【数据库原理】(15)数据关系模式与规范
在数据库系统设计中,数据模式的设计是至关重要的。这涉及到如何将现实世界的复杂结构和关系有效地转化为适宜的数据模式。关系模式,得益于其坚实的数学理论基础,不仅能以二维表的形式清晰地表达实体,还能描述实体之间的相互关系,因而成为数据库逻辑设计中一种强有力的工具。
一.关系模式设计概述
1.数据模式设计的重要性
数据模式设计的核心是如何构建一个有效的数据库模式,即如何基于一组给定的数据构建一个在数据存储和操纵方面性能优异的数据库系统。尽管面向对象的数据库设计方法也有其优势,但目前使用最广泛的方法仍是基于E-R(实体-关系)模型的方法。
从现实世界到E-R模型的转化,然后再将E-R模型转换为数据库系统支持的数据库模式,是数据库设计的常见流程。然而,这种方法可能导致数据冗余,进而引发其他不期望的异常,影响数据库性能。
2.关系数据库的规范化理论
在E-R模型出现之前,科德(Codd)提出了关系数据库理论,并发展出了一套关系数据库设计理论,即关系的规范化理论。这套理论依据现实世界中存在的数据依赖来处理关系模式的规范化,以达到优化数据库设计的目的。数据依赖是关系上的一种语义完整性约束,限制了关系模式在任何时刻实例的取值。
规范化的关系模式能避免许多不希望出现的异常。然而,识别所有的数据依赖并不是一件简单的事情,而且纯粹基于数据依赖进行的规范化处理所得到的数据库设计在实际应用中可能并非最优,因为它没有考虑到关系的实际大小和常见操作。
3.实际应用价值
关系数据库设计理论在实际应用中具有显著价值。首先,它能帮助用户分析并判定什么是一个良好的数据库模式,甚至评判哪些E-R模型能转化为优秀的数据库模式;其次,从E-R模型转化得到的关系模式可以通过规范化进一步优化;最后,关系数据库设计理论可以指导我们在必要时合并关系模式,从而简化设计。
因此,流行的关系数据库设计方法通常是先构建E-R模型,再将其转化为关系模式,最后对得到的关系模式进行优化处理,以确保数据库设计的有效性和效率。
二.关系模型的数学表示
关系模型可以被定义为一个五元组 R(U, D, DOM, F)。它包含以下组件:
- R:关系名,用于唯一标识关系模式。
- U:属性集,构成关系R的所有属性的集合。
- D:域集合,即所有属性可能的取值范围的集合。
- DOM:是属性到域的映射,它定义了每个属性的合法取值。
- F:是数据依赖集合,它规定了属性间的数据依赖关系。
这个五元组的定义提供了对关系模式的完整描述。关系模式是关系的蓝图或模板,而关系则是该模式在特定时刻的具体实例。
三.关系与关系模式
- 关系模式是静态的、稳定的,它定义了关系的结构和约束条件。
- 关系是关系模式在某一时刻的具体实例,是动态的,随时间变化而变化。
关系模式中最关键的部分是属性集U和数据依赖集合F,因为它们直接影响数据库的设计和结构。而域集合D和属性到域的映射DOM虽然在理论上很重要,但在具体的数据库设计中通常不是主要考虑的因素。
四.简化的关系模型表示
因此,关系模型常被简化为一个三元组 R(U, F)。在这种简化模型中:
- R(U, F) 表示关系模式,其中U是属性集,F是数据依赖集合。
- 只有当一个关系r满足数据依赖集合F中定义的所有约束时,r才是关系模式R(U, F)的有效实例。
这种简化的表示法强调了属性集和数据依赖在关系模型中的核心地位,简化了数据库设计和分析过程。
三.实例分析
在数据库中怎样才能建立一个好的关系数据库模式呢?在解决如何设计一个好的关系数据库模式之前,首先看一看什么是坏的数据库设计。
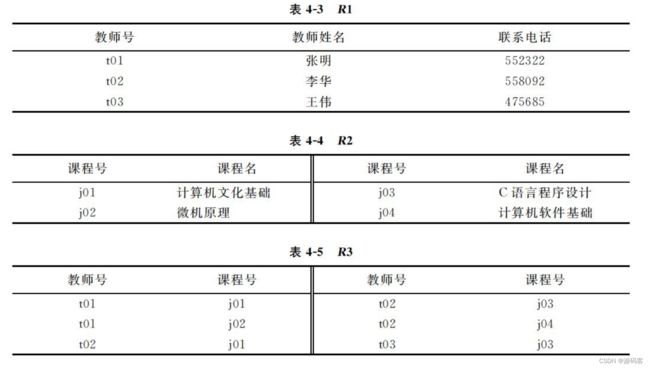
教师授课管理系统。在实际当中进行教师授课的人工管理,通常是制作一张表。
管理人员通过查询表来了解某个教师可以教授哪些课程,以便安排教学任务、通知授课教师。对这个实际问题,把它设计成一个教师授课管理的计算机系统,首先要将表中的数据描述成关系型数据库的关系数据模型,然后将表格数据存储到计算机中。关系模型是一个标准的二维表,要准确存储表中的数据,直接作为一个关系表如下:

上表对应的关系模式为:R(教师号,教师姓名,联系电话,课程号,课程名)。由现实世界中的事实可知:一个教师只有一个教师姓名、电话;一门课程只有一个课程号。
于是关系模式 R的关键字是(教师号,课程号),即根据每个教师号和所教课程的编号就能确定课程名称,根据每个教师号就能确定教师姓名、联系电话。虽然这个模式只有五个属性,但在使用过程中明显存在下列问题。
-
数据冗余:同一教师教授多门课程时,其教师号、姓名和联系电话会重复存储。
-
更新异常:数据冗余导致更新操作复杂化,可能产生不一致性。例如,一个教师教三门课程,在关系中就会有三条记录。如果这个教师的地址改变了,这三条记录中的联系电话都要改变;若在修改的过程中,有一条记录的联系忘记更改了,就会造成这个教师联系电话不一致的错误。
-
插入异常:无法单独添加教师或课程信息,因为教师号和课程号是关键字,不能为空。
-
删除异常:删除特定课程可能会不小心删除教师的基本信息。
为解决这些问题,提出了分解关系模式的方法,将原始模式分解为三个关系模式:
-
R1(教师号,教师姓名,联系电话):描述教师的基本信息。
-
R2(课程号,课程名):描述课程的基本信息。
-
R3(教师号,课程号):描述教师与课程的关联。
这种分解处理解决了数据冗余和操作异常问题,同时也保留了必要的信息。但它可能增加了查询操作的复杂性,因为复杂的查询可能需要对这些关系进行连接操作。
关系模式分解的依据:
关系模式的合适分解依赖于数据依赖,尤其是函数依赖。在上述例子中:
- 教师姓名和联系电话函数依赖于教师号。
- 课程名函数依赖于课程号。
理解这些依赖关系有助于确定如何分解关系模式以减少数据冗余和操作异常。
好的关系数据库模式设计应该最小化数据冗余,避免各种操作异常,同时保证数据的完整性和一致性。正确地应用规范化理论,识别和利用数据依赖,是达到这些目标的关键。在实际应用中,还需要考虑查询效率和数据操作的便捷性,以实现数据模型与应用需求之间的最佳平衡。