python租房数据分析可视化系统+爬虫+Flask框架 大数据 毕业设计(免费源码)✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。
1、项目介绍
Python租房数据分析可视化系统 爬虫
Flask框架、Layui前端框架、Echarts可视化、requests爬虫、MySQL数据库
本程序使用python编写,后端采用Flask框架,采用Layui前端框架,数据库采用mysql设计,echarts进行数据可视化显示。
(1)通过查阅大量国内外相关文献,首先详细阐述了本课题的研究背景、研究原因及方向、国内外研究发展进程,介绍了本文的主要研究内容并对章节结构进行安排。
(2)研究并学习了本文相关的理论基础与技术,例如数据分析、机器学习算法、MySQL数据库、网络爬虫技术以及ECharts框架等,并对其进行简要介绍。
(3)从实际出发,分析系统功能需求与非功能需求,设计系统架构与数据库,确定本系统的七大功能模块,即数据获取、注册登录、修改信息、数据概况展示、数据可视化、智能预测、网站接入以及其他小功能模块。
(4)对各个功能模块进行详细实现,说明各个模块前后端是如何进行数据交互的并对核心代码进行简单介绍。
(5)在初步实现各个功能模块的基础之上进行系统测试与维护,测试程序代码的健壮性,不断完善系统功能。
通过该项目的锻炼,让我对网络爬虫技术、数据分析、机器学习算法模型、ECharts可视化图表库、Layui框架有了更深层次的认识,提升了编写与测试代码的能力,为以后在人工智能应用领域的研究工作奠定了基础。
2、项目界面
(1)租房数据可视化分析
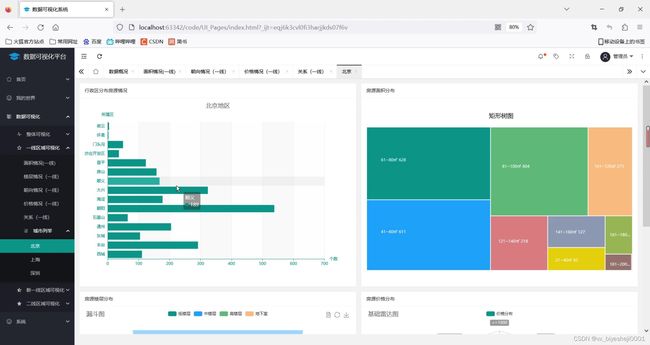
(2)房屋朝向分析1

(3)房屋朝向分析2

(4)租房数据

(5)租房数据散点图

(6)租房价格分布

(7)注册登录界面
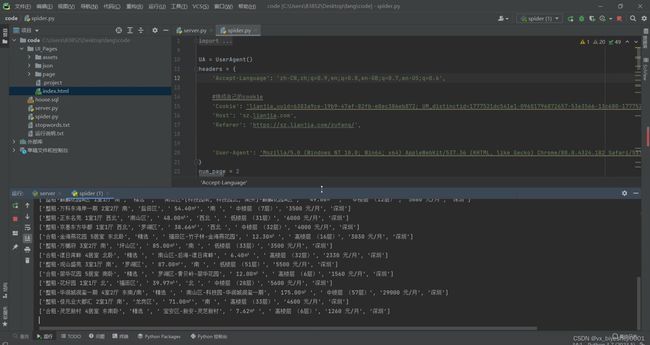
(8)数据爬取
3、项目说明
本文从系统的初步设想、到规划设计、再到详细实现均旨在能够基本解决应届毕业生面临的两大难题,即就业与房房价。本文的主要工作就是挖掘拉勾网和链家网海量数据潜在的价值,并通过清晰明了、直观化的图表进行可视化展示从而帮助应届毕业生们对目前全国各个区域的就业岗位情况与房房价房源情况进行全面了解,有助于结合自身情况做出适合自己的选择。本系统采用Python语言进行编写,利用PyCharm开发平台及轻量级开源模块化的web应用框架Layui,进而完成系统各个功能模块。本文主要完成的具体工作如下:
(1)通过查阅大量国内外相关文献,首先详细阐述了本课题的研究背景、研究原因及方向、国内外研究发展进程,介绍了本文的主要研究内容并对章节结构进行安排。
(2)研究并学习了本文相关的理论基础与技术,例如数据分析、机器学习算法、MySQL数据库、网络爬虫技术以及ECharts框架等,并对其进行简要介绍。
(3)从实际出发,分析系统功能需求与非功能需求,设计系统架构与数据库,确定本系统的七大功能模块,即数据获取、注册登录、修改信息、数据概况展示、数据可视化、智能预测、网站接入以及其他小功能模块。
(4)对各个功能模块进行详细实现,说明各个模块前后端是如何进行数据交互的并对核心代码进行简单介绍。
(5)在初步实现各个功能模块的基础之上进行系统测试与维护,测试程序代码的健壮性,不断完善系统功能。
通过该项目的锻炼,让我对网络爬虫技术、数据分析、机器学习算法模型、ECharts可视化图表库、Layui框架有了更深层次的认识,提升了编写与测试代码的能力,为以后在人工智能应用领域的研究工作奠定了基础。
4、核心代码
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time
import pandas as pd
import random
import pymysql
from sqlalchemy import create_engine
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
num_page = 2
class Lianjia_Crawer:
def __init__(self, txt_path):
super(Lianjia_Crawer, self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(columns = ['title', 'district', 'area', 'orient', 'floor', 'price', 'city'])
def run(self):
'''启动脚本'''
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3306", "hosue")
engine = create_engine(connect_info)
for i in range(100):
url = "https://sz.lianjia.com/zufang/pg{}/".format(str(i)) #可以改为全国任意城市,上面的也要一起改
# url = "https://gz.lianjia.com/zufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2, 5))
print('正在爬取的 url 为 {}'.format(url))
print('爬取完毕!!!!!!!!!!!!!!')
self.df.to_csv(self.file, encoding='utf-8')
print('租房信息已保存至本地')
self.df.to_sql(name='house', con=engine, if_exists='append', index=False)
print('租房信息已保存数据库')
def parse_url(self, url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
#声明pq对象
doc = pq(res.text)
for i in doc('.content__list--item .content__list--item--main'):
try:
pq_i = pq(i)
# 房屋标题
title = pq_i('.content__list--item--title a').text()
# 具体信息
houseinfo = pq_i('.content__list--item--des').text()
# 行政区
address = str(houseinfo).split('/')[0]
district = str(address).split('-')[0]
# 房屋面积
full_area = str(houseinfo).split('/')[1]
area = str(full_area)[:-1]
# 朝向
orient = str(houseinfo).split('/')[2]
# 楼层
floor = str(houseinfo).split('/')[-1]
# 价格
price = pq_i('.content__list--item-price').text()
#城市
city = '深圳'
data_dict = {'title': title, 'district': district, 'area': area, 'orient': orient, 'floor': floor, 'price': price, 'city': city}
self.df = self.df.append(data_dict, ignore_index=True)
print([title, district, area, orient, floor, price, city])
except Exception as e:
print(e)
print("索引提取失败,请重试!!!!!!!!!!!!!")
if __name__ =="__main__":
txt_path = "zufang_shenzhen.csv"
Crawer = Lianjia_Crawer(txt_path)
Crawer.run() # 启动爬虫脚本
5、源码获取方式
由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看获取联系方式