Hive查询之函数(二)
炸裂函数
把一个容器的多个数据炸裂出单独展示: explode(容器)
炸裂函数配合侧视图使用如下
格式:select 原表别名.字段名,侧视图名.字段名 from 原表 原表别名 lateral view explode(要炸开的字段) 侧视图名 as 字段名 ;
-- UDTF: 一进多出
select explode(array('binzi', '666', '888'));
select explode(map('a', 1, 'b', 2, 'c', 3));实战
-- 将NBA总冠军球队数据使用explode进行拆分,并且根据夺冠年份进行倒序排序。
--step1:建表
create table the_nba_championship(
team_name string,
champion_year array
) row format delimited
fields terminated by ','
collection items terminated by '|';
--step2:加载数据文件到表中 先上传到hdfs/source目录
load data inpath '/source/The_NBA_Championship.txt' into table the_nba_championship;
--step3:验证
select * from the_nba_championship;
-- 只查询冠军年份,降序排序
select explode(champion_year) as year from the_nba_championship ;
-- 配合侧视图完成需求
with tmp as(
select a.team_name,b.year
from the_nba_championship a
lateral view explode(champion_year) b as year
)
select * from tmp order by year desc; 收集函数
collect_set(字段名): 把多个数据收集到一起,默认去重
collect_list(字段名): 把多个数据收集到一起,默认不去重
把多个子串用指定分隔符拼接成一个大字符串: concat_ws(分隔符,多个数据...) 注意: 如果拼接数据不是字符串可以使用cast转换
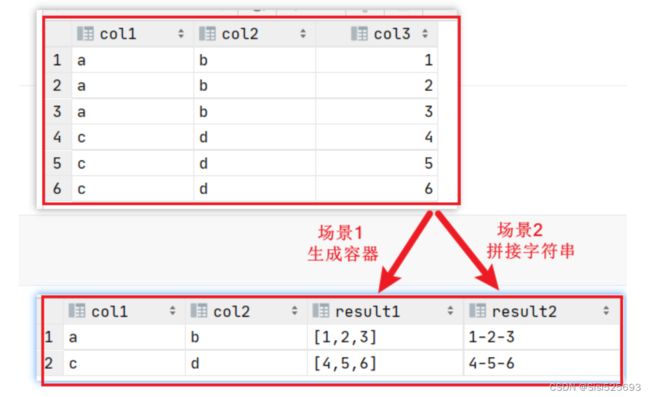
列转行
-- 数据准备
--建表
create table row2col2(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\t';
--加载数据到表中
load data inpath '/source/r2c2.txt' into table row2col2;
-- 验证数据
select * from row2col2;
/*
需求1: 把原表数据变成以下格式
a b [1,2,3]
c d [4,5,6]
*/
select
col1,
col2,
collect_list(col3)
from
row2col2
group by
col1, col2;
/*
需求2: 把原表数据变成以下格式
a b '1-2-3'
c d '4-5-6'
*/
select
col1,
col2,
concat_ws('-',collect_list(cast(col3 as string)))
from
row2col2
group by
col1, col2;行转列
collect_set(字段名): 把多个数据收集到一起,默认去重
collect_list(字段名): 把多个数据收集到一起,默认不去重
把多个子串用指定分隔符拼接成一个大字符串: concat_ws(分隔符,多个数据...) 注意: 如果拼接数据不是字符串可以使用cast转换

-- 数据准备
--建表
create table row2col2(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\t';
--加载数据到表中
load data inpath '/source/r2c2.txt' into table row2col2;
-- 验证数据
select * from row2col2;
/*
需求1: 把原表数据变成以下格式
a b [1,2,3]
c d [4,5,6]
*/
select
col1,
col2,
collect_list(col3)
from
row2col2
group by
col1, col2;
/*
需求2: 把原表数据变成以下格式
a b '1-2-3'
c d '4-5-6'
*/
select
col1,
col2,
concat_ws('-',collect_list(cast(col3 as string)))
from
row2col2
group by
col1, col2;JSON文件处理
get_json_object: 获取json对象解析对应数据 一次只能提取一个字段
json_tuple: 直接获取json对应数据 这是一个UDTF函数 可以一次解析提取多个字段
注意: 因为json_tuple是UDTF函数,所以也可以配合侧视图使用
-- 演示json解析
-- 需求: 把json解析后的数据保存成一个新表
--创建表
create table tb_json_test1 (
json string
);
--加载数据
load data inpath '/source/device.json' into table tb_json_test1;
-- 查看数据
select * from tb_json_test1;
-- 方式1: 逐个(字段)处理, get_json_object UDF函数 最大弊端是一次只能解析提取一个字段
-- get_json_object UDF函数 最大弊端是一次只能解析提取一个字段
create table device1 as
select
--获取设备名称
get_json_object(json,"$.device") as device,
--获取设备类型
get_json_object(json,"$.deviceType") as deviceType,
--获取设备信号强度
get_json_object(json,"$.signal") as signal,
--获取时间
get_json_object(json,"$.time") as stime
from tb_json_test1;
-- 方式2: 逐条处理. json_tuple 这是一个UDTF函数 可以一次解析提取多个字段
--json_tuple 这是一个UDTF函数 可以一次解析提取多个字段
--单独使用 解析所有字段
create table device2 as
select
json_tuple(json,"device","deviceType","signal","time") as (device,deviceType,signal,stime)
from tb_json_test1;
--搭配侧视图使用(本次了解)
select
device,deviceType,signal,stime
from tb_json_test1
lateral view json_tuple(json,"device","deviceType","signal","time") b
as device,deviceType,signal,stime;
-- 方式3: 在建表时候, 直接处理json, row format SerDe '能处理Json的SerDe类'
--建表的时候直接使用JsonSerDe解析
create table tb_json_test2 (
device string,
deviceType string,
signal double,
`time` string
)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TEXTFILE;
-- 加载数据
load data inpath '/source/device.json' into table tb_json_test2;
-- 查看
select * from tb_json_test2;
开窗函数
基础使用
开窗函数格式: select ... 开窗函数 over(partition by 分组字段名 order by 排序字段名 asc|desc) ... from 表名;
聚合开窗函数: 原来学的聚合函数(max,min,sum,count,avg)配合over()使用的时候,这些聚合函数也可以叫开窗函数
排序开窗函数: row_number dense_rank rank
row_number: 巧记: 1234 特点: 唯一且连续
dense_rank: 巧记: 1223 特点: 并列且连续
rank : 巧记: 1224 特点: 并列不连续
-- 开窗函数: hive和mysql8都能使用
-- 开窗函数本质在表后新增了一列
-- 聚合开窗函数: max min sum avg count
-- 聚合函数配合over()使用,也可以叫开窗函数
select col1,
max(col3) over()
from row2col2;
-- 排序开窗函数: row_number rank dense_rank
-- 排序函数必须配合over(order by 排序字段 asc|desc)
/*
row_number: 巧记: 1234 特点: 唯一且连续
dense_rank: 巧记: 1223 特点: 并列且连续
rank : 巧记: 1224 特点: 并列不连续
*/
select *,
row_number() over (order by signal desc),
dense_rank() over (order by signal desc),
rank() over (order by signal desc)
from device1;
-- 开窗函数分组
-- 注意不能用group by ,需要使用partition by,可以理解成partition by是group by的子句
-- 演示排序函数和分组配合使用: 先分组再组内排序
select *,
row_number() over (partition by deviceType order by signal desc),
dense_rank() over (partition by deviceType order by signal desc),
rank() over (partition by deviceType order by signal desc)
from device1;
-- 演示聚合函数和分组配合使用
select *,
max(signal) over(partition by deviceType)
from device1;
-- 演示聚合函数同时和分组以及排序关键字配合使用
--需求:求出每个用户截止到当天,累积的总pv数
---建表并且加载数据
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
-- 建表
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
-- 加载数据 直接上传website_pv_info.txt和website_url_info.txt到hdfs中指定表路径中
-- 查询数据
select * from website_pv_info;
select * from website_url_info;
--需求:求出每个用户截止到当天,累积的总pv数
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select cookieid, createtime, pv,
sum(pv) over(partition by cookieid order by createtime) as current_total_pv
from website_pv_info;开窗函数控制范围
开窗函数控制范围: rows between
- unbounded: 无界限
- x preceding:往前x行
- x following:往后x行
- current row:当前行
- unbounded preceding :表示从前面的起点 第一行
- unbounded following :表示到后面的终点 最后一行
-- 演示窗口范围的控制
/*
rows between
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点 第一行
- unbounded following:表示到后面的终点 最后一行
*/
--默认从第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1
from website_pv_info;
--第一行到当前行 等效于rows between不写 默认就是第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;其他开窗函数
其他开窗函数: ntile lag和lead first_value和last_value
ntile(x)功能: 将分组排序之后的数据分成指定的x个部分(x个桶)
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。lag: 用于统计窗口内往上第n行值
lead:用于统计窗口内往下第n行值first_value: 取分组内排序后,截止到当前行,第一个值
last_value : 取分组内排序后,截止到当前行,最后一个值注意: 窗口函数结果都是单独生成一列存储对应数据
-- 演示其他函数
-- 演示ntile
--把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
ntile(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;
--lag 用于统计窗口内往上第n行值
select cookieid, createtime, url,
row_number() over (partition by cookieid order by createtime) rn,
lag(createtime, 1) over (partition by cookieid order by createtime) la1,
lag(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;
--lead 用于统计窗口内往下第n行值
select cookieid, createtime, url,
row_number() over (partition by cookieid order by createtime) rn,
lead(createtime, 1) over (partition by cookieid order by createtime) la1,
lead(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;
--FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
select cookieid, createtime, url,
row_number() over (partition by cookieid order by createtime) rn,
first_value(url) over (partition by cookieid order by createtime) fv
from website_url_info;
--LAST_VALUE 取分组内排序后,截止到当前行,最后一个值
select cookieid, createtime, url,
row_number() over (partition by cookieid order by createtime) rn,
last_value(url) over (partition by cookieid order by createtime rows between unbounded preceding and unbounded following) fv
from website_url_info;