大创项目推荐 深度学习实现语义分割算法系统 - 机器视觉
文章目录
- 1 前言
- 2 概念介绍
-
- 2.1 什么是图像语义分割
- 3 条件随机场的深度学习模型
-
- 3\. 1 多尺度特征融合
- 4 语义分割开发过程
-
- 4.1 建立
- 4.2 下载CamVid数据集
- 4.3 加载CamVid图像
- 4.4 加载CamVid像素标签图像
- 5 PyTorch 实现语义分割
-
- 5.1 数据集准备
- 5.2 训练基准模型
- 5.3 损失函数
- 5.4 归一化层
- 5.5 数据增强
- 5.6 实现效果
- 6 最后
1 前言
优质竞赛项目系列,今天要分享的是
基于深度学习实现语义分割算法系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 概念介绍
2.1 什么是图像语义分割
这几年,随着深度学习理论和大规模并行计算设备快速发展,计算机视觉的诸多难点实现了质的突破,包括图像分类叫、目标检测、语义分割等等。
其中图像分类和目标检测在各种场景应用中大放光彩。目前最先进网络的准确度已经超过人类。
而图像语义分割是一.种语义信息更丰富的视觉识别任务,其主要任务是实现像素级别的分类。
图像语义分割示意图如下图所示。
图像语义分割技术在实际中有着非常广泛的应用,如自动驾驶、生物医学以及现实增强技术等等。

语义分割在自动驾驶的应用:

3 条件随机场的深度学习模型
整个深度学习模型框架下如图:

3. 1 多尺度特征融合
图像中的各类物体都以不同的形态出现, 用来观测它们的尺度也不尽相同, 不同的物体需要用合适的尺度来测量。
尺度也有很多种, 宏观上大的如“米”、“千米” 甚至“光年”; 微观上小的如“微米”、“纳米” 甚至是“飞米”。 在日常生活中,
人们也经常接触到尺度上的变换, 例如人们经常用到的电子地图上的放大与缩小、 照相机焦距的变化等,都是以不同的尺度来观察或者测量不同的物体。
当人们将一幅图像输入到计算机中时, 计算机要尝试很多不同的尺度以便得到描述图片中不同物体的最合适的尺度。
卷积神经网络中含有大量的超参数, 而且在网络中的任何一个参数, 都会对网络生成的特征映射产生影响。 当卷积神经网络的结构已经确定下来时,
网络中每一层学习到的特征映射的尺度也随之固定了下来, 拥有了在一定程度上的尺度不变性。
与此同时, 为了完成当前的任务, 网络中的这些已经设置好的超参数不能被随意更改, 所以必须要考虑融合多尺度特征的神经网络。
这种神经网络可以学习学长提供的框架不同尺度的图像特征, 获得不同尺度的预测, 进而将它们融合, 获得最后的输出。
一种多尺度特征融合网络如下所示。
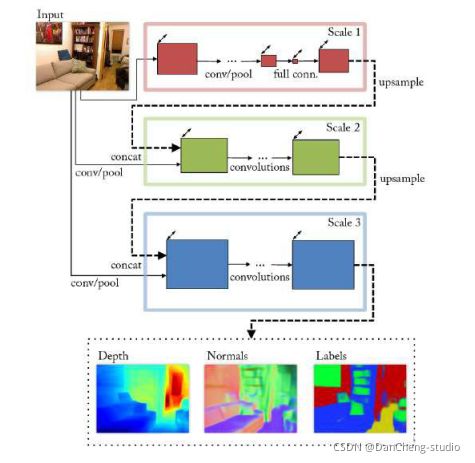
4 语义分割开发过程
学长在这详细说明图像语义分割,如何进行开发和设计
语义分割网络对图像中的每个像素进行分类,从而产生按类别分割的图像。语义分割的应用包括用于自主驾驶的道路分割和用于医学诊断的癌细胞分割。有关详细信息,请参阅语义分段基础知识(计算机视觉系统工具箱)。
为了说明训练过程,学长训练SegNet ,一种设计用于语义图像分割的卷积神经网络(CNN)。用于语义分段的其他类型网络包括完全卷积网络(FCN)和U-
Net。此处显示的培训程序也可以应用于这些网络。
此示例使用剑桥大学的CamVid数据集进行培训。此数据集是包含驾驶时获得的街道视图的图像集合。该数据集为32种语义类提供了像素级标签,包括汽车,行人和道路。
4.1 建立
此示例创建具有从VGG-16网络初始化的权重的SegNet网络。要获得VGG-16,请安装适用于VGG-16网络的Deep Learning
Toolbox™模型。安装完成后,运行以下代码以验证安装是否正确。
vgg16();
下载预训练版的SegNet。预训练模型允许您运行整个示例,而无需等待培训完成。
pretrainedURL = 'https: //www.mathworks.com/supportfiles/vision/data/segnetVGG16CamVid.mat ' ;
pretrainedFolder = fullfile(tempdir,'pretrainedSegNet');
pretrainedSegNet = fullfile(pretrainedFolder,'segnetVGG16CamVid.mat');
如果〜存在(pretrainedFolder,'dir')
MKDIR(pretrainedFolder);
disp('下载预训练的SegNet(107 MB)......');
websave(pretrainedSegNet,pretrainedURL);
结束
强烈建议使用具有计算能力3.0或更高版本的支持CUDA的NVIDIA™GPU来运行此示例。使用GPU需要Parallel Computing
Toolbox™。
4.2 下载CamVid数据集
从以下URL下载CamVid数据集。
imageURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip’ ;
labelURL = 'http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip’ ;
outputFolder = fullfile(tempdir,‘CamVid’);
如果〜存在(outputFolder,‘dir’)
MKDIR(outputFolder)
labelsZip = fullfile(outputFolder,'labels.zip');
imagesZip = fullfile(outputFolder,'images.zip');
disp('下载16 MB CamVid数据集标签......');
websave(labelsZip,labelURL);
unzip(labelsZip,fullfile(outputFolder,'labels'));
disp('下载557 MB CamVid数据集图像......');
websave(imagesZip,imageURL);
解压缩(imagesZip,fullfile(outputFolder,'images'));
注意:数据的下载时间取决于您的Internet连接。上面使用的命令会阻止MATLAB,直到下载完成。或者,您可以使用Web浏览器首先将数据集下载到本地磁盘。要使用从Web下载的文件,请将outputFolder上面的变量更改为下载文件的位置。
4.3 加载CamVid图像
使用imageDatastore加载CamVid图像。在imageDatastore使您能够高效地装载大量收集图像的磁盘上。
imgDir = fullfile(outputFolder,'images','701_StillsRaw_full');
imds = imageDatastore(imgDir);
显示其中一个图像。
4.4 加载CamVid像素标签图像
使用pixelLabelDatastore加载CamVid像素标签图像数据。A
pixelLabelDatastore将像素标签数据和标签ID封装到类名映射中。
按照原始SegNet论文[1]中使用的程序,将CamVid中的32个原始类分组为11个类。指定这些类。
class = [
“Sky”
“Building”
“Pole”
“Road”
“Pavement”
“Tree”
“SignSymbol”
“Fence”
“Car”
“Pedestrian”
“Bicyclist”
];
要将32个类减少为11个,将原始数据集中的多个类组合在一起。例如,“Car”是“Car”,“SUVPickupTruck”,“Truck_Bus”,“Train”和“OtherMoving”的组合。使用支持函数返回分组的标签ID,该函数camvidPixelLabelIDs在本示例的末尾列出。
abelIDs = camvidPixelLabelIDs();
使用类和标签ID来创建 pixelLabelDatastore.
labelDir = fullfile(outputFolder,'labels');
pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
通过将其叠加在图像上来读取并显示其中一个像素标记的图像。
C = readimage(pxds,1);
cmap = camvidColorMap;
B = labeloverlay(I,C,'ColorMap',cmap);
imshow(B)
pixelLabelColorbar(CMAP,班);
5 PyTorch 实现语义分割
学长这里给出一个具体实例 :
使用2020年ECCV Vipriors Chalange Start Code实现语义分割,并且做了一些优化,让进度更高
5.1 数据集准备
使用Cityscapes的数据集MiniCity Dataset。
将各基准类别进行输入:

从0-18计数,对各类别进行像素标记:

使用deeplab v3进行基线测试,结果发现次要类别的IoU特别低,这样会导致难以跟背景进行区分。
如下图中所示的墙、栅栏、公共汽车、火车等。
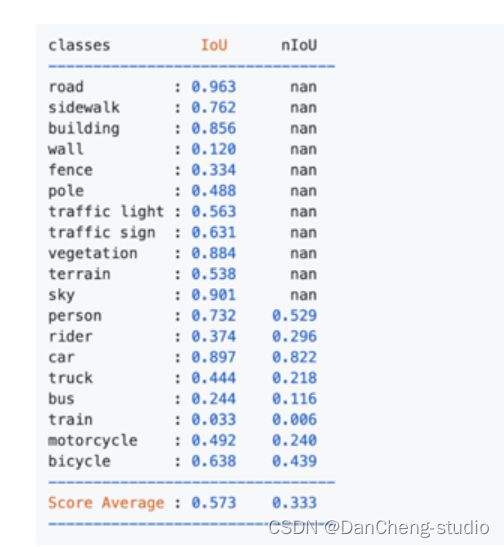
注意: 以上的结果表述数据集存在严重的类别不平衡问题。
5.2 训练基准模型
使用来自torchvision的DeepLabV3进行训练。
硬件为4个RTX 2080 Ti GPU (11GB x 4),如果只有1个GPU或较小的GPU内存,请使用较小的批处理大小(< = 8)。
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
python baseline.py --save_path baseline_run_deeplabv3_resnet101 --model DeepLabv3_resnet101 --train_size 512 1024 --test_size 512 1024 --crop_size 384 768 --batch_size 8;
5.3 损失函数
有3种损失函数可供选择,分别是:交叉熵损失函数(Cross-Entropy Loss)、类别加权交叉熵损失函数(Class-Weighted Cross
Entropy Loss)和焦点损失函数(Focal Loss)。
交叉熵损失函数,常用在大多数语义分割场景,但它有一个明显的缺点,那就是对于只用分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,模型严重偏向背景,导致效果不好。
# Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --crop_size 576 1152 --batch_size 8;
类别加权交叉熵损失函数是在交叉熵损失函数的基础上为每一个类别添加了一个权重参数,使其在样本数量不均衡的情况下可以获得更好的效果。
# Weighted Cross Entropy Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_wce --crop_size 576 1152 --batch_size 8 --loss weighted_ce;
焦点损失函数则更进一步,用来解决难易样本数量不平衡。
# Focal Loss
python baseline.py --save_path baseline_run_deeplabv3_resnet50_focal --crop_size 576 1152 --batch_size 8 --loss focal --focal_gamma 2.0;
5.4 归一化层
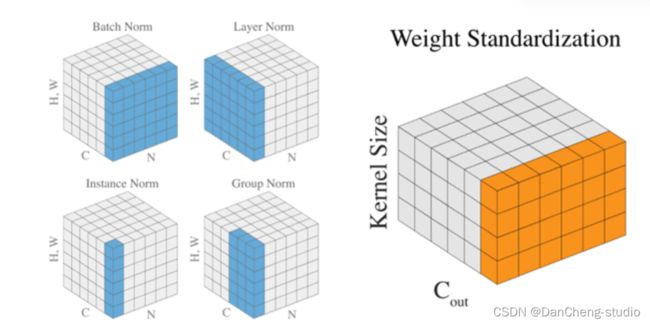
BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。
5.5 数据增强
2种数据增强技术
- CutMix
- Copy Blob
在 Blob 存储的基础上构建,并通过Copy的方式增强了性能。
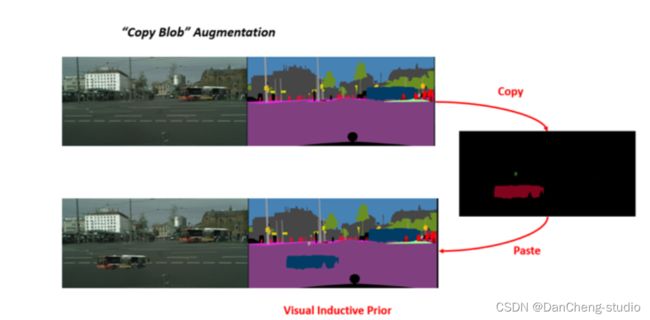
另外,如果要解决前面所提到的类别不平衡问题,则可以使用视觉归纳优先的CopyBlob进行增强。
# CopyBlob Augmentation
python baseline.py --save_path baseline_run_deeplabv3_resnet50_copyblob --crop_size 576 1152 --batch_size 8 --copyblob;
5.6 实现效果
多尺度推断
使用[0.5,0.75,1.0,1.25,1.5,1.75,2.0,2.2]进行多尺度推理。另外,使用H-Flip,同时必须使用单一批次。
# Multi-Scale Inference
python baseline.py --save_path baseline_run_deeplabv3_resnet50 --batch_size 1 --predict --mst;
使用验证集计算度量
计算指标并将结果保存到results.txt中。
python evaluate.py --results baseline_run_deeplabv3_resnet50/results_val --batch_size 1 --predict --mst;
训练结果

最后的单一模型结果是0.6069831962012341,
如果使用了更大的模型或者更大的网络结构,性能可能会有所提高。
另外,如果使用了各种集成模型,性能也会有所提高。
6 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate