Mesi协议与内存屏障
Mesi协议和内存屏障都是和计算机并发相关的概念。
什么是Mesi协议
计算机存储分层
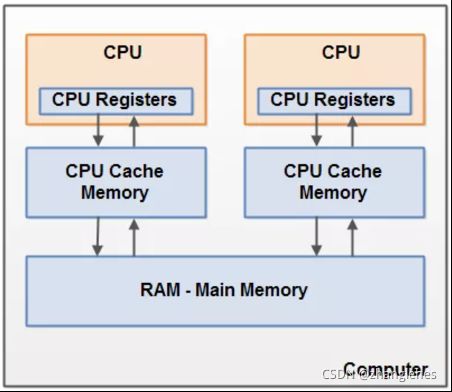

多核cpu带来的问题
而随着CPU的发展,CPU逐渐发展成了多核,CPU可以同时使用多个核心控制器执行线程任务,当然CPU处理同时处理线程任务的速度也越来越快了,但随之也产生了一个问题,多核CPU每个核心控制器工作的时候都会有自己独立的CPU缓存,每个核心控制器都执行任务的时候都是操作的自己的CPU缓存,CPU1与CPU2它们之间的缓存是相互不可见的。
解决这个问题的根本其实就是需要一种机制来保证一个人修改了内存数据后另外几个缓存了该共享变量的人可以感知到,那么就可以保证各个缓存之间的数据一致性了。
总线锁模型
如果想要每个CPU的缓存数据一致,那么最直接的办法就是同时只允许一个人修改内存的数据,当前面一个人操作结束之后,然后 通知其它缓存了该共享变量的缓存,通过这种串行化的方式加上通知机制来保证各个缓存之间的数据一致性,这也就是总线锁的思路。
总线锁模型带来的问题就是效率较低,一个指令周期只允许一个cpu进行内存的读写操作。
Mesi协议解决的问题
与总线锁模型类似,Mesi协议也是一种缓存一致性协议,但更高效。
在cpu读写数据时,需要确保同一数据在多个cache中是一致的。在写之前必须先让其他 CPU cache 中的该数据失效,之后才可以安全的写数据。
Mesi协议简介
cache line的四种状态
M : modified(独占且已更改的数据)
E : exclusive(独占且未更改的数据)
S : shared(共享数据,只读)
I : invalid(无效数据)
|
|
cacheline数据 |
memory数据 |
直接写数据 |
|
| modified |
是 |
最新 |
最新 |
可以 |
| exclusive |
是 |
最新 |
最新 |
可以 |
| shared |
否 |
最新 |
最新 |
不可以 |
| invalid |
否(无数据) |
无数据 |
最新 |
无数据 |
Mesi协议消息
- Read。"read" 消息用来获取指定物理地址上的 cache line 数据。
- Read Response。该消息携带了 “read” 消息所请求的数据。read response 可能来自于 memory 或者是其他 CPU cache。
- Invalidate。该消息将其他 CPU cache 中指定的数据设置为失效。该消息携带物理地址,其他 CPU cache 在收到该消息后,必须进行匹配,发现在自己的 cache line 中有该地址的数据,那么就将其从 cahe line 中移除,并响应 Invalidate Acknowledge 回应。
- Invalidate Acknowledge。该消息用做回应 Invalidate 消息。
- Read Invalidate。该消息中带有物理地址,用来说明想要读取哪一个 cache line 中的数据。这个消息还有 Invalidate 消息的效果。其实该消息是 read + Invalidate 消息的组合,发送该消息后 cache 期望收到一个 read response 消息。
- Writeback。 该消息带有地址和数据,该消息用在 modified 状态的 cache line 被置换时发出,用来将最新的数据写回 memory 或其他下一级 cache 中。
状态转化图

- cache 通过 writeback 将数据回写到 memory 或者下一级 cache 中。这时候状态由 modified 变成了 exclusive 。
- cpu 直接将数据写入 cache line ,导致状态变为了 modified 。
- CPU 收到一个 read invalidate 消息,此时 CPU 必须将对应 cache line 设置成 invalid 状态 , 并且响应一个 read response 消息和 invalidate acknowledge 消息。
- CPU 需要执行一个原子的 readmodify-write 操作,并且其 cache 中没有缓存数据。这时候 CPU 就会在总线上发送一个 read invalidate 消息来请求数据,并试图独占该数据。CPU 可以通过收到的 read response 消息获取到数据,并等待所有的 invalidate acknowledge 消息,然后将状态设置为 modifie 。
- CPU需要执行一个原子的readmodify-write操作,并且其local cache中有read only的缓存数据(cacheline处于shared状态),这时候,CPU就会在总线上发送一个invalidate请求其他cpu清空自己的local copy,以便完成其独自霸占对该数据的所有权的梦想。同样的,该cpu必须收集所有其他cpu发来的invalidate acknowledge之后才能更改状态为 modified。
- 在本cpu独自享受独占数据的时候,其他的cpu发起read请求,希望获取数据,这时候,本cpu必须以其local cacheline的数据回应,并以read response回应之前总线上的read请求。这时候,本cpu失去了独占权,该cacheline状态从Modified状态变成shared状态(有可能也会进行写回的动作)。
- 这个迁移和f类似,只不过开始cacheline的状态是exclusive,cacheline和memory的数据都是最新的,不存在写回的问题。总线上的操作也是在收到read请求之后,以read response回应。
- 如果cpu认为自己很快就会启动对处于shared状态的cacheline进行write操作,因此想提前先霸占上该数据。因此,该cpu会发送invalidate敦促其他cpu清空自己的local copy,当收到全部其他cpu的invalidate acknowledge之后,transaction完成,本cpu上对应的cacheline从shared状态切换exclusive状态。还有另外一种方法也可以完成这个状态切换:当所有其他的cpu对其local copy的cacheline进行写回操作,同时将cacheline中的数据设为无效(主要是为了为新的数据腾些地方),这时候,本cpu坐享其成,直接获得了对该数据的独占权。
- 其他的CPU进行一个原子的read-modify-write操作,但是,数据在本cpu的cacheline中,因此,其他的那个CPU会发送read invalidate,请求对该数据以及独占权。本cpu回送read response”和“invalidate acknowledge”,一方面把数据转移到其他cpu的cache中,另外一方面,清空自己的cacheline。
- cpu想要进行write的操作但是数据不在local cache中,因此,该cpu首先发送了read invalidate启动了一次总线transaction。在收到read response回应拿到数据,并且收集所有其他cpu发来的invalidate acknowledge之后(确保其他cpu没有local copy),完成整个bus transaction。当write操作完成之后,该cacheline的状态会从Exclusive状态迁移到Modified状态。
- 本CPU执行读操作,发现local cache没有数据,因此通过read发起一次bus transaction,来自其他的cpu local cache或者memory会通过read response回应,从而将该 cache line 从Invalid状态迁移到shared状态。
- 当cache line处于shared状态的时候,说明在多个cpu的local cache中存在副本,因此,这些cacheline中的数据都是read only的,一旦其中一个cpu想要执行数据写入的动作,必须先通过invalidate获取该数据的独占权,而其他的CPU会以invalidate acknowledge回应,清空数据并将其cacheline从shared状态修改成invalid状态。
内存屏障
复杂的CPU架构
store buffer
当cpu执行一条write操作时,需要先发送一条invalidate消息,其他所有的 CPU 在收到这个 Invalidate 消息之后,需要将自己 CPU local cache 中的该数据从 cache 中清除,并且发送消息 acknowledge 告知 CPU 0。CPU 0 在收到所有 CPU 发送的 ack 消息后会将数据写入到自己的 local cache 中。
这里就产生了性能问题:当 CPU 0 在等待其他 CPU 的 ack 消息时是处于停滞的(stall)状态,大部分的时间都是在等待消息。为了提高性能就引入的 Store Buffer。

store buffer 的目的是让 CPU 不再操作之前进行漫长的等待时间,而是将数据先写入到 store buffer 中,CPU 无需等待可以继续执行其他指令,等到 CPU 收到了 ack 消息后,再从 store buffer 中将数据写入到 local cache 中。
Store Forward
Store Buffer 的确提高了CPU的资源利用率,不过优化了带来了新的问题。在新数据存储在Store Buffer里时,如果此时有一条read指令,若仍旧从cache中读取数据时,读到的是旧的数据。要解决这个问题就必须要求CPU读取数据时得先看Store Buferes里面有没有,如果有则直接读取Store Buferes里的值,如果没有才能读取自己缓存里面的数据,这也就是所谓的“Store Forward”。
Invalidate Queue
CPU其实不需要完成invalidate操作就可以回送acknowledge消息,这样,就不会阻止发生invalidate请求的那个CPU进入无聊的等待状态。CPU可以buffer这些invalidate message(放入Invalidate Queues),然后直接回应acknowledge,表示自己已经收到请求,随后会慢慢处理。

一旦将一个invalidate(例如针对变量a的cacheline)消息放入CPU的Invalidate Queue,实际上该CPU就等于作出这样的承诺:在处理完该invalidate消息之前,不会发送任何相关(即针对变量a的cacheline)的MESI协议消息。
内存屏障保障缓存的一致性
内存屏障可以简单的认为它就是用来禁用我们的CPU缓存优化的,使用了内存屏障后,写入数据时候会保证所有的指令都执行完毕,这样就能保证修改过的数据能即时的暴露给其他的CPU。在读取数据的时候保证所有的“无效队列”消息都已经被读取完毕,这样就保证了其他CPU修改的数据消息都能被当前CPU知道,然后根据Invalid消息判断自己的缓存是否处于无效状态,这样就读取数据的时候就能正确的读取到最新的数据。
写屏障(write memory barrier)
当CPU执行load memory barrier指令的时候,强制其后的store指令,一定是在写屏障之前的所有store指令完成之后,才允许执行。为了达到这个目标有两种方法:方法一就是让CPU stall,直到完成了清空了store buffer(也就是把store buffer中的数据写入cacheline了)。方法二是让CPU可以继续运行,不过需要在store buffer中做些文章,也就是要记录store buffer中数据的顺序,在将store buffer的数据更新到cacheline的操作中,严格按照顺序执行,即便是后来的store buffer数据对应的cacheline已经ready,也不能执行操作,要等前面的store buffer值写到cacheline之后才操作。
读屏障(load memory barrier)
当CPU执行load memory barrier指令的时候,对当前Invalidate Queue中的所有的entry进行标注,这些被标注的项次被称为marked entries,而随后CPU执行的任何的load操作都需要等到Invalidate Queue中所有marked entries完成对cacheline的操作之后才能进行。
小结
Memory barrier其实是解决复杂(优化后)cpu架构带来的新问题。它连同Mesi协议一起保障并发程序中数据缓存的一致性。
后续的问题
1、mutex的实现方式
2、memory order
参考文献
1、带你了解缓存一致性协议 MESI
2、内存屏障(Memory Barrier)究竟是个什么鬼? - 知乎
3、并发理论基础:并发问题产生的三大根源 - 知乎
4、并发基础理论:缓存可见性问题、MESI协议、内存屏障 - 知乎