大模型日报-20240108
M(2)UGen:利用 LLM 理解和生成音乐
 https://github.com/shansongliu/M2UGen
https://github.com/shansongliu/M2UGen
M (2) UGen 模型是一种音乐理解和生成模型,能够从文本、图像、视频和音频中进行音乐问答和音乐生成,以及音乐编辑。该模型利用编码器,如用于音乐理解的 MERT、用于图像理解的 ViT、用于视频理解的 ViViT,以及作为音乐生成模型(音乐解码器)的 MusicGen/AudioLDM2 模型,再加上适配器和 LLaMA 2 模型,使模型能够实现多种能力。
李飞飞团队新作:AI透视眼,穿越障碍看清你,渲染遮挡人体有新突破了

https://mp.weixin.qq.com/s/ig0SCCG34xLidEKBMTBfog
AR/VR 、电影和医疗等领域都在广泛地应用视频渲染人类形象。由于单目摄像头的视频获取较为容易,因此从单目摄像头中渲染人体一直是研究的主要方式。Vid2Avatar、MonoHuman 和 NeuMan 等方法都取得了令人瞩目的成绩。尽管只有一个摄像头视角,这些方法仍能从新的视角准确地渲染人体。最近,著名人工智能教授李飞飞在 X 上发布了有关 3D 人体渲染工作的新进展 —— 一种名为 Wild2Avatar 的新模型,该模型即使在有遮挡的情况下仍然能够完整、高保真地渲染人体。
让机器人感知你的「Here you are」,清华团队使用百万场景打造通用人机交接
https://mp.weixin.qq.com/s/KcYNPfV93PB6lZQK8wTEzQ
来自清华大学交叉信息研究院的研究者提出了「GenH2R」框架,让机器人学习通用的基于视觉的人机交接策略(generalizable vision-based human-to-robot handover policies)。这种可泛化策略使得机器人能更可靠地从人们手中接住几何形状多样、运动轨迹复杂的物体,为人机交互提供了新的可能性。
快速筛选海量数据,即时做出明智决策,MIT、普林斯顿&卡内基梅隆大学团队利用LLM进行聚变研究

https://mp.weixin.qq.com/s/NtNW3ujUPJze6CAcqFL_aQ
可控核聚变能具有安全、清洁、燃料丰富等优点,是解决人类未来能源问题的主要选择之一。也许最有前途的核聚变装置是托卡马克(Tokamak)。尽管前景光明,但在人类和经济型托卡马克发电厂之间仍然存在重要的悬而未决的问题。现在,来自普林斯顿大学、卡内基梅隆大学(CMU)和麻省理工学院 (MIT) 的科学家已经应用大型语言模型(ChatGPT、Bard 和 LLaMA 等工具背后的驱动力)来帮助核聚变研究人员快速筛选数量惊人的数据,以便即时做出更明智的决策。该模型允许用户识别具有相似特征的先前实验,提供有关设备控制系统的信息,并快速返回有关聚变反应堆和等离子体物理学问题的答案。
VCoder
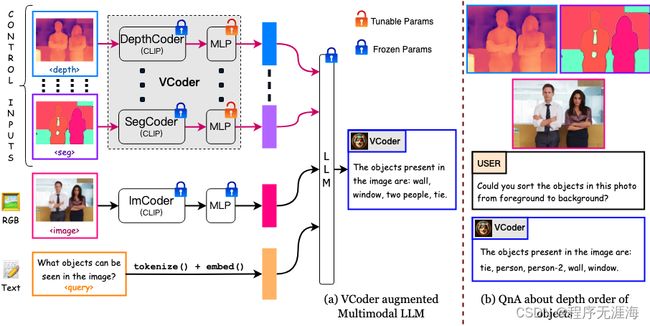
https://github.com/SHI-Labs/VCoder
团队研究建议使用通用视觉编码器 (VCoder) 作为多模态 LLM 的感知眼开发一个准确的 MLLM 感知和推理系统。并且为 VCoder 提供分割或深度图等感知模式,从而提高 MLLM 的感知能力。其次,利用来自 COCO 的图像和现成的视觉感知模型的输出来创建 COCO 分割文本 (COST) 数据集,用于在对象感知任务上训练和评估 MLLM。第三,在COST数据集上引入了指标来评估MLLM中的对象感知能力。通过大量的实验证据,证明 VCoder 提高了现有的多模态 LLM(包括 GPT-4V)对象级感知技能。
阿里云通义千问APP上线免费功能“通义舞王”
https://mp.weixin.qq.com/s/14WF1rI9qpDPlRbQawJ-rQ
最近,不少社交平台都被一种名为「科目三」的舞蹈视频刷屏了,摇花手、半崴不崴的脚,配合着节奏鲜明的音乐,这一舞蹈动作遭全网模仿。对于有点舞蹈功底的人来说,学会「科目三」并不是一件很难的事,但对于四肢不是很协调的小伙伴而言,这可真是有点难度了。为了让广大网友学会这个舞蹈,还有人出了保姆级分解教程,声称几分钟速成大摇子。其实,对于想要跳舞的你来说,根本不用真人出镜,一张照片就能化身舞蹈达人
如果LLM是巫师,那么代码就是魔杖:关于代码如何赋能大语言模型作为智能体的调查

链接:http://arxiv.org/abs/2401.00812v1
如今,突出的大语言模型(LLMs)与过去的语言模型不仅在规模上有所不同,还在于它们是基于自然语言和形式语言(代码)的组合进行训练的。作为人类和计算机之间的媒介,代码将高级目标转化为可执行步骤,具有标准语法、逻辑一致性、抽象和模块化特性。在本综述中,我们概述了将代码整合到LLMs的训练数据中所带来的各种好处。具体而言,在增强LLMs的代码生成能力之外,我们观察到代码的这些独特属性有助于(i)开启LLMs的推理能力,使其能够应用于更复杂的自然语言任务;(ii)引导LLMs产生结构化和精确的中间步骤,然后通过函数调用将其连接到外部执行端点;(iii)利用代码编译和执行环境,该环境还为模型改进提供了各种反馈。此外,我们追踪了代码带来的LLMs的这些深远能力如何使它们在能够理解指令、分解目标、计划和执行动作、并从反馈中进行改进的关键任务中成为智能体(IAs)。最后,我们提出了将LLMs赋能于代码的几个关键挑战和未来方向。
AI能否像人类一样有创造性?

链接:http://arxiv.org/abs/2401.01623v1
本文通过引入一个名为“相对创造力”的新概念,解决了定义和评估创造力所面临的复杂性问题。我们将重点转移到AI能否与一个假想人类的创造能力相匹配。这种观点受图灵测试的启发,扩展了图灵测试,以应对评估创造力中的挑战和主观性。这种方法学转变有助于对AI的创造力进行统计量化评估,我们称之为统计创造力。这种方法允许直接比较AI的创造能力与特定人群的创造能力。在此基础上,我们讨论了统计创造力在当代条件驱动的自回归模型中的应用。除了定义和分析创造力的度量标准外,我们还介绍了可行的训练指南,有效地弥合了创造力的理论量化和实际模型训练之间的差距。通过这些多方面的贡献,本文建立了一个连贯、不断发展和变革的框架,用于评估和培养AI模型的统计创造力。
人工智能中的合成数据:挑战、应用和伦理影响

链接:http://arxiv.org/abs/2401.01629v1
在快速发展的人工智能领域中,创建和利用合成数据集变得越来越重要。本报告探讨了合成数据的多方面特征,特别强调了这些数据集可能存在的挑战和潜在偏见。它探讨了合成数据生成的方法,涵盖了传统统计模型到先进的深度学习技术,并研究了它们在不同领域的应用。该报告还审视了与合成数据集相关的伦理考虑和法律责任,并强调了在人工智能开发中确保公平、减少偏见和维护伦理标准的机制的紧迫性。
MLP 指南针:MLP 在预训练语言模型里学习了什么?

链接:http://arxiv.org/abs/2401.01667v1
摘要:虽然基于Transformer的预训练语言模型及其变种展示了强大的语义表示能力,但对于理解从PLM的附加组件中获得的信息增益的问题仍然是一个未解之谜。受到最近证明多层感知器(MLPs)模块具有强大的结构捕捉能力,甚至胜过图神经网络(GNNs)的努力的启发,本文旨在量化简单的MLPs是否能进一步提升PLMs捕捉语言信息的潜力。具体而言,我们设计了一个简单而有效的探测框架,其中包含基于BERT结构的MLPs组件,并进行了涵盖三个不同语言层次的10个探测任务的广泛实验。实验结果表明,MLPs确实可以通过PLMs增强对语言结构的理解。我们的研究为利用MLPs打造多样化的PLMs变体,并强调多样的语言结构的任务提供了可解释且有价值的见解。
经过grounding 的 GPT-4V(ision)是一个通用的网络智能体

链接:http://arxiv.org/abs/2401.01614v1
在这项工作中,我们探索了像GPT-4V这样的LMM作为通用网络智能体的潜力,该智能体可以根据自然语言指令在任何给定的网站上完成任务。我们提出了SEEACT,一种利用LMM的力量进行集成视觉理解和网页操作的通用网络智能体。我们在最近的MIND2WEB基准测试上进行评估。除了对缓存网站进行标准离线评估外,我们还通过开发一种工具,使得网页智能体可以在实时网站上运行,启用了一种新的在线评估设置。我们展示了GPT-4V对网页智能体的巨大潜力-如果我们将其文本计划手动落实为网站上的操作,它可以成功完成50%的实时网站任务。这显著优于仅针对网页智能体微调的仅文本LMM,如GPT-4或较小的模型(FLAN-T5和BLIP-2)。然而,落实仍然是一个重要挑战。。
由浅入深了解Diffusion Model
https://zhuanlan.zhihu.com/p/525106459
本文详细介绍了扩散模型(Diffusion Model)的工作原理和应用。扩散模型通过逐步向图像添加高斯噪声,最终将图像转化为纯高斯噪声,然后通过逆向过程从噪声中恢复出原始图像。文章解释了扩散模型的前向过程(添加噪声)和逆向过程(去噪推断),以及如何通过深度学习模型预测逆向分布。此外,文章还探讨了扩散模型的训练方法,包括使用变分下界(VLB)来优化负对数似然。最后,文章讨论了加速扩散采样和方差选择的方法,如DDIM(Denoising Diffusion Implicit Models),以及如何通过牺牲多样性来换取更快的推断速度。
是什么让他成为现代计算机之父?丨纪念冯·诺伊曼诞辰120周年(下)
https://mp.weixin.qq.com/s/jsEIchz3LaRCaPrp_A3lXA
本文纪念冯·诺伊曼诞辰120周年,回顾了他在数学、理论物理、博弈论、数值计算、计算机理论和曼哈顿计划等领域的杰出贡献。冯·诺伊曼在量子理论的数学基础、统计力学、遍历定理、博弈论和自动机理论方面有重要工作,对电子计算机的设计与理论发展产生了深远影响。他在洛斯阿拉莫斯实验室的工作,特别是在核能和热核反应的数学处理上,展现了他将数学应用于实际问题的能力。冯·诺伊曼的工作体现了数学科学普适性和有机统一的理想,他的广泛兴趣和成就对后世产生了深远影响。
Record Once

https://recordonce.com/
Record Once 帮助改变 SaaS 公司的视频教程录制。视频录制过程中普遍遇到的问题是:因为录制过程中出现的小错误导致需要一遍又一遍地重新录制。而这就是 Record Once 诞生的原因,借助 AI Record Once 可以修复错误并自动编辑,用户只需录制一次教程,就可以在第一时间将自己的小错误得到处理。
Moodboard Creator
https://www.moodboardcreator.dev/
Moodboard creator 是创始人对 LLM API 的探索中诞生的 AI 实验的结果,是一个在品牌项目的灵感阶段帮助设计师的工具,借助 AI 简化创建视觉情绪板。通过生成原始情绪板而不是依赖互联网抓取的图像,该工具允许设计师整合平台提供的品牌元素。外部资源是从开源服务中获得的:Google Fonts 和 Pexels。
Flowgen
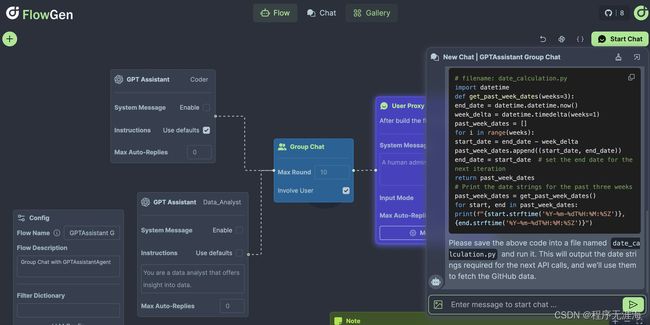
https://github.com/tiwater/flowgen
FlowGen是为AutoGen构建的工具,AutoGen是Microsoft和许多贡献者的出色代理框架。其提供了直观的可视化工具,简化了基于智能体的复杂工作流程的构建和监督,从而简化了创作者和开发人员的整个流程。