通用图形处理器设计——GPGPU编程模型与架构原理(三)
第3章 GPGPU控制核心架构
3.1 GPGPU架构概述
典型的CPU-GPGPU异构计算平台如图3-1所示,CPU作为控制主体统筹整个系统的运行,PCI-E充当CPU和GPGPU的交流通道,CPU通过PCI-E与GPGPU进行通信,将程序中的内核函数加载到GPGPU的计算单元阵列(SM/CU)和内部的计算单元(SP/PE)上执行 。
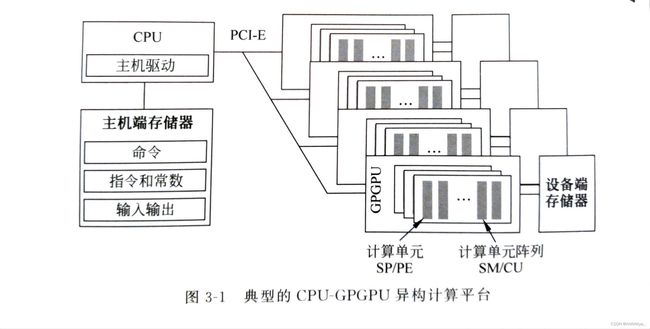
典型的GPGPU架构及可编程多处理器的组成如图3-2所示。SM/CU构成GPGPU核心架构主体,SM/CU通过互连与多个存储分区(L2 cache和对应的DRAM)相连,实现更高并行度的高带宽访存操作。
每个SM/CU都有自己的寄存器文件,如果单个线程使用的寄存器少,则可以运行更多的线程,反之则较少线程。编译器会在线程并行度和寄存器溢出之间寻找高效的平衡来优化寄存器分配。
GPGPU架构优点:
(1)有利于掩盖存储器加载和纹理预取的延时。(在等待数据或纹理加载时,硬件可以执行其他线程,以提升吞吐率)
(2)支持细粒度并行图形渲染编程模型和并行计算编程模型。
(3) 通过将物理处理器虚拟化为线程及线程块,简化了并行编程模型。
GPGPU架构局限:
(1)同一个线程网格中的线程块之间不允许存在依赖,能够独立执行。(协作组允许重新选择线程构成协作组,可以实现多粒度的协同操作)
(2)递归程序早期不被允许。(开始支持有限制的递归程序)
(3)典型的CPU-GPGPU异构计算还是需要独立的存储空间,主机和设备存储器之间复制数据和结果会带来额外开销。
(4)线程块和线程只能在CPU创建,而不能在内核函数执行过程中创建。(有一些新的GPGPU架构开始支持)
3.2 GPGPU指令流水线

每个线程束按照流水线方式执行读取,解码,发射,执行及写回过程。指令调度器原则上可以在任何就绪的线程束中挑选一个并采用锁步方式执行。(锁步使所有执行单元都执行同一条指令,简化控制逻辑)
3.2.1 前段:取指与译码
取指单元:根据PC的值,从指令缓存中取出要执行指令的硬件单元。取出来的指令会经过译码后保存到指令缓冲中,等待后续调度,发射和执行。(PC值个数=SM/CU允许的最大线程数)
PC:程序计数器,记录线程束各自的执行进度和需要读取的下一条指令位置。
指令缓存:接收取指单元的PC,读取缓存中的指令并发送给译码单元进行解码。(减少直接从设备端存储器读取指令的次数)
译码单元:对取出的指令进行解码,并将解码后的指令放入指令缓冲中对应的空余位置上。(判断指令功能,指令所需源寄存器,目的寄存器和相应类型的执行单元或存储单元等信息,进而给出控制信号)
指令缓冲:暂存解码后的指令,等待发射。每个指令条目包括一条解码后的指令和两个标记位(有效位valid和就绪位ready),valid:为有效的已解码未发射指令;ready:为已就绪可以发射的指令。有效位会反馈给取指单元,表明指令缓冲中是否有空余的指令条目用于取值新的线程束指令。 还需要用记分牌的相关性检查,判断空闲硬件资源等
3.2.2 中段:调度与发射
调度单元:通过线程束调度器选择指令缓冲中某个线程束的就绪指令发射执行。发射从寄存器文件中读取源寄存器传送给执行单元。调度单元需要检查是否有线程在等待同步栅栏及数据相关的竞争和风险。不同指令在不同类型的流水线上执行。
记分牌:检查指令之间可能存在的相关性依赖(如WAW/RAW),确保流水化的指令仍正确执行。
分支单元和SIMT堆栈:指令存在条件分支的情况时,需要借助分支单元——活跃掩码和SIMT堆栈。
活跃掩码:一般通过n比特的独热编码来指示线程是否执行,将活跃掩码传送给发射单元进行控制。SIMT堆栈?
寄存器文件和操作数收集:发射从寄存器文件中读取源寄存器传送给执行单元,指令执行完成后写回寄存器文件更新。操作数收集器结构和寄存器板块交织映射等方式能减轻板块冲突的可能性。(板块冲突:处于性能考虑,寄存器文件会分板块设计,不同请求在同一板块同周期读取,会出现板块冲突)
3.2.3 后段:执行与写回
计算单元: 根据指令执行具体操作。
存储访问单元: 完成数据的加载和存储操作。
3.2.4 扩展讨论:线程束指令流水线
1.与其他流水线比较
(1)相对于标量流水线,GPGPU是以线程束为粒度,多个线程独立执行,可以在就绪的线程束中选择一个锁步,使所有执行单元都执行同一条指令,简化控制逻辑。
影响性能因素:条件分支,管理众多线程束如何选择合理线程束执行,线程产生数据访问请求时也可能因为庞大线程数量而相对分散。
(2)向量流水线,采用数据流水的方式一次性处理所有的向量元素,存在较大一次性启动延时代价,配备集中/分散及地址跳跃等地址访问能力来应对复杂地址访问模式,而GPGPU单线程独立地址计算能力,及线程切换更能掩藏延时。二者均采用活跃掩码方式,向量处理器更多利用软件来管理活跃掩码,GPGPU则采用硬件管理方式。
2.线程束宽度选择
线程网格和线程块大小由编程人员根据需求调节,而线程束大小是与硬件绑定且固定的。
(1)线程束相同时,线程束越大,线程束数量就越少,可能遭遇线程分支的概率越大,一旦发生线程分支,不同线程会执行不同代码,导致性能损失。
(2)越大的线程束在前段每次取指量越大,取指次数越少,可能带来性能差异。
3.3 线程分支
在流水线中遭遇了条件分支时,如下图所示,GPGPU往往会利用谓词寄存器和SIMT堆栈相结合的方式对发生了条件分支的指令流进行管理。
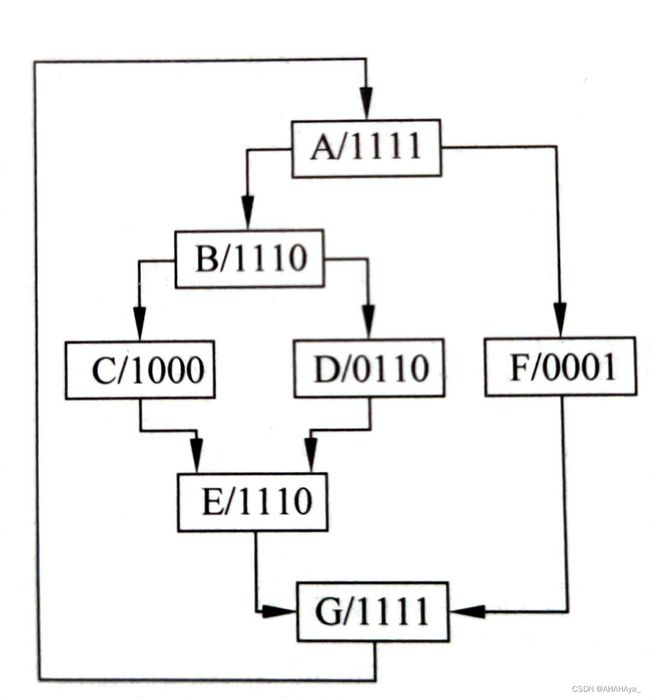
图3-5 嵌套分支内核函数示例的分支流图
3.3.1 谓词寄存器
谓词寄存器:为每个执行通道配备的1比特寄存器,用来控制每个通道是否开启或关闭,(1——打开,0——关闭)。广泛应用于向量处理器,SIMD和SIMT等架构中用来处理条件分支。
如图3-5所示,线程束中有4个线程,其中嵌套了三个分支,因此设置3次谓词寄存器。第一次,谓词寄存器p1在指令块A计算后,各个线程的谓词寄存器p1设为相应的值,即只有第4个线程的p1设为1,执行F块;第二次,谓词寄存器p2在指令块B计算后,各个线程的谓词寄存器p2设为相应的值,即只有第2,3个线程的p2设为1,执行D块;第三次,谓词寄存器p3在指令块G计算后,各个线程的谓词寄存器p3设为相应的值,即若i小于N时p3设为1,执行A块。
条件分支中,如果两个分支路径长度相等,SIMT执行效率降为50%,若双重嵌套且分支长度相等,则SIMT执行效率降为25%,以此类推。嵌套分支会让执行效率大幅降低。
3.3.2 SIMT堆栈
SIMT堆栈结构:可以根据每个线程的谓词寄存器形成线程束的活跃掩码信息,帮助调度哪些线程开启或关闭,从而实现分支线程管理。
如图3-5所示,A为线程分支点,G为分支线程的重聚点。识别线程的分支点和重聚点是管理活跃掩码的关键。
SIMT堆栈本质仍是一个栈,栈内的条目进出以压栈和出栈的方式,栈顶指针(TOS)始终指向栈最顶端的条目。每个条目包括以下三个字段:
(1)分支重聚点的PC(RPC),RPC的值由最早的重聚点指令PC确定,因此称为IPDOM。在图3-5中,C和D块在E重聚,E为一个IPDOM(为E的第一条指令),同样E和F的重聚点也是(也为G的第一条指令)。
(2)Next PC ( NP ),该分支内需要执行的PC。
(3)线程活跃掩码。
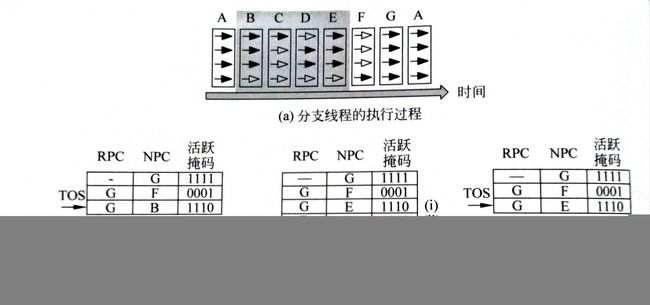
以图3-5为例,随时间周期的推进,分支线程的执行顺序如图3-6(a)所示,实心箭头表示被唤醒的线程,空心箭头表示未唤醒的。
初始时如3-6(b)所示,所有线程执行A指令块,NPC为G的第一条指令PC,即所有后面线程的重聚点,当到A指令块的最后一条指令时,会发生分支,分为两个互补的执行路径,则当前NPC转为RPC,指令块F和B的活跃掩码被压入栈,其RPC均为G。
当前线程束执行的指令由TOS条目的NPC获得,弹出指令块B的第一条指令,由其活跃掩码控制线程执行,B对应的NPC为E压栈,如图3-6(c)(i)所示,当执行到B的最后一条指令,再次发生分支,更新RPC,将C,D及活跃掩码压入栈如图3-6(c)(ii)和(iii)所示。
继续执行指令块C,当执行到指令块C的最后一条指令,其目标跳转的PC与RPC值相同,为指令块E,所以SIMT会将C弹栈,同样D也一样步骤,故SIMT更新为3-6(d)的状态。
3.3.3 分支屏障

atomicCAS为原子操作,同一个线程束内多个线程需要串行化地访问存储器中的mutex锁变量,也就意味着只有一个线程可以看到mutex的0值,进而获得锁退出循环执行C操作,而其他只能看到1值而不断循环。块C中获得锁的线程执行关键区操作,然后通过atomicExch原子交换将mutex赋值为0,即由获得mutex锁变量的线程来释放这把锁。
若由SIMT堆栈管理,C和B及活跃掩码被压入SIMT堆栈,如图3-8(b)所示,只有后三个线程完成B对应的指令才能执行C,而B是死循环,故将产生死锁。

分支屏障:设计了增加屏障(ADD)和等待屏障(WAIT)指令如图3-9所示,针对SIMT堆栈死锁设计了Yield指令,使某些线程进入让步状态(可通过显示插入Yield指令或者超时设置或者从数值较大的PC跳回数值较小的PC)。

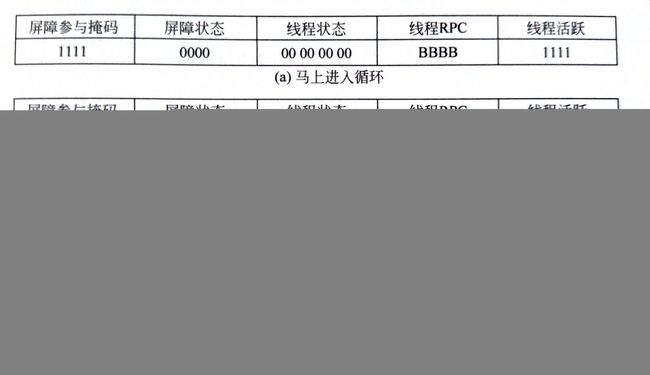
对于死锁问题采用分支屏障和Yield指令来进行解决,如下图3-10和3-11所示。

其中图3-11屏障状态:4bit,每一位代表一个线程,到达屏障状态为1否则为0。
线程状态有三个:00:就绪;01:挂起;10:让步。
每个线程对应1个RPC,即接下来要执行的指令。
线程执行完第一次循环得到3-11(b)的状态,其中一个线程可以开始执行C指令块,即到达了屏障,而其他线程继续循环。假设为第一个线程到达了屏障,故第一个线程RPC改为C,其他线程仍等待指令块B的指令。接着线程执行Yield指令,这时让三个线程进入让步状态,第一个线程进入活跃状态,因此无需等待其他三个线程直接穿过屏障执行C的指令。第一个线程执行了C指令块故可以释放一个线程进入屏障,假设第二个线程被释放就得到了3-11(d)的状态,重复(c)和(d)步骤走出死锁。
3.3.4 扩展讨论:更高效的线程分支执行
分支重聚点的选择
(1)寻找更早的分支重聚点,从而尽早让分支的线程重新回到SIMT执行状态,减少线程在分叉状态下的持续时间。
(2)积极实施分支线程的动态重组和合并,提升SIMT硬件利用率。
程序控制流分为结构化控制流和非结构控制流。结构化控制流:顺序执行的基本块,条件分支和循环;非结构控制流:goto,break,短路优化,长跳转和异常检测等。

非结构化控制流,常常早于IPDOM的局部重聚点,可以提前对部分线程进行重聚,从而提升SIMT硬件的资源利用率,改善程序的执行效率。
根据SIMT堆栈方式管理图3-12(a)的非结构控制流程序可能会出现(b.2),同一个基本块的不同线程会被安排在不同的周期执行,使程序执行效率低。
利用局部重聚点TF,实现由3-12(b.2)变为(b.3)能在更早的TF重聚。由编译器和硬件调度器实现。需要以下两种支持:
(1)当程序发生分支时,非活跃线程需要在活跃线程的TF中等待;
(2)如果部分线程进入TF,需要进行重聚合检查判断是否有线程可以合并。
线程动态重组及合并
(1)同线程束同PC线程的重组和合并
(2)不同线程束同PC线程的重组和合并
