一次性讲清楚INNER JOIN、LEFT JOIN、RIGHT JOIN的区别和用法详解
文章目录
- Join查询原理
- Nested-Loop Join
- INNER JOIN、LEFT JOIN、RIGHT JOIN的区别
-
- INNER JOIN操作
- LEFT JOIN操作
- RIGHT JOIN操作
- 总结
- 参考
Join查询原理
查询原理:MySQL内部采用了一种叫做 Nested Loop Join(嵌套循环连接) 的算法。Nested Loop Join 实际上就是通过 驱动表的结果集 作为循环基础数据,然后一条一条的通过 该结果集 中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与 Join,则再通过前两个表的 Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复,基本上MySQL采用的是最容易理解的算法来实现join。所以驱动表的选择非常重要,驱动表的数据小可以显著降低扫描的行数。
一般情况下参与联合查询的两张表都会一大一小,如果是join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表。简单来说,驱动表就是主表,left join中的左表就是驱动表,right join中的右表是驱动表。
Nested-Loop Join
在Mysql中,使用Nested-Loop Join的算法思想去优化join,Nested-Loop Join翻译成中文则是“嵌套循环连接”。
mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种:
- Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
- Index Nested-Loop Join:INLJ,索引嵌套循环连接
- Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
在选择Join算法时,会有优先级,理论上会优先判断能否使用INLJ、BNLJ:Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
INNER JOIN、LEFT JOIN、RIGHT JOIN的区别
接下来通过例子帮助理解他们之间的区别
首先,我们创建示例数据库和表。同时也要明确一个概念:A INNER/LEFT/RIGHT JOIN B操作中,A表被称为左表,B表被称为右表。
创建示例数据库school,在数据库school下创建两张示例表:student、punishment。
创建学生基本信息表student,如下:

DROP TABLE IF EXISTS `punishment`;
CREATE TABLE `punishment` (
`student_id` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`punishment` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`student_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '学生违纪处罚记录表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of punishment
-- ----------------------------
INSERT INTO `punishment` VALUES ('201400002', '张三', '大过');
INSERT INTO `punishment` VALUES ('201400006', '杨智', '留校察看');
INSERT INTO `punishment` VALUES ('201400009', '陈子丹', '小过');
创建学生违纪处罚记录表punishment,如下:

DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`student_id` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int(2) NULL DEFAULT NULL,
`class` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`student_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '学生基本信息表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES ('201400001', '王玉', 18, '一班', '山东省枣庄市');
INSERT INTO `student` VALUES ('201400002', '张三', 23, '二班', '江苏省南京市');
INSERT INTO `student` VALUES ('201400003', '李四', 25, '三班', '江苏省南京市');
INSERT INTO `student` VALUES ('201400004', '顾丽丽', 32, '一班', '江苏省南京市');
INSERT INTO `student` VALUES ('201400005', '邵芳芳', 29, '四班', '江苏省南京市');
INSERT INTO `student` VALUES ('201400006', '杨智', 30, '一班', '江苏省南京市');
注意,为了测试这三种JOIN操作的不同,punishment表中2014000009这个学生ID在学生基本信息表中是不存在的,这个相当于异常数据。
示例信息已经创建完毕,那么我们来看看具体的操作有什么区别。
INNER JOIN操作
首先,我们看看INNER JOIN操作,我们写个SQL语句,查询学生表中哪些学生受过处分:
SELECT
STU.student_id,
STU.name,
STU.class,
P.punishment
FROM student AS STU
INNER JOIN punishment AS P
ON STU.student_id=P.student_id
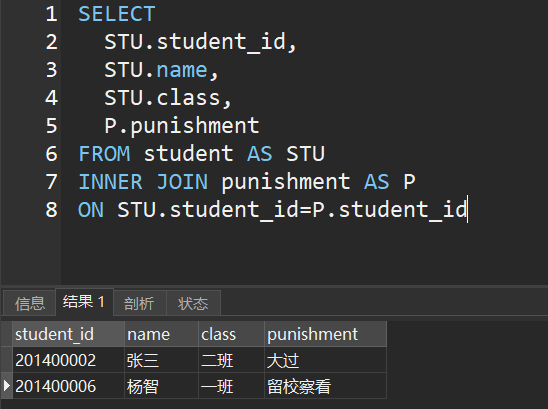
分析一下上面SQL语句的执行结果,我们的查询条件是STU.student_id=P.student_id,即学生表和处分表都有的student_id的结果集,很明显,2014000002、2014000006在两表中都有
所以我们可以得出INNER JOIN操作的作用是:INNER JOIN根据ON字段标识出来的条件,查出关联的几张表中,符合该条件的记录,合并成一个查询结果集。
LEFT JOIN操作
SELECT
STU.student_id,
STU.name,
STU.class,
P.punishment
FROM student AS STU
LEFT JOIN punishment AS P
ON STU.student_id=P.student_id

分析一下执行结果,LEFT JOIN操作中,比如A LEFT JOIN B,会输出 左表A 中所有的数据,同时将符合 ON条件 的 右表B 中搜索出来的结果合并到 左表A表中,如果A表中存在而在B表中不存在,则结果集中会将查询的B表字段值(如此处的P.punishment字段)设置为NULL。
所以,LEFT JOIN的作用是:LEFT JOIN 从 右表B 中将符合ON条件的结果查询出来,合并到A表中,再作为一个结果集输出。
RIGHT JOIN操作
SELECT
STU.student_id,
STU.name,
STU.class,
P.punishment
FROM student AS STU
RIGHT JOIN punishment AS P
ON STU.student_id=P.student_id
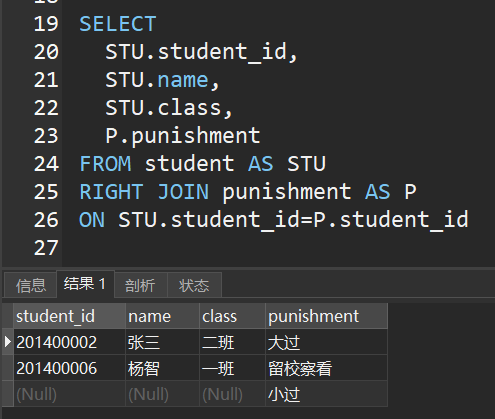
分析过LEFT JOIN了,RIGHT JOIN相信你也已经明白了,“A LEFT JOIN B ON ……”是将符合ON条件的B表搜索结果合并到A表中,作为一个结果集输出。而RIGHT JOIN刚好相反, “A RIGHT JOIN B ON ……”是将符合ON条件的A表搜索结果合并到B表中,作为一个结果集输出:
总结
A INNER JOIN B ON……:内联操作,将符合ON条件的A表和B表结果均搜索出来,然后合并为一个结果集。A LEFT JOIN B ON……:左联操作,左联顾名思义是,将符合ON条件的B表结果搜索出来,然后左联到A表上,然后将合并后的A表输出。A RIGHT JOIN B ON……:右联操作,右联顾名思义是,将符合ON条件的A表结果搜索出来,然后右联到B表上,然后将合并后的B表输出。
参考
SQL中INNER、LEFT、RIGHT JOIN的区别和用法详解