 }
15 printf("fd:%d\n",fd);
16 int cnt=2;
17 const char* str="666666\n";
18 while(cnt--){
19 write(fd,str,strlen(str));
20 }
21
22 close(fd);//关闭文件
23
24 return 0;
25 } 运行结果:

然而 C 语言的 fopen 函数,只需要浅浅地标上一个 "w" 就能搞定了:
open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
fopen("log.txt", "w");3、O_APPEND 追加(对标 a)
C 语言中我们以 a 模式打开文件做到追加的效果。
现在我们用 open,追加是不清空原始内容的,所以我们不能加 O_TRUNC,得加 O_APPEND:
int fd = open("log.txt", O_WRONLY | O_CREATE | O_APPEND, 0666);运行结果如下:

再次追加:

我们再来对照 C 语言的 fopen,想做到这样的效果只需要一个 "a" :
open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
fopen("log.txt", "a");4、O_REONLY 读取
如果我们想读取一个文件,那么这个文件肯定是存在的,我们传 O_RDONLY 选项:
int main()
{
umask(0);
int fd = open("log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
char buffer[128];
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0) {
buffer[s] = '\0'; // 最后字符串序列设置为 '\0'
printf("%s", buffer);
}
close(fd);
return 0;
}运行结果:

二、文件描述符(fd)
1、open 参数的返回值
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);我们使用 open 函数举的例子中,一直是用一个叫做 fd 的变量去接收的。
fopen 中我们习惯使用 fp / pf 接收返回值,那是因为是 fopen 的返回值 FILE* 是文件指针,
file pointer 的缩写即是 fp,所以我们就习惯将这个接收 fopen 返回值的变量取名为 fp / pf。
那为什么接收 open 的返回值的变量要叫 fd 呢?
fd——————文件描述符
open 如果调用成功会返回一个新的 文件描述符 (file descriptor) ,如果失败会返回 -1 。

代码演示:我们现在多打开几个文件,观察 fd 的返回值
int main(void)
{
int fd_1 = open("log1.txt", O_WRONLY | O_CREAT, 0666);
int fd_2 = open("log2.txt", O_WRONLY | O_CREAT, 0666);
int fd_3 = open("log3.txt", O_WRONLY | O_CREAT, 0666);
int fd_4 = open("log4.txt", O_WRONLY | O_CREAT, 0666);
int fd_5 = open("log5.txt", O_WRONLY | O_CREAT, 0666);
printf("fd_1: %d\n", fd_1);
printf("fd_2: %d\n", fd_2);
printf("fd_3: %d\n", fd_3);
printf("fd_4: %d\n", fd_4);
printf("fd_5: %d\n", fd_5);
close(fd_1);
close(fd_2);
close(fd_3);
close(fd_4);
close(fd_5);
return 0;
}运行结果:

我们发现这 open 的 5 个文件的 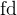 (返回值) 分别是
(返回值) 分别是 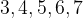 ,那么问题了来了:
,那么问题了来了:
为什么从 3 开始,而不是从 0 开始?0, 1, 2 去哪了?

系统接口认的是外设,而  标准库函数认的是:
标准库函数认的是:
#include
extern FILE* stdin;
extern FILE* stdout;
extern FILE* stderr; 系统调用接口!那么 stdin, stdout, stderr 和上面的 0,1,2 又有什么关系呢?
想解决这个问题,我们得先说说  :
:
我们知道,FILE* 是文件指针,那么 是什么呢?它是 库提供的结构体。
只要是结构体,它内部一定封装了多个成员!
虽然 用的是 FILE*,但是系统的底层文件接口只认 fd,也就是说: 标准库调用的系统接口,对文件操作而言,系统接口只认文件描述符。
因此,FILE 内部必定封装了文件操作符 !
下面我们来验证一下,先验证 0,1,2 就是标准 
代码验证:0 是标准输入 (stdin)
int main(void)
{
// 验证 0,1,2 就是标准 I/O
char buffer[1024];
ssize_t s = read(0, buffer, sizeof(buffer) - 1);
if (s > 0) {
buffer[s] = '\0';
printf("echo: %s", buffer);
}
}运行结果如下:

代码验证:stdout 标准写入(1) 和 stderr 错误写入(2) :

至此,我们证明了:
0 (标准输入, stdin) ,1 (标准输出, stdout),2 (错误输出, stderr)
代码验证:下面我们就来证明 fd 的存在,证明 stdin, stdout 和 stderr 的对应关系
int main(void)
{
printf("stdin: %d\n", stdin->_fileno);
printf("stdout: %d\n", stdout->_fileno);
printf("stderr: %d\n", stderr->_fileno);
}运行结果如下:

函数接口的对应:fopen / fclose / fread / fwrite : open / close / read / write
数据类型的对应:(FILE* → FILE) →
结论:我们用的 语言接口一定封装了系统调用接口!
2、文件描述符的底层理解
逻辑推导:进程:内存文件的关系 → 内存 → 被打开的文件实在内存里面的
一个进程可以打开多个文件,所以在内核中,进程与打开的文件之比为:1:n
所以系统在运行中,有可能会存在大量的被打开的文件 → OS 要对这些被打开的文件进行管理!
OS 如何管理这些被打开的文件呢?还是我们老生常谈的那句话:
先描述,再组织!
所以对我们来说,一个文件被打开不要片面的认为只是对文件内容动动手脚!
它还要 在内核中创建被打开文件的内核数据结构 —— 先描述
struct file {
// 包含了你想看到的文件的所有大部分 内容 + 属性
struct file* next;
struct file* prev;
};如果你在内核中打开了多个的文件,那么系统会在内核中为文件创建一个 struct file 结构。
可以通过 next 和 prev 将其前后关联起来(内核的链表结构有它自己的设计,这里我们不关注)。
既然你打开了一个文件,就会创建一个 struct file,那么你打开多个文件,
系统中必然会存在大量的 struct file,并且该结构我们用链表的形式链接起来:
如此一来,对被打开的文件的管理,就转化成为了对链表的增删改查!
程如何和打开的文件建立映射关系?打开的文件哪一个属于我的进程呢?
在内核中,task_struct 在自己的数据结构中包含了一个 struct files_struct *files (结构体指针):
struct files_struct *files;而我们刚才提到的 "数组" 就在这个 file_struct 里面,该数组是在该结构体内部的一个数组。
struct file* fd_array[];该数组类型为 struct file* 是一个 指针数组,里面存放的都是指向 struct file 的指针!
数组元素映射到各个被打开的文件,直接指向对应的文件结构,若没有指向就设为 NULL。
此时,我们就建立起了 "进程" 和 "文件" 之间映射关系的桥梁。

如此一来,进程想访问某一个文件,只需要知道该文件在这张映射表中的数组下标。
上面这些就是在内核中去实现的映射关系了!这个下标 0,1,2,3,4 就是对应的文件描述符 fd
!
我们调用的 open / read / write / close 接口都需要 fd:
选号:当我们 open 打开一个新的文件时,先创建 struct file,然后在当前的文件描述表中分配一个没有被使用的下标,把 stuct file 结构体的地址填入 struct file* 中,然后通过 open 将对应的 fd 返回给用户,比如 3,此时我们的 fd 变量接收的 open 的返回值就是 3 了。
兑奖:后续用户再调用 read, write 这样的接口一定传入了对应的 fd,找到了特定进程的 files,在根据对应的 fd 索引到指针数组,通过 sturct file* 中存储的 struct file 结构体地址,找到文件对象,之后就可以对相关的操作了。
总结:其本质是因为它是一个数组下标,系统中使用指针数组的方式,建立进程和文件之间的关系。将 fd 返回给上层用户,上层用户就可以调用后续接口 (read, write...) 来索引对应的指针数组,找到对应文件,这就是 fd 为什么是 0,1,2... 的原因了!
3、初识 VFS(虚拟文件系统)
上面说的这种设置一套 struct file 来表示文件的内存文件系统的操作,
我们称之为 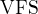 (virtual file system) ,即 虚拟文件系统 。
(virtual file system) ,即 虚拟文件系统 。
![]()

4、回头看问题:fd 的 0,1,2,3...
至此,我们梳理完了。现在我们再回过头看 fd 的 1,2,3,4... 就能有一个清楚的认识了。
现在我们再我们最开始的问题,想必大家已经做到 "知其然知其所以然" 了!
① 为什么从 3 开始,而不是从 0 开始?0, 1, 2 去哪了?
stdin,stdout,stderr 和 0,1,2 是对应关系,因为 open 时默认就打开了,这也是为什么我们默认打开一个新的文件,fd 是从 3 开始的而不是 0 开始的真正原因!
② 0, 1, 2, 3, 4……,是不是有点像数组下标?
不是有点像,它其实上就是数组下标!fd 0,1,2,3,4... 在内核中属于进程和文件的对应关系,是用数组来完成映射的,这些数字就是数组的下标。read, write, close 这些接口都必须用 0,1,2,3,4 来找到底层对应的 struct file 结构,进而访问到底层对应的读写方法 (包括相关的属性,缓冲区等) 。