【目标检测】YOLOv1 ,one-stage 目标检测算法的开山之作
目录
-
- 一、YOLOv1简介
- 二、YOLOv1网络结构
- 三、YOLOv1的损失函数
- 四、YOLOV1的不足
- 五、YOLOv1的预测
- 六、推荐参考资料
一、YOLOv1简介
YOLO 是 You Only Look Once 的缩写,意思是神经网络只需要看一次图片,就能输出结果。其创新点如下:
(1)YOLO是一个端到端的目标检测框架,将整张图作为网络的输入,直接在输出层回归出候选框的位置和类别。
(2)速度快,但准确度相对低一些。主要用于实时检测,例如视频目标检测。
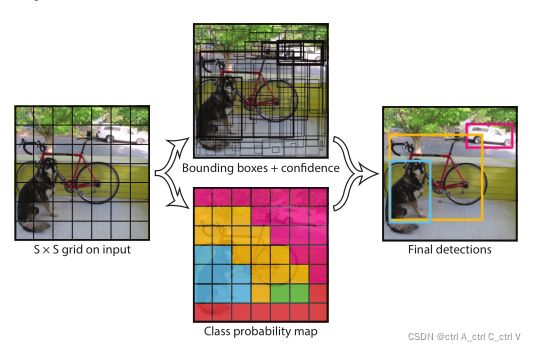
但 one-stage并不意味着YOLO去掉了生成候选框的步骤,而是将输入图像直接划分为 S×S 个网格(grid),取S =7,,即划分成 7×7=49 个网格,每个网格预测 B个边界框,取B=2,一共预测 49×2=98个边界框。
可以近似理解为在输入图片上粗略选取98个候选区,这些候选区覆盖了整张图片,然后用回归预测这98个候选区域对应的边界框。
如果目标的中心落入网格单元,则该网格单元负责检测该目标。注意不是整个物体落入单元格,只需要物体中心在即可。

二、YOLOv1网络结构
YOLOv1网络结构如下:
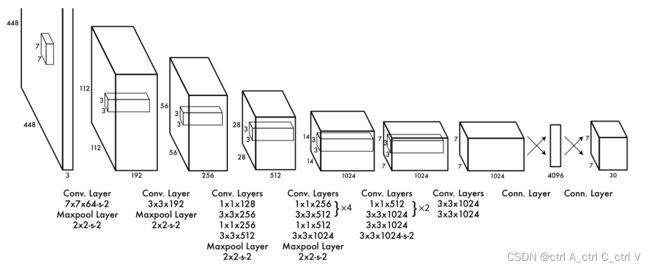
YOLOv1输入 [448, 448, 3] 的图像,经过一个修改的GoogLeNet网络,后面接一些全连接层,最后接到一个 [1470, 1] 的全连接层,再reshape为 [7, 7, 30]
这里 [7, 7, 30] 的7×7是因为一张图片有 7×7 个网格,30是指每个网格有30个输出。30 = 2 × (4+1)+20,其中2是指每个网格预测两个候选框,4是指每个候选框的 (x,y,w,h)四个参数,1是指每个候选框的置信度(候选框与真实标注框的 IOU值),20是指Psacal VOC数据集有20个分类(不包含背景)。
其中(x,y)是候选框中心相对于网格单元的坐标,w 和 h 是候选框框相当于整幅图的宽和高,都是相对于网格来说的,而不是整张图像。
三、YOLOv1的损失函数
可以发现,一张图像产生有个先验框,但最终有用的先验框(和GT,Ground Truth 比较吻合的)可能只能个别几个。如下图所示,红色表示GT框,黄色表示有用的先验框;那么只有三个先验框是有用的。

训练和预测时候筛选先验框方法不同,预测时需要进行非极大值抑制(NMS),而训练时不需要。
YOLOv1的损失函数为:

其含义为:
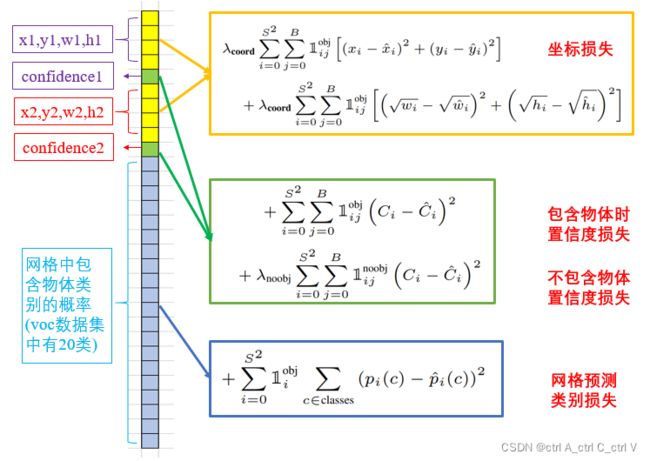
现在把它们分开来讲:
(1)坐标预测
第一部分:(x,y)预测

第二部分:(w,h)预测
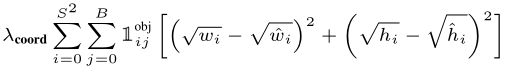
这里加上根号表示大边界框小偏差应该比小边界框小偏差更重要具体解释可以看b站up主”霹雳吧啦Wz“的视频讲解。
其中与object的GT框的IOU值最大的先验框负责该object,所以根据公式,不负责该object的先验框的权重为0,不参与loss计算。
(2)置信度预测
第一部分:包含物体的边界框的置信度预测
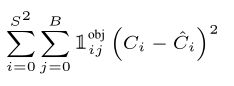
第二部分:不包含物体的边界框的置信度预测

由于一幅图片中大部分网格中是没有物体的,这些网格中的边界框的置信度为0,相比于有物体的网格,这些不包含物体的网格更多,多梯度更新的贡献更大,会导致网络不稳定。为了平衡该问题,损失函数对没有物体的边界框的置信误差赋予较小的权重,即 λ \lambda λnoobj=0.5,对包含物体的边界框的置信误差赋予权重为1(训练Pascal VOC数据集时)。
(3)分类预测
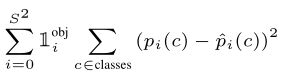
四、YOLOV1的不足
由于YOLOV1的框架设计,该网络存在以下缺点:
(1)每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。
(2)原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。
(3)最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
(4)对于图片中比较小的物体尤其是密集的小物体,效果比较差。这其实是所有目标检测算法的通病。
五、YOLOv1的预测
现在考虑这样一个问题,数据集中共有20个分类,假设我们要推理的某张图片中共有10个object应该被检测到,那么就应该回归十个候选框。YOLOv1生成了98个候选框,那么如何从这98个框中选取10个合适的框呢?可以考虑以下两种方法:
(1)聚类:
将所有候选框聚成10类,在这10个类中,选择每个类中confidence(置信度)最大的框作为最终的结果。
听起来不错,但是这个方法是有问题的。2个很接近的目标聚成了1个类怎么办?还有我们事先并不知道图片中有几个目标,那么为何聚成10类呢?而不是5类呢?
(2)NMS(非极大值抑制):
2个框重合度很高,大概率是一个目标,那就只取一个框。即选取与真实标注框IOU值最大的候选框,去掉其他候选框。
2个目标本身比较近怎么办?依然没有解决。如果不知道到底有几个目标呢?NMS自动解决了这个问题。
对比起来看,似乎NMS更好一点,YOLOv1预测时用的正是NMS算法。YOLOv1网格输出的Tensor大小为 [7, 7, 30] ,表示图片中每个网格对应的可能的两个边界框以及每个边界框的置信度和包含的对象属于各个类别的概率。由此可以计算某对象i属于类别同时在第j个边界框中的得分为:
![]()
每个网格有20个类条件概率,2个边界框置信度,相当于每个网格有40个得分,7x7个网格有1960个得分,每类对象有1960/20=98个得分,即98个候选框。
NMS步骤如下:
(1)设置一个置信度的阈值,一个IOU的阈值。
(2)对于每类对象,遍历属于该类的所有候选框。
① 过滤掉置信度低于置信度阈值的候选框。
② 找到剩下的候选框中最大置信度对应的候选框,添加到输出列表;
③ 进一步计算剩下的候选框与②中输出列表中每个候选框的IOU,若该IOU大于设置的IOU阈值(即重合度高于IOU阈值),将该候选框过滤掉,否则加入输出列表中。
④ 最后输出列表中的候选框即为图片中该类对象预测的所有边界框。
(3)返回步骤2继续处理下一类对象。
关于YOLOv1的预测过程和NMS算法的通俗解释可以参考 YOLOv1(预测过程)
六、推荐参考资料
你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上) 这篇文章深入浅出,从简单的目标检测非常自然地引入了多目标、小目标检测,再引入YOLOv1,写的特别好。