python爬虫导论
文章目录
- 爬虫-导论+抓包
-
- 统一资源定位符
- DNS:域名解析服务
- 请求
-
- 静态请求
- 请求报头
- 动态请求
- 请求行 + 报头 + 请求报文
- 反爬手段
- vscode断点
-
- 检测
- 保存响应报文
- 可能遇到的问题
-
- 编码终端不同导致无法打印res.text
- 远程服务器返回的登录校验码
- json序列化()json
-
- 获取数据
- 抓包
-
- F12打开的开发者工具介绍
- 重点关注
爬虫-导论+抓包
统一资源定位符
https://www.baidu.com
资源路径:域名之后 ? 之前
https://www.baidu.com/s?wd=手机(关键词)&pn=20(页码为3)
搜索字符串为?之后,有载荷
DNS:域名解析服务

可直接通过红色框部分访问百度首页
浏览器所呈现的页面不是由一个请求构造而成
请求
静态请求
网址导航栏输入的网址+html文件里面各种链接
文档下面找
get
状态码 200-300 响应正常 300~400 重定向 400-500 被反爬 500远程服务器本身的问题
请求报头
user-agent 用户代理 写死的,不会变化的
cookie 身份标识符 反爬的一种手段
referer 同一个域名之下哪一个页面跳转过来的
content-type 请求报文的类型
动态请求
javascrit 原生的通信架构 XMLHttpRequest | Fetch |jquery
Fetch/XHR找
请求行 + 报头 + 请求报文
反爬手段
报头–cookie referer 响应报文-js
fiddler模拟请求的原理:解析复制并发送浏览器发送请求包(远程服务器到底有没有做反爬校验)
浏览器发送的请求报文与fiddler所发送的请求报文一致
重要:user-agent cookie
vscode断点
继续:程序持续运行,直到下一处断点,或者程序运行完成,退出进程
单步跳过:步进,不会进入函数内部,直接运行到下一行代码
单步调试:步入,当遇到执行函数的时候,进入函数内部,否则运行到下一行代码
单步跳出:当在函数内部时,直接跳出当前函数
检测
检测状态码 res.status_code
检测响应报文类型 res.headers.get(‘content-type’)
检测目标数据是否在响应报文里面’目标数据’ in res.text
保存响应报文
在保存的文件的根目录里面,开启cmd,在cmd里面使用python开启http服务,浏览器访问 python -m http.server 1234
可能遇到的问题
编码终端不同导致无法打印res.text
方法一:选择code编码或者python运行
方法二:
print(res.text.encode('utf8',errors='ignore').decode('utf-8',errors='ignore'))
远程服务器返回的登录校验码
Session,token
json序列化()json
代码为:
json.dumps(data)
中文会被编码
不序列化会导致响应400
获取数据
res.text #查看响应内容,返回的是Unicode格式的数据
res.json()
res.content#查看响应内容,返回字节流数据
res.url#查看完整url地址
res.encoding#查看响应头部字符编码
抓包
F12打开的开发者工具介绍
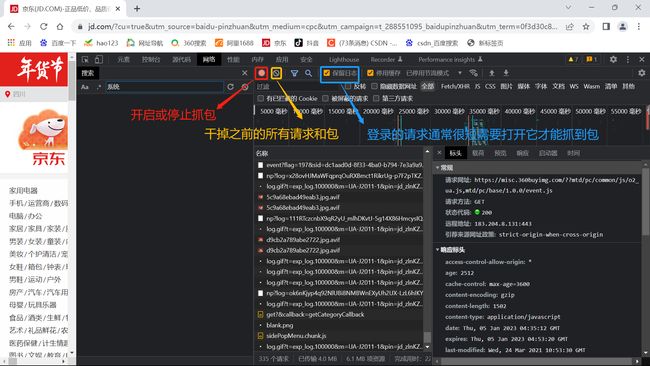
重点关注
-
网站首页一般为域名为名字的包
-
请求标头
