SpringCloud复习
微服务演变
单体架构不足
- 业务越来越复杂,单体应用的代码量越来越大,代码的可读性、可维护性和可扩展性下降,
新人接手代码所需的时间成倍增加,业务扩展带来的代价越来越大。 - 随着用户越来越多,程序承受的并发越来越高,单体应用的并发能力有限。
- 测试的难度越来越大,单体应用的业务都在同个程序中,随着业务的扩张、复杂度的增加,
单体应用修改业务或者增加业务或许会给其他业务带来定的影响,导致测试难度增加。
什么是微服务
就是将一个大的应用,拆分成多个小的模块,每个模块都有自己的功能和职责,每个模块可以
进行交互,这就是微服务
微服务的优势
- 将一个复杂的业务分解成若干小的业务,每个业务拆分成一个服务,服务的边界明确,
将复杂的问题简单化 - 由于微服务系统是分布式系统,服务与服务之间没有任何的祸合。随着业务的增加,可
以根据业务再拆分服务,具有极强的横向扩展能力 - 服务与服务之问通过 HTTP 网络通信协议来通信,单个微服务内部高度耦合,服务与服
务之间完全独立 - 微服务的每个服务单元都是独立部署的,即独立运行在某个进程里。微服务的修改和部
署对其他服务没有影响。 - 微服务在 CAP 理论中采用的是 AP 架构,即具有高可用和分区容错的特点。
微服务的不足
- 微服务的复杂度
- 分布式事务问题
- 服务的划分(按照功能划分 还是按照组件来划分呢) 分工
- 服务的部署(不用自动化部署 自动化部署)
软件设计理解
软件设计每一个版本都在变化,所以软件设计应该是渐进式发展。软件从一开始就不应该被设
计成微服务架构,微服务架构固然有优势,但是它需要更多的资源,包括服务器资源、技术人
员等。追求大公司所带来的技术解决方案,刻意地追求某个新技术,企图使用技术解决所有的
问题,这些都是软件设计的误区。
技术应该是随着业务的发展而发展的,任何脱离业务的技术是不能产生价值的。在初创公司,
业务很单一时,如果在 LAMP 单体构架够用的情况下,就应该用 LAMP,因为它开发速度快,
性价比高。随着业务的发展,用户量的增加,可以考虑将数据库读写分离、加缓存、加复杂均
衡服务器、将应用程序集群化部署等。如果业务还在不断发展,这时可以考虑使用分布式系统,
例如微服务架构的系统。不管使用什么样的架构,驱动架构的发展一定是业务的发展,只有当
前架构不再适合当前业务的发展,才考虑更换架构。
在微服务架构中,有三大难题,那就是
服务故障的传播性(熔断)、
服务的划分
分布式事务。
在微服务设计时,一定要考虑清楚这三个难题,从而选择合适的框架。
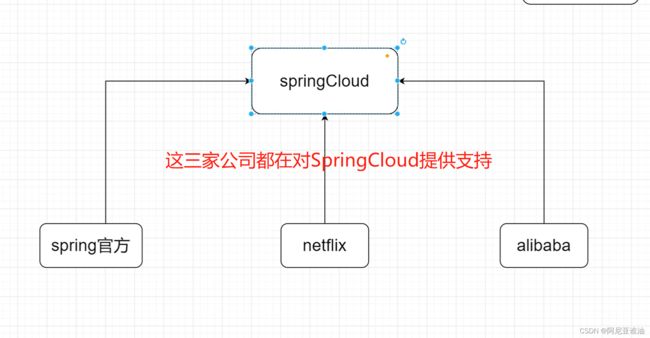
目前比较流行的
微服务框架有 Spring 社区的 Spring Cloud、 Google 公司的 Kubemetes 等。
不管使用哪一种框架或者工具,都需要考虑这三大难题。为了解决服务故障的传播性,一般的微服务框架都有熔断机制组件。另外,服务的划分没有具体的划分方法,一般来说根据业务来划分服务,领域驱动设计具有指导作用。最后,分布式事务一般的解决办法就是两阶段提交或者三阶段提交,不管使用哪一种都存在事务失败,导致数据不一致的情况,关键时刻还得人工去恢复数据。
总之,微服务的设计一定是渐进式的,并且是随着业务的发展而发展的
SpringCloud 简介(管家 注重服务的管理)
Spring Cloud 的首要目标就是通过提供一系列开发组件和框架,帮助开发者迅速搭建一个分布式的微服务系统。
Spring Cloud 是通过包装其他技术框架来实现的
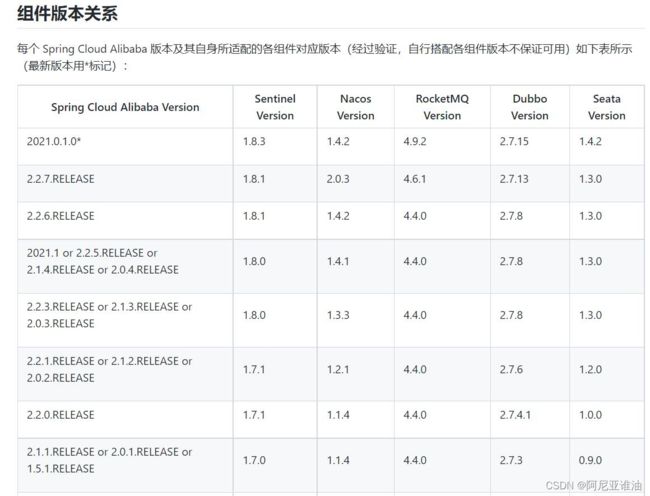
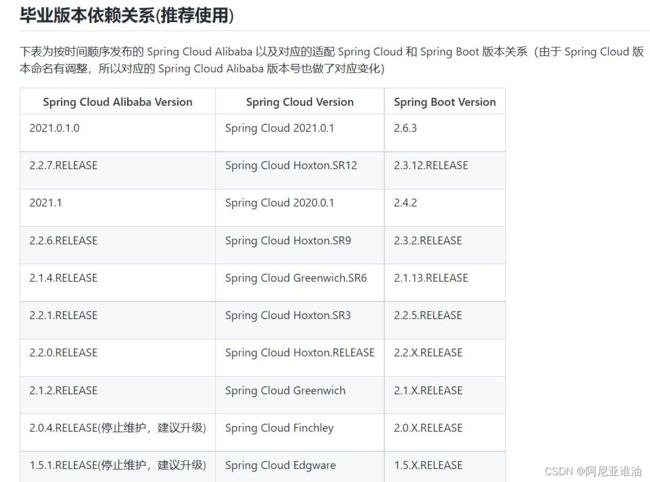
SpringCloud 版本对应关系
点此可以查看对应的版本关系
ps: 日后可能会随着版本的更新一直在更新
"spring-cloud":{
"Hoxton.SR12":"Spring Boot >=2.2.0.RELEASE and <2.4.0.M1",
"2020.0.6":"Spring Boot >=2.4.0.M1 and <2.6.0-M1",
"2021.0.0-M1":"Spring Boot >=2.6.0-M1 and <2.6.0-M3",
"2021.0.0-M3":"Spring Boot >=2.6.0-M3 and <2.6.0-RC1",
"2021.0.0-RC1":"Spring Boot >=2.6.0-RC1 and <2.6.1",
"2021.0.5":"Spring Boot >=2.6.1 and <3.0.0-M1",
"2022.0.0-M1":"Spring Boot >=3.0.0-M1 and <3.0.0-M2",
"2022.0.0-M2":"Spring Boot >=3.0.0-M2 and <3.0.0-M3",
"2022.0.0-M3":"Spring Boot >=3.0.0-M3 and <3.0.0-M4",
"2022.0.0-M4":"Spring Boot >=3.0.0-M4 and <3.0.0-M5",
"2022.0.0-M5":"Spring Boot >=3.0.0-M5 and <3.0.0-RC1",
"2022.0.0-RC1":"Spring Boot >=3.0.0-RC1 and <3.0.0-RC2",
"2022.0.0-RC2":"Spring Boot >=3.0.0-RC2 and <3.0.0",
"2022.0.1":"Spring Boot >=3.0.0 and <3.1.0-M1"
}
SpringCloud 常用组件表 (管家)
- 服务的注册和发现。(eureka,nacos,consul)
- 服务的负载均衡。(ribbon,dubbo)
- 服务的相互调用。(openFeign,dubbo)
- 服务的容错。(hystrix,sentinel)
- 服务网关。(gateway,zuul)
- 服务配置的统一管理。(config-server,nacos,apollo)
- 服务消息总线。(bus)
- 服务安全组件。(security,Oauth2.0)
- 服务监控。(admin) (jvm)
- 链路追踪。(sleuth+zipkin)
总结
SpringCloud 就是微服务理念的一种具体落地实现方式,帮助微服务架构提供了必备的功能
目前开发中常用的落地实现有三种:
- Dubbo+Zookeeper 半自动化的微服务实现架构
(别的管理没有) - SpringCloud Netflix 一站式微服务架构
- SpringCloud Alibaba 新的一站式微服务架构
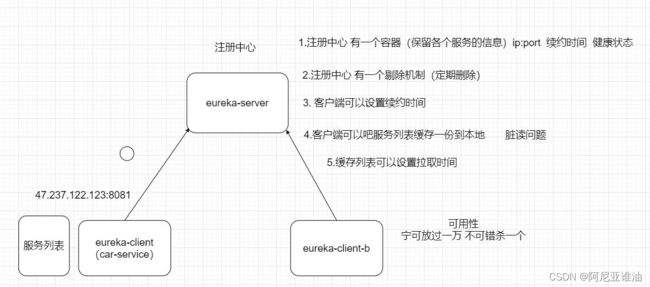
SpringCloud Eureka
注册发现中心
简介
Eureka 来源于古希腊词汇,意为“发现了”。在软件领域,
Eureka 是 Netflix 在线影片公司开源的一个服务注册与发现的组件,和其他 Netflix 公司的服务组件(例如负载均衡、熔断器、网关等) 一起,被 Spring Cloud 社区整合为 Spring Cloud Netflix 模块。
Eureka 是 Netflix贡献给 Spring Cloud 的一个框架!Netflix给 Spring Cloud 贡献了很多框架,后面我们会学习到!
Eureka 和 Zookeeper 的区别
什么是 CAP 原则(面试)
CAP 原则又称 CAP 定理,指的是在一个分布式系统中,
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)(这个特性是不可避免的)
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
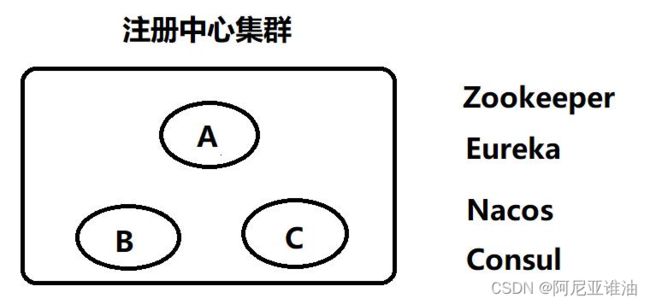
为什么 zookeeper 不适合做注册中心?
因为zookeeper实现的是cp,不适合做高可用的注册中心
分布式特征
C : 数据的一致性 (A,B,C 里面的数据是一致的)
Zk 注重数据的一致性。
Eureka 不是很注重数据的一致性!
A: 服务的可用性(若 zk 集群里面的 master 挂了怎么办)Paxos(多数派)
在 zk 里面,若主机挂了,则 zk 集群整体不对外提供服务了,需要选一个新的出来(120s
左右)才能继续对外提供服务!
Eureka 注重服务的可用性,当 Eureka 集群只有一台活着,它就能对外提供服务
P:分区的容错性(在集群里面的机器,因为网络原因,机房的原因,可能导致数据不会里面
同步),它在分布式必须需要实现的特性!
Zookeeper 注重数据的一致性,CP zk(注册中心,配置文件中心,协调中心)
Eureka 注重服务的可用性 AP eureka (注册中心)
Spring Cloud 还有别的注册中心 Consul ,阿里巴巴提供 Nacos 都能作为注册中心,我们
的选择还是很多
Spring Cloud Eureka 快速入门
搭建 Eureka-server
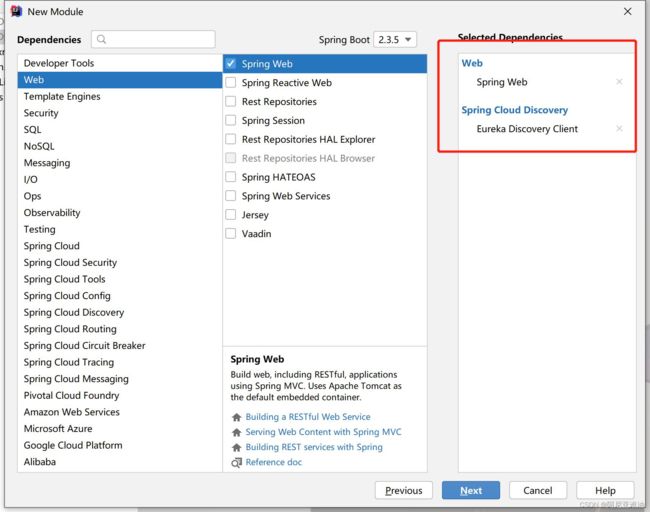
- 引入依赖
创建boot项目时选择 Eureka Server 依赖
- 修改pom版本
注意:这里用的是Cloud的Hoxton.SR12版本
boot用的是 2.3.12.RELEASE 版本
org.springframework.boot
spring-boot-starter-parent
2.3.12.RELEASE
com.zjj
Eureka_Server_01
0.0.1-SNAPSHOT
Eureka_Server_01
Eureka_Server_01
1.8
Hoxton.SR12
- 配置文件:
server:
port: 8761 # 默认端口
spring:
application:
name: eureka-server # 服务名称
- 项目启动以后可以直接访问
分析端口 8761
Eureka-Server 不仅提供让别人注册的功能,它也能注册到别人里面,自己注册自己
所以,在启动项目时,默认会注册自己,我们也可以关掉这个功能
看一下配置文件如下:
如果service-url 不进行配置会有默认值
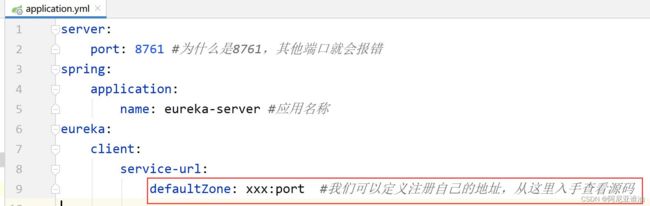
查看源码: 其中 service-url 属性的值有默认值
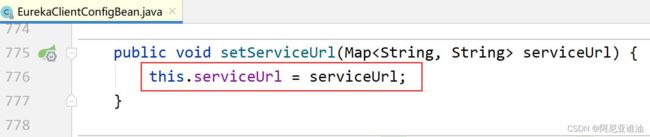
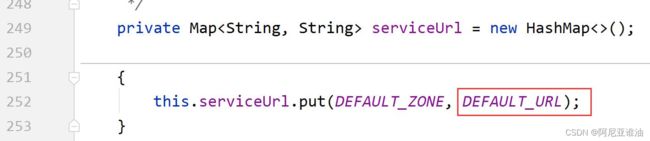
会有8761的默认值

搭建 Eureka-client
- 引入依赖 : Spring Web 和 Eureka Discovery Client
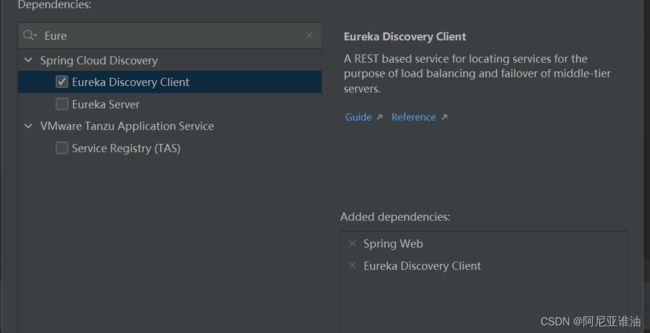
- 修改pom版本
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.12.RELEASE</version> # Spring boot 版本
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.zjj</groupId>
<artifactId>Eureka_Client_01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Eureka_Client_01</name>
<description>Eureka_Client_01</description>
<properties>
<java.version>1.8</java.version> # java 版本
<spring-cloud.version>Hoxton.SR12</spring-cloud.version> # SpringBoot 对应的Cloud版本
</properties>
- 修改配置文件
server:
port: 8001
spring:
application:
name: eureka-clinet-a
eureka:
client:
service-url: # Eureka 服务端和客户端的交互地址
defaultZone: http://localhost:8761/eureka/
- 访问测试
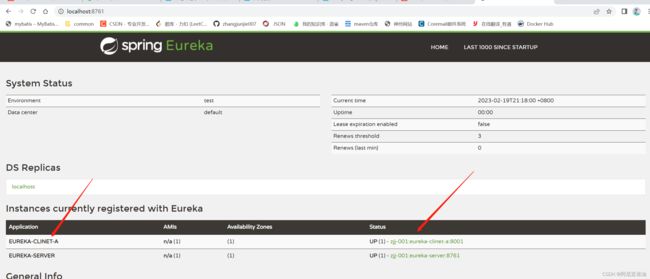
再搭建一个项目 client-b
如 client-a 一样,这里就不贴多余截图了,注意
端口和服务名以及启动类上的注解,在测试
查看是否注册上去,在 eureka 里面是通过 spring.application.name 来区分服务的
yml配置文件
server:
port: 8002
spring:
application:
name: eureka-clinet-b
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
同一个服务(客户端)启动多台
这里利用idea 只修改端口,可以再起一台服务
- 点击编辑配置
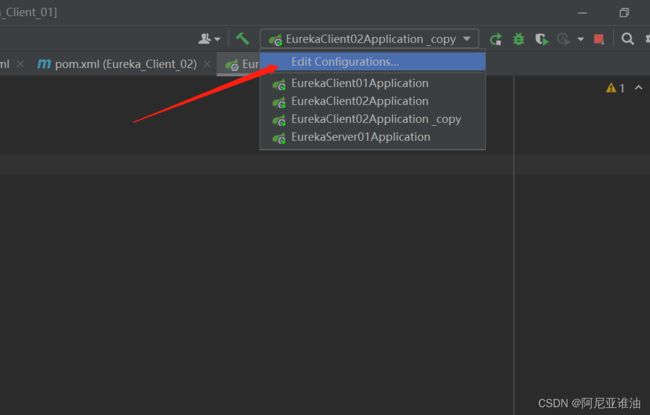
-
选择复制,复制以后,自己给应用起个别名
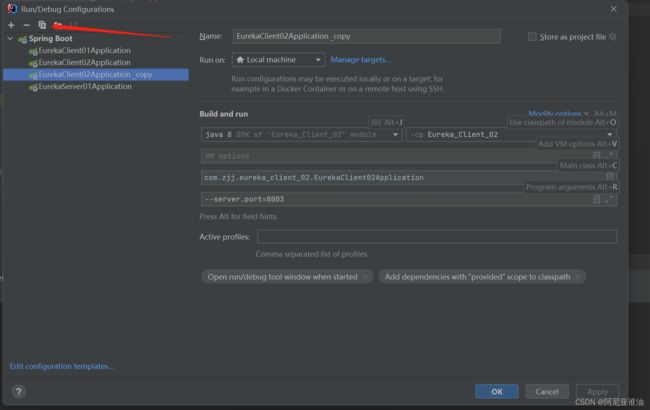
-
把配置列配置出来
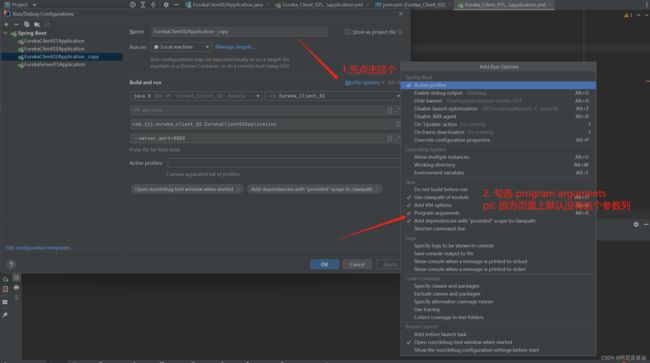
5、配置新的端口,然后启动即可
–server.port=8003
- 访问查看
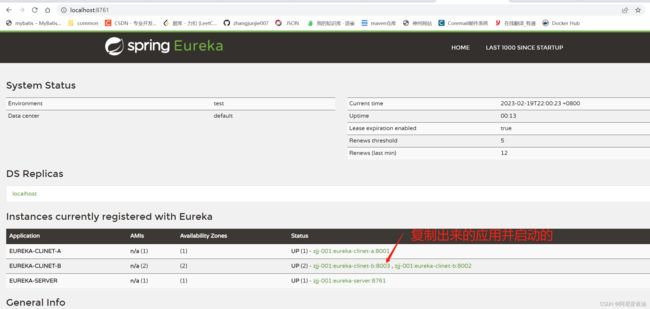
ps:各参数的含义如图
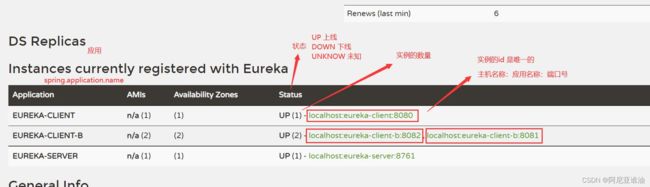
- UP: 服务是上线的,括号里面是具体服务实例的个数,提供服务的最小单元
- DOWN: 服务是下线的
- UN_KONW: 服务的状态未知
常用配置文件设置
server 中常用的配置
server:
port: 8761
spring:
application:
name: eureka-server
eureka:
client:
service-url: #eureka 服务端和客户端的交互地址,集群用,隔开
defaultZone: http://localhost:8761/eureka/
fetch-registry: true #是否拉取服务列表
register-with-eureka: true #是否注册自己(单机 eureka 一般关闭注册自己,集群注意打开)
server:
eviction-interval-timer-in-ms: 30000 #清除无效节点的频率(毫秒)--定期删除
enable-self-preservation: true # server 的自我保护机制,避免因为网络原因造成误剔除,生产环境建议打开
renewal-percent-threshold: 0.85 # 85%,如果在一个机房的 client 端,15 分钟内有 85%的 client 没有续约,那么则可能是网络原因,认为服务实例没有问题,不会剔除他们,宁可放过一万,不可错杀一个,确保高可用
instance:
hostname: localhost # 服务主机名称
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} # 实例 id
prefer-ip-address: true # 服务列表以 ip 的形式展示
lease-renewal-interval-in-seconds: 10 # 表示 eureka client 发送心跳给 server 端的频率
lease-expiration-duration-in-seconds: 20 #表示 eureka server 至上一次收到 client 的心跳之后,等待下一次心跳的超时时间,在这个时间内若没收到下一次心跳,则将移除该实例
client 中常用的配置
server:
port: 8080
spring:
application:
name: eureka-clinet
eureka:
client:
service-url: #eureka 服务端和客户端的交互地址,集群用,隔开
defaultZone: http://localhost:8761/eureka/
fetch-registry: true #是否拉取服务列表
registry-fetch-interval-seconds: 5 # 表示 eureka-client 间隔多久去拉取服务注册信息
instance:
hostname: localhost # 服务主机名称
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} # 实例 id
prefer-ip-address: true # 服务列表以 ip 的形式展示
lease-renewal-interval-in-seconds: 10 # 表示 eureka client 发送心跳给 server 端的频率
lease-expiration-duration-in-seconds: 20 #表示 eureka server 至上一次收到 client 的心跳之后,等待下一次心跳的超时时间,在这个时间内若没收到下一次心跳,则将移除该实例
构建 Eureka-Server 集群
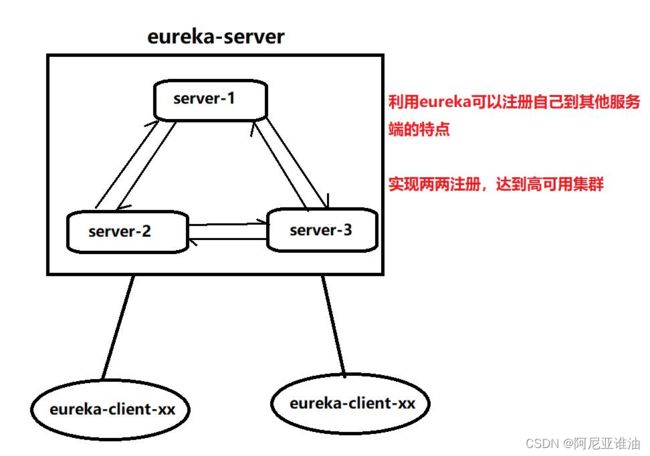
实现方式一:
1、创建三个 Eureka Server 服务,配置对应pom中的依赖及其boot和cloud的版本对应关系
2、分别修改三个项目的配置文件(yml文件)
配置文件如下
server:
port: 8761
spring:
application:
name: eureka-server #服务名称
profiles: dev
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://localhost:8762/eureka/,http://localhost:8763/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
ps: 由于是集群,所以 defaultZone 要配置其他端口的路径服务
实现方式二:
利用idea里面的copy configuration 功能,指定不同的配置文件进行启动。
具体步骤如下图:
- 先配置Eureka Server 的application.yml 文件
server:
port: 8761
spring:
application:
name: eureka-server #服务名称
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://localhost:8762/eureka/,http://localhost:8763/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
- 创建 application-pre.yml 文件,内容如下
server:
port: 8762
spring:
application:
name: eureka-server #服务名称
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://localhost:8761/eureka/,http://localhost:8763/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
- 同理,再创建一个文件(有几个节点就创建几个)application-prod.yml
server:
port: 8763
spring:
application:
name: eureka-server #服务名称
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://localhost:8761/eureka/,http://localhost:8762/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
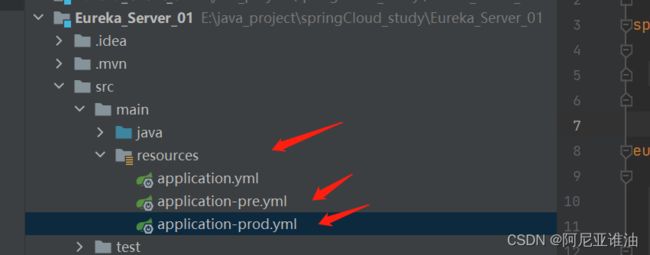
- 关键:在 Edit Configurations 页面,复制Eureka Server ,
指定配置文件启动
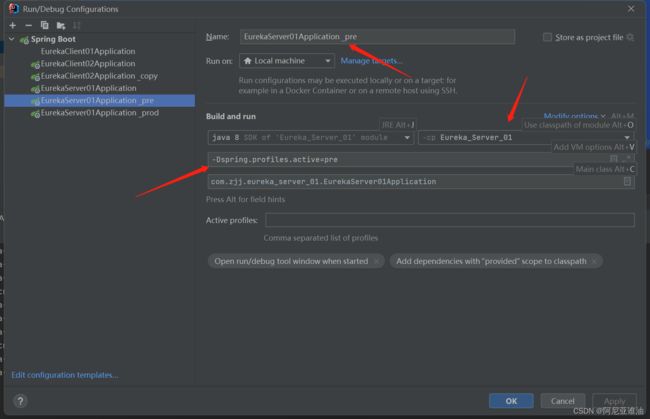
ps: 这里需要注意一下几点
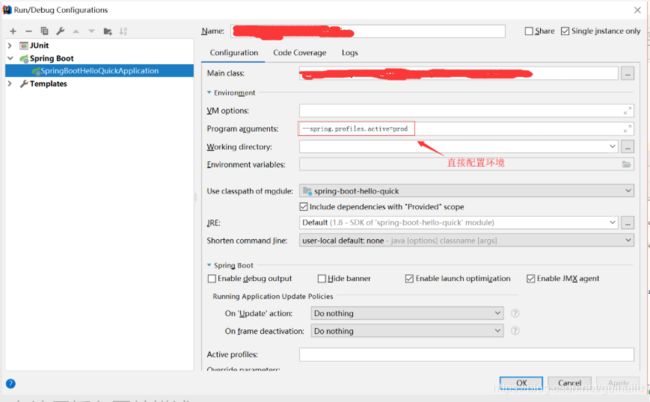
- 配置文件的编写为 application-xxx.yml ,使用的时候只需要指定后缀即可(springboot会根据后缀找到该文件)归功于 Profile
- 是在 VM options 的输入框内,指定运行的配置文件
- 指定配置文件的指令为: -Dspring.profiles.active=pre
配置多个配置文件的话写法如下
补充: Profile 实现多环境配置
我们在项目发布之前,一般需要频繁地在开发环境、测试环境以及生产环境之间进行切换,这个时候大量的配置需要频繁更改(比如数据库配置、redis 配置、mongodb 配置等等)。
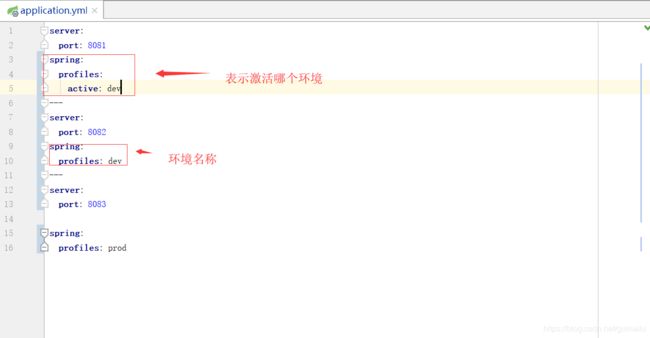
Spring Boot 的 Profile 就给我们提供了解决方案,它约定不同环境下的配置文件名称规则为:
application-{profile}.yml,其中{profile}表示当前环境的名称。
第一种方式
yml多文档块方式:
第二种方式
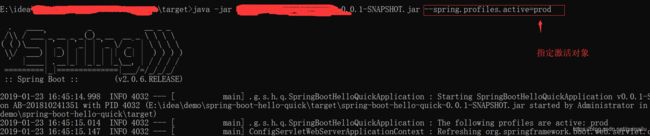
第三中方式
先将项目打包,然后运行命令
java -jar spring-boot-hello-quick-0.0.1-SNAPSHOT.jar --spring.profiles.active=prod
第四种方式
回归正题
测试访问查看
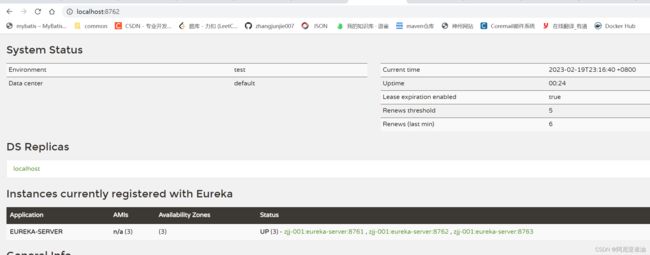
发现并没有出现集群信息,只是同一个服务 server 启动了多台 没有数据交互。不是真正意义上的集群
原因是因为:
http://localhost:8761/eureka/,http://localhost:8762/eureka/ 这样写,eureka 认为只有一个机器,就是 localhost 所以这里面不能写成一样
解决办法:
修改 hosts 文件: C:\Windows\System32\drivers\etc
如果你修改了 hosts 文件 发现没有生效 记得在 cmd 里面刷新一下 : ipconfig /flushdns
重新修改配置文件
server:
port: 8761
spring:
application:
name: eureka-server #服务名称
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://peer2:8762/eureka/,http://peer3:8763/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
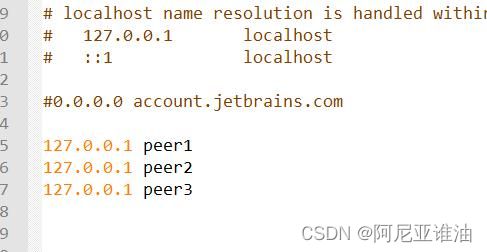
host中添加如下自定义域名。用来迷惑 Eureka
127.0.0.1 peer1
127.0.0.1 peer2
127.0.0.1 peer3然后配置文件中分别把域名分别换成 peer1、peer2、peer3,让三个服务域名都不同
最终的集群信息
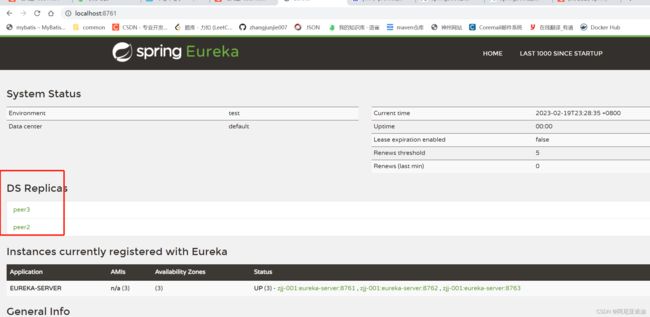
这样每个服务里面都有其他两个服务的信息。
但是没有自己的注册信息。所以可以把自己也注册到集群内。
最终优化配置文件
server:
port: 8761
spring:
application:
name: eureka-server #服务名称
eureka:
client:
fetch-registry: true
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://peer1:8761/eureka/,http://peer2:8762/eureka/,http://peer3:8763/eureka/
server:
eviction-interval-timer-in-ms: 90000 #清除无效节点的评率(毫秒)
instance:
lease-expiration-duration-in-seconds: 90 #server 在等待下一个客户端发送的心跳时间,若在指定时间不能收到客户端心跳,则剔除此实例并且禁止流量
**这样配置以后,每个节点的defaultZone 都是一样的,配置了所有的节点,不一样的只有端口号 **
最终的集群信息
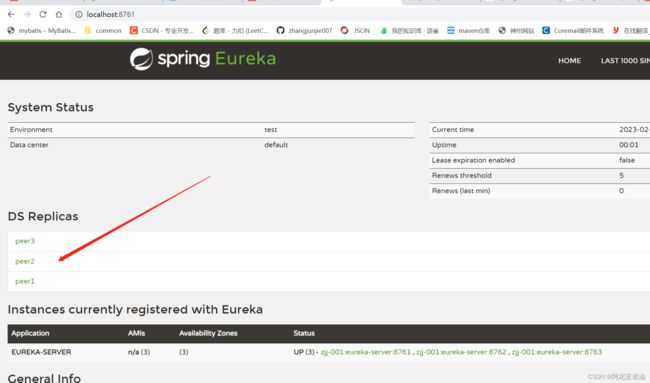
每个节点都包含了三个节点的信息
Spring Cloud Ribbon
Ribbon 概述
Spring Cloud Ribbon 是一个基于 HTTP 和 TCP 的客户端负载均衡工具,它基于 Netflix Ribbon 实现。通过 Spring Cloud 的封装,可以让我们轻松地将面向服务的 REST 模版请求 自动转换成客户端负载均衡的服务调用。
简单的说 Ribbon 就是 netfix 公司的一个开源项目,主要功能是提供客户端负载均衡算法和服务调用。Ribbon 客户端组件提供了一套完善的配置项,比如连接超时,重试等。
在 Spring Cloud 构建的微服务系统中, Ribbon 作为服务消费者的负载均衡器,有两种使用方式,
一种是和 RestTemplate 相结合,
另一种是和 OpenFeign 相结合。OpenFeign 已经默认集成了 Ribbon
负载均衡
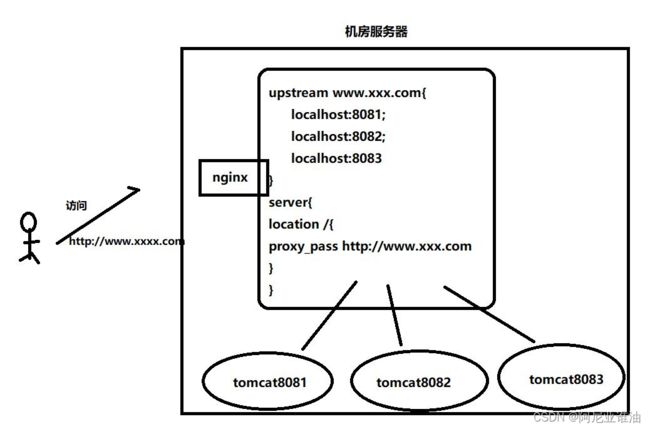
负载均衡,英文名称为 Load Balance(LB)http:// lb://(负载均衡协议),其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如 Web 服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。
负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、加强网络数据处理能力、增加吞吐量、提高网络的可用性和灵活性
例如: Nginx,F5
Ribbon 快速入门
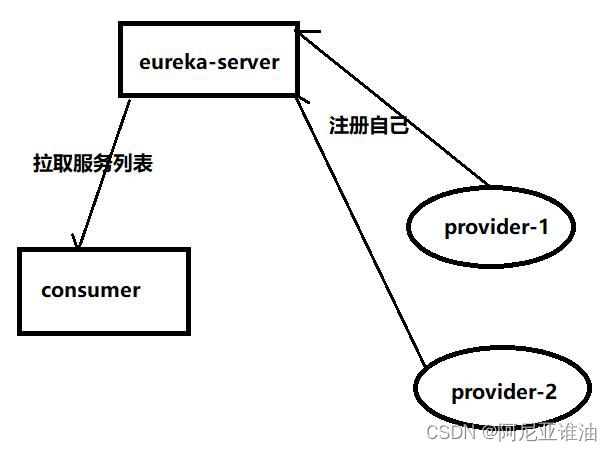
3.1 本次调用设计图
项目搭建
consumer 和 provider-1 和 provider-2 都是 eureka-client
注意这三个依赖是 eureka-client
注意 provider-1 和 provider-2 的 spring.application.name=provider
注意启动类的注解和配置文件的端口以及服务名称
### 创建 provider-1 和 provider-2
提供者的接口
提供者1:
@RestController
public class TestController {
@GetMapping("test")
public String testRibbon(String serverName){
return "服务bbb返回结果";
}
提供者2:
@RestController
public class TestController {
@GetMapping("test")
public String testRibbon(String serverName){
return "服务aaa返回结果";
}
配置如下:
server:
port: 8081
spring:
application:
name: provider #服务名称 两个provider的server要一致才是集群模式
eureka:
client:
fetch-registry: true # #是否拉取服务列表
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://82.157.233.2:8762/eureka/ # 注册到已经启动的虚拟机上
instance:
hostname: localhost
prefer-ip-address: true
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
appname: zjj_01
启动以后如图:
创建consumer
测试ribbon
修改RestTemplate
@SpringBootApplication
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
@Bean
@LoadBalanced
/**
* 此注解加上以后 RestTemplate 就会被 ribbon 所代理,不是原来的 RestTemplate 了
此时如果不想走ribbon托管,就要重新创建一个RestTemplate对象
*/
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
测试服务提供者
@RestController
public class TestController {
@Autowired
RestTemplate restTemplate;
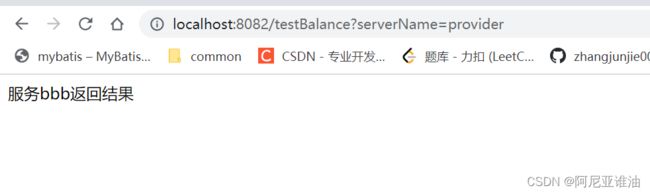
@GetMapping("/testBalance")
public String testRibbon(String serverName){
System.out.println("入参是:"+serverName);
// 需要拿到 ip port 以及路径才可以调用
String result = restTemplate.getForObject("http://" + serverName + "/test", String.class);
return result;
}
}
默认以轮询的方式调用服务提供者进行访问
Ribbon 源码分析
4.1 Ribbon 要做什么事情?
先通过 “http://” + serviceId + “/info” 我们思考 ribbon 在真正调用之前需要做什么?
restTemplate.getForObject(“http://provider/info”, String.class);
想要把上面这个请求执行成功,我们需要以下几步
- 拦截该请求;
- 获取该请求的 URL 地址:http://provider/info
- 截取 URL 地址中的 provider
- 从服务列表中找到 key 为 provider 的服务实例的集合(服务发现)
- 根据
负载均衡算法选出一个符合的实例 - 拿到该实例的 host 和 port,重构原来 URL 中的 provider
- 真正的发送 restTemplate.getForObject(“http://ip:port/info”,String.class)
默认的是轮询算法
### 4.2 Ribbon 负载均衡的测试
@Autowired
LoadBalancerClient loadBalancerClient;
@GetMapping("/testChoose")
public String testChoose(String serverName) {
ServiceInstance server = loadBalancerClient.choose(serverName);
return server.toString();
}
4.3 从 choose 方法入手,查看 Ribbon 负载均衡的源码
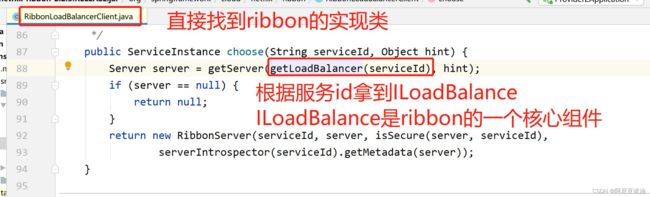
走进 getServer()方法
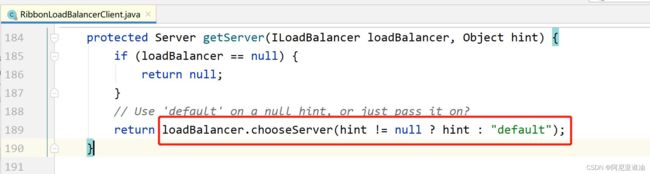
在 chooseServer()里面得到 rule 是哪个对象
发现当前的 rule 是 ZoneAvoidanceRule 对象,而他只有一个父类 PredicateBasedRule

最终进入 PredicateBasedRule 类的 choose()方法
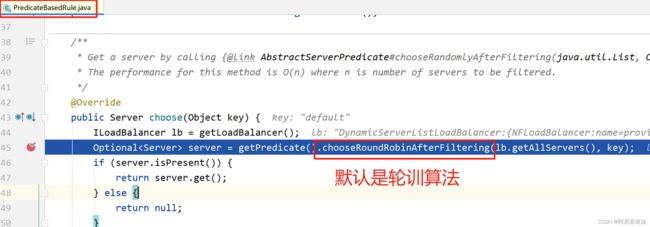
com.netflix.loadbalancer.AbstractServerPredicate#incrementAndGetModulo
### 4.4 负载均衡之前的服务列表是从何而来呢?
Ribbon 里面有没有服务列表?
Ribbon 只做负载均衡和远程调用
服务列表从哪来?
从 eureka 来
Ribbon 有一个核心接口 ILoadBalance(承上(eureka)启下(Rule))
我们发现在负载均衡之前,服务列表已经有数据了
重点接口 ILoadBalancer
Ribbon 没有服务发现的功能,但是 eureka 有,所以 ribbon 和 eureka 完美结合,我们继续干源码学习

首先关注这两个集合,就是存放从 eureka 服务端拉取的服务列表然后缓存到本地
我们去看 DynamicServerListLoadBalancer 类如何获取服务列表,然后放在 ribbon 的缓存里面
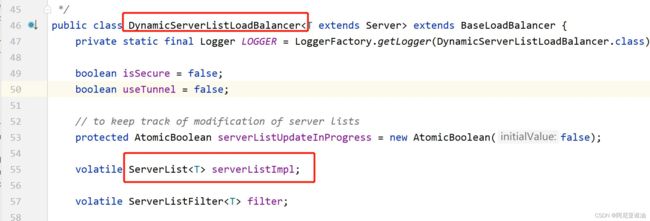
ServerList 实现类(DiscoveryEnabledNIWSServerList)
再回到 BaseLoadBalancer 中真正的存放服务列表
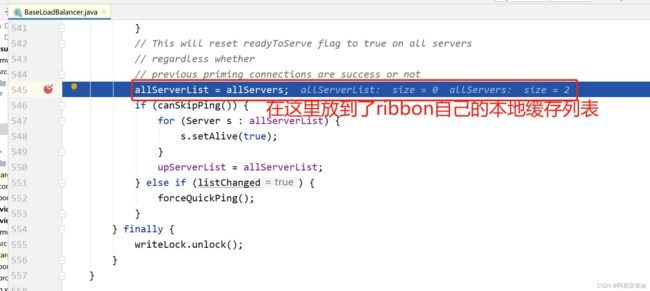
最后我们得知,只有在初始化 DynamicServerListLoadBalancer 类时,去做了服务拉取和缓存
也就是说并不是服务一启动就拉取了服务列表缓存起来,流程图如下:
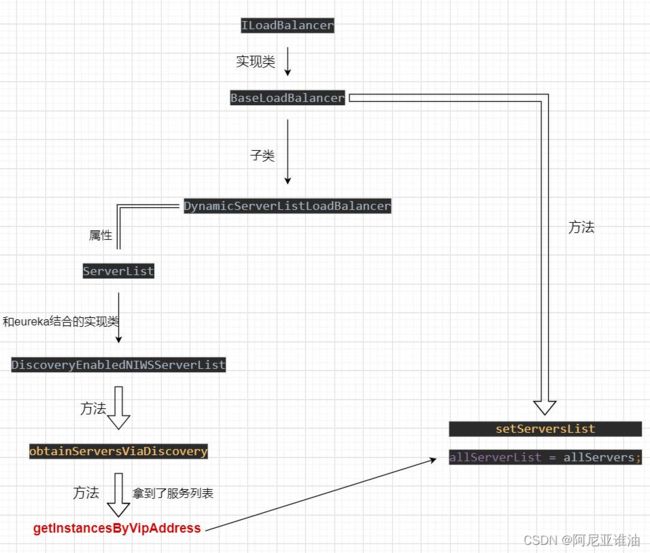
4.5 Ribbon 把 serverList 缓存起来,脏读怎么处理?(选学)
根据上面缓存服务列表我们得知,ribbon 的每个客户端都会从 eureka-server 中把服务列
表缓存起来 主要的类是 BaseLoadBalancer,那么有新的服务上线或者下线,这么保证缓存及时同步呢
Ribbon 中使用了一个 PING 机制 从 eureka 中拿到服务列表,缓存到本地,ribbon 搞了个定时任务,隔一段时间就去循环 ping 一下每个服务节点是否存活

我们查看 IPing 这个接口
我们就想看 NIWSDiscoveryPing
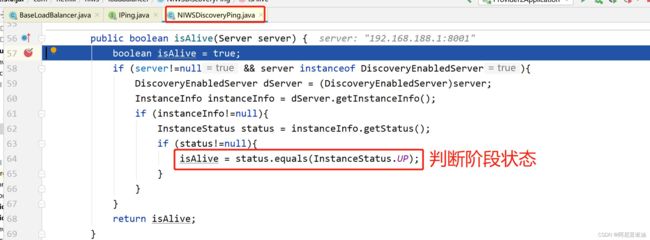
跟着 isAlive 一直往上找,看哪里去修改本地缓存列表
查看 notifyServerStatusChangeListener 发现只是一个空壳的接口,并没有对缓存的服务
节点做出是实际操作,那么到底在哪里修改了缓存列表的值呢?
我们发现在 ribbon 的配置类中 RibbonClientConfiguration 有一个更新服务列表的方法
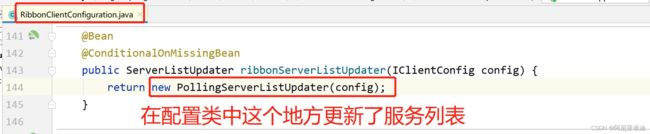
定时任务在哪里开始执行的呢?我们查找 doUpdate()方法
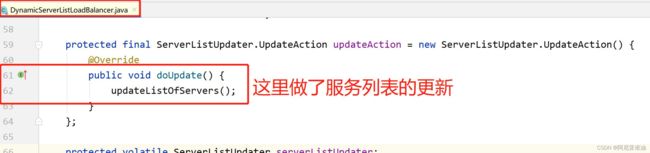
解决脏读机制的总结:
- Ping
- 更新机制
都是为了解决脏读的现象而生的
测试发现:更新机制和 ping 有个重回,而且在 ping 的时候不能运行更新机制,在更新的时
候不能运行 ping 机制,导致我们很难测到 ping 失败的现象!
Ping 机制做不了事情
4.6 Ribbon 负载均衡的实现和几种算法【重点】
在 ribbon 中有一个核心的负载均衡算法接口 IRule
1.RoundRobinRule–轮询
请求次数 % 机器数量
2.RandomRule–随机
3.权重
5.RetryRule-- 先按照轮询的策略获取服务,如果获取服务失败则在指定的时间内会进行重
试,获取可用的服务
6.BestAvailableRule --会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后
选择一个并发量小的服务
7.ZoneAvoidanceRule – 默认规则,复合判断 Server 所在区域的性能和 Server 的可用
行选择服务器。
Ribbon 默认使用哪一个负载均衡算法:
ZoneAvoidanceRule :区间内亲和轮询的算法!通过一个 key 来区分
负载均衡算法:随机 轮训 权重 iphash
(响应时间最短算法,区域内亲和(轮训)算法)
5.如何修改默认的负载均衡算法
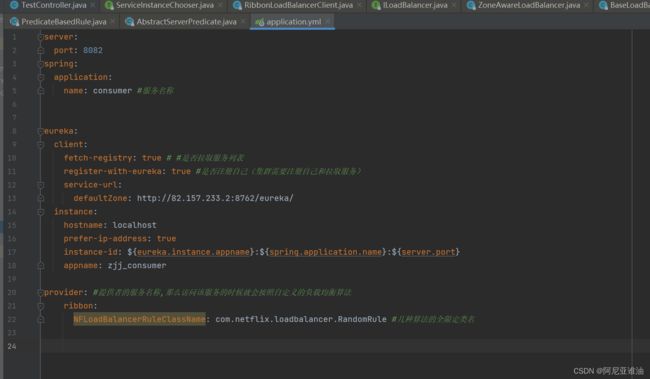
修改 yml 配置文件(指定某一个服务使用什么算法)
provider: #提供者的服务名称,那么访问该服务的时候就会按照自定义的负载均衡算法
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #几种算法的全限定类名
 注意:这里是和eureka并列的位置
注意:这里是和eureka并列的位置
以上方式适合单个服务配置负载均衡策略,如果所有的服务都要修改呢
@Bean
public IRule myRule() {
//指定调用所有的服务都用此算法
return new RandomRule();
}
6.Ribbon 的配置文件和常用配置
Ribbon 有很多默认的配置,查看 DefaultClientConfigImpl
# ribbbon 的一些默认配置
ribbon:
eager-load:
enabled: false # ribbon 只有它自己的话是不能做服务发现的,需要借助eureka 去获取服务列表 这个值为false 就是懒加载
eureka:
enabled: true
http: # 我们使用 ribbon ,用的 restTemplat 发请求 java.net.HttpUrlConnection 发的请求 很方便 但是不支持连接池
client: # 发请求的工具很多,这是其中一种 支持连接池 效率更好 如果想要修改发送请求的工具,需要修改这个依赖
enabled: false # 在 ribbon 最后要发起 Http 的调用调用,我们认为是RestTemplate 完成的,其实最后是 HttpURLConnection 来完成的,这里面设置为 true ,可以把 HttpUrlConnection->HttpClient
okhttp: # 这个也是请求工具,移动端用的较多,轻量级的请求
enabled: false
Ribbon 总结
Ribbon 是客户端实现负载均衡的远程调用组件,用法简单
Ribbon 源码核心:
ILoadBalancer 接口:起到承上启下的作用
- 承上:从 eureka 拉取服务列表
- 启下:使用 IRule 算法实现客户端调用的负载均衡
设计思想:
每一个服务提供者都有自己的 ILoadBalancer
userService—》客户端有自己的 ILoadBalancer
TeacherService—》客户端有自己的 ILoadBalancer
在客户端里面就是 Map
Map
消费者端
服务提供者的名称
value (服务列表 算法规则 )
如何实现负载均衡的呢?
iloadBalancer
loadbalance = iloadBalancers.get(“user-service”)
List servers = Loadbalance.getReachableServers();//缓存起来
Server server = loadbalance .chooseServer(key) //key 是区 id,–》IRule 算法
chooseServer 下面有一个 IRule 算法
IRule 下面有很多实现的负载均衡算法
你就可以使用 eureka+ribbon 做分布式项目
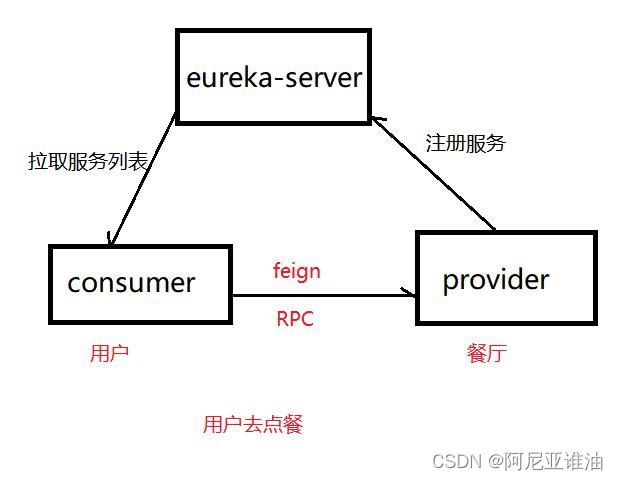
Spring Cloud OpenFeign
之前说 用 Ribbon 做 了 负 载 均 衡 , 用 Eureka-Client 来 做 服 务 发 现 , 通 过 RestTemplate 来完成服务调用,但是这都不是我们的终极方案,终极方案是使用 OpenFeign
OpenFeign 简介
[官网介绍文档](https://docs.spring.io/spring-cloud-openfeign/docs/2.2.4.RELEASE/referenc
e/html/#spring-cloud-feign)
Feign 是声明性(注解)Web 服务客户端。它使编写 Web 服务客户端更加容易。要使用 Feign,请创建一个接口并对其进行注解。它具有可插入注解支持,包括 Feign 注解和 JAX-RS 注解。
Feign 还支持可插拔编码器和解码器。Spring Cloud 添加了对 Spring MVC 注解的支持,并支持使用 HttpMessageConverters,Spring Web 中默认使用的注解。Spring Cloud 集成了 Ribbon 和 Eureka 以及 Spring Cloud LoadBalancer,以在使用 Feign 时提供负载平衡的 http 客户端。
Feign 是一个远程调用的组件 (接口,注解) http 调用的
Feign 集成了 ribbon ribbon 里面集成了 eureka
3.OpenFeign 快速入门
本次调用的设计图
提前启动好 eureka-server
已经发布到虚拟机中
创建 provider
修改服务提供者配置文件
server:
port: 8080
spring:
application:
name: order-provider
eureka:
client:
fetch-registry: true # #是否拉取服务列表
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
instance:
hostname: localhost
prefer-ip-address: true
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
增加一个访问接口
@RestController
@RequestMapping("/order")
public class OrderController {
@GetMapping("/add")
public String doOrder(){
return "有用户来下单了";
}
}
创建consumer
选择依赖
修改配置文件
server:
port: 8081
spring:
application:
name: user-consumer
eureka:
client:
fetch-registry: true # #是否拉取服务列表
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
instance:
hostname: localhost
prefer-ip-address: true
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
创建 @FeignClient 的接口(重点)
/**
* @FeignClient 声明是 feign 的调用
* value = "order-provider" value 后面的值必须和提供者的服务名一致
*/
@FeignClient(value = "order-provider")
public interface UserOrderFegin {
/**
* 下单的方法 这里的路径必须和提供者的路径一致
* 有些方法写在类路径上的要拼到一起
* @return
*/
@GetMapping("/order/add")
public String doOrder();
}
创建 controller
@RestController
@RequestMapping("user")
public class UserController {
@Autowired
UserOrderFegin userOrderFegin;
@GetMapping("/add")
public String addOrder(){
String s = userOrderFegin.doOrder();
return s;
}
}
修改启动类
@SpringBootApplication
@EnableFeignClients(basePackages ={"com.example.userconsumer.fegin"})
@EnableEurekaClient
public class UserConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(UserConsumerApplication.class, args);
}
}
@EnableFeignClients 一定要加,要不feginClient 的接口无法注入
@EnableEurekaClient 可加可不加
为什么@EnableEurekaClient不加也可以
启动调用测试
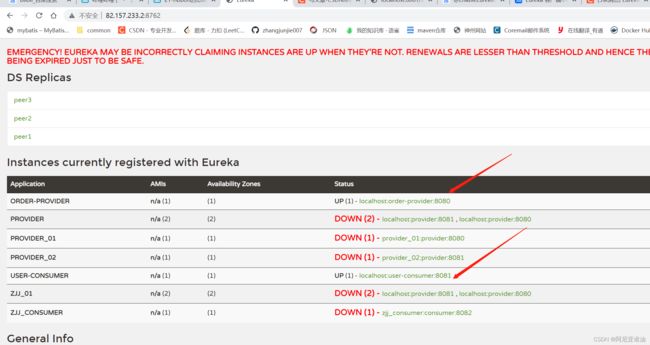
注册中心都注册上了
访问成功
本次调用总结
1、用户服务发起下单请求
2、在用户服务内通过fegin远程嗲用下单服务
3、下单服务相应请求,返回结果
feign 调用的负载均衡
fegin 底层就是ribbon,所以负载均衡就是ribbon的负载均衡
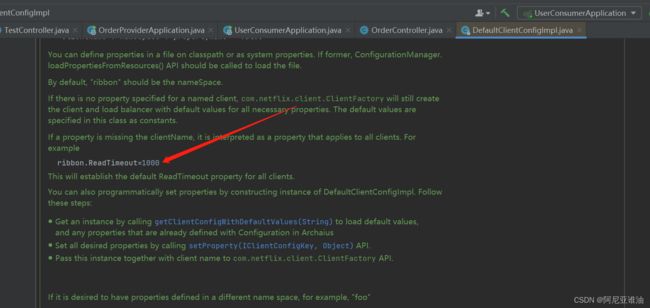
调用超时设置
fegin 没有直接设置超时时间的参数,通过ribbon
因 为 ribbon 默 认 调 用 超 时 时 长 为 1s , 可 以 修 改 , 超 时 调 整可 以 查 看 DefaultClientConfigImpl
修改服务提供者,模拟延迟
@RestController
@RequestMapping("/order")
public class OrderController {
@GetMapping("/add")
public String doOrder(){
try {
TimeUnit.SECONDS.sleep(2l); //休眠2s
} catch (InterruptedException e) {
e.printStackTrace();
}
return "由用户来下单了";
}
}
重启,再次调用接口,超时异常
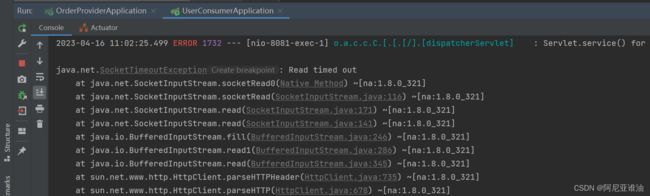
fegin默认超时时间为1 是,如下
修改yml配置,设置fegin调用超时时间
server:
port: 8081
spring:
application:
name: user-consumer
eureka:
client:
fetch-registry: true # #是否拉取服务列表
register-with-eureka: true #是否注册自己(集群需要注册自己和拉取服务)
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
instance:
hostname: localhost
prefer-ip-address: true
instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
ribbon:
ReadTimeout: 3000 # 单位是 ms
手写fegin基本过程
核心思想就是:
1、通过动态代理(基于接口创建是实现类,和cglib动态代理) 创建接口的实现类
2、拿到 FeginClient注解服务名以及接口注解内的路径 拼接成url
3、实现类调用方法再通过restTemplat (本质是 HttpURLConnection) 进行接口访问
@SpringBootTest
class UserConsumerApplicationTests {
@Autowired
RestTemplate restTemplate;
//为什么要在test方法里测试不是main方法,是因为main方法没办法加载spring 的上下文对象
@Test
void contextLoads() {
UserOrderFegin orderFegin = (UserOrderFegin)Proxy.newProxyInstance(this.getClass().getClassLoader(),new Class[]{UserOrderFegin.class}, new InvocationHandler() {
@Override
public String invoke(Object proxy, Method method, Object[] args) throws Throwable {
// return "123";
/**
* invoke 内部就是fegin远程调用的核心
* 拿到 服务名 和接口上的路径
* ribbon会把服务名转为ip和端口
*/
GetMapping annotation = method.getDeclaredAnnotation(GetMapping.class);
//获取 GetMapping注解内的值
String path = annotation.value()[0];
//获取类上feginclient 注解内的值也就是 服务名
FeignClient feignClient = method.getDeclaringClass().getAnnotation(FeignClient.class);
String serverName = feignClient.value();
//拼接url
String url = "http://"+serverName+path;
System.out.println("调用路径:"+url);
String result = restTemplate.getForObject(url, String.class);
System.out.println("调用完毕=========");
return result;
}
});
// 只要 orderFegin执行 方法就会触发上面的 invoke方法
String s = orderFegin.doOrder();
System.out.println(s);
}
}
注意:
这里的restTemplat 需要自己配置以后注入容器中,也就是需要托管给ribbon以后才会根据服务名去找ip。直接注入原生的restTemplat 是不行的
执行结果
OpenFeign 调用参数处理
说在前面
Feign 传参确保消费者和提供者的参数列表一致 包括返回值 方法签名要一致
- 通过 URL 传参数,GET 请求,参数列表使用@PathVariable(“”)
- 如果是 GET 请求,每个基本参数必须加@RequestParam(“”)
- 如果是 POST 请求,而且是对象集合等参数,必须加@Requestbody 或者@RequestParam
修改 provider 增加controller
package com.example.orderprovider.controller;
import com.example.orderprovider.entity.BaseResult;
import com.example.orderprovider.entity.Order;
import org.springframework.web.bind.annotation.*;
@RestController
public class paramTestController {
/**
* 测试单个参数
*
* @param name
* @return
*/
@GetMapping("testOneParam")
public BaseResult oneParam(@RequestParam("name") String name) {
System.out.println(name);
return BaseResult.success(200, "成功", "ok");
}
/**
* 测试两个参数
*
* @param name
* @param age
* @return
*/
@PostMapping("testTwoParam")
public BaseResult twoParam(@RequestParam("name") String name,
@RequestParam("age") Integer age) {
System.out.println(name + ":" + age);
return BaseResult.success(200, "ok", "ok");
}
/**
* 测试一个对象的传参
*
* @param order
* @return
*/
@PostMapping("testObjectParam")
public BaseResult objectParam(@RequestBody Order order) {
System.out.println(order);
return BaseResult.success(200, "ok", order);
}
/**
* 测试一个对象 一个参数
*
* @param order
* @param name
* @return
*/
@PostMapping("testOneObjectOneParam")
public BaseResult oneObjectOneParam(@RequestBody Order order,
@RequestParam String name) {
System.out.println(order);
System.out.println(name);
return BaseResult.success(200, "ok", order);
}
/**
* 测试 url 传参
*
* @param id
* @return
*/
@GetMapping("testUrlParam/{id}")
public BaseResult testUrlParam(@PathVariable("id") Integer id) {
System.out.println(id);
return BaseResult.success(200, "ok", id);
}
}
创建实体类
/**
* 返回结果
*/
@Data
public class BaseResult implements Serializable {
private Integer code;
private String msg;
private Object data;
public static BaseResult success(Integer code, String msg, Object data) {
BaseResult baseResult = new BaseResult();
baseResult.setCode(code);
baseResult.setData(data);
baseResult.setMsg(msg);
return baseResult;
};
/**
* 订单实体类
*/
@Data
@Builder
public class Order implements Serializable {
private String orderSn;
private String orderName;
private String orderDetail;
private Date orderTime;
private String userId;
}
修改 consumer
将 Order 类和 BaseResult 类拷贝过来,后面会抽到公共模块里;
应该作为公共模块被依赖
修改UserOrderFegin
/**
* @FeignClient 声明是 feign 的调用
* value = "order-provider" value 后面的值必须和提供者的服务名一致
*/
@FeignClient(value = "order-provider")
public interface UserOrderFegin {
/**
* 下单的方法 这里的路径必须和提供者的路径一致
* 有些方法写在类路径上的要拼到一起
* @return
*/
@GetMapping("/order/add")
public String doOrder();
//*************************************************** 测试参数接收
@GetMapping("testOneParam")
public BaseResult oneParam(@RequestParam("name") String name);
/**
* 测试两个参数
*
* @param name
* @param age
* @return
*/
@PostMapping("testTwoParam")
public BaseResult twoParam(@RequestParam("name") String name,
@RequestParam("age") Integer age);
/**
* 测试一个对象的传参
*
* @param order
* @return
*/
@PostMapping("testObjectParam")
public BaseResult objectParam(@RequestBody Order order);
/**
* 测试一个对象 一个参数
*
* @param order
* @param name
* @return
*/
@PostMapping("testOneObjectOneParam")
public BaseResult oneObjectOneParam(@RequestBody Order order,
@RequestParam("name") String name);
/**
* 测试 url 传参
*
* @param id
* @return
*/
@GetMapping("testUrlParam/{id}")
public BaseResult testUrlParam(@PathVariable("id") Integer id);
}
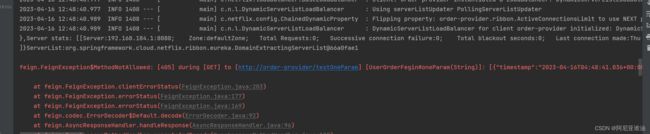
注意:
如果不带 RequestParam 注解或者 RequestBody注解,访问时会报错
如下示例
@GetMapping("testOneParam")
public BaseResult oneParam( String name);// 去掉 RequestParam 注解在进行调用
测试一下
package com.example.userconsumer;
import com.example.userconsumer.entity.BaseResult;
import com.example.userconsumer.entity.Order;
import com.example.userconsumer.fegin.UserOrderFegin;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
public class TestParam {
@Autowired
UserOrderFegin userOrderFegin;
@Test
public void testParamInfo(){
BaseResult aaa = userOrderFegin.oneParam("aaa");
System.out.println("一个参数的结果"+aaa);
System.out.println("--------------------------------------------------");
BaseResult baseResult = userOrderFegin.twoParam("aaa", 12);
System.out.println("两个参数的返回结果:"+baseResult);
System.out.println("--------------------------------------------------");
Order order = Order.builder().userId("1").orderSn("1").orderName("ceshi").orderTime(new Date()).build();
BaseResult baseResult1 = userOrderFegin.objectParam(order);
System.out.println("一个对象的返回结果:"+baseResult);
System.out.println("--------------------------------------------------");
BaseResult cccc = userOrderFegin.oneObjectOneParam(order, "cccc");
System.out.println("一个对象===一个参数的返回结果:"+cccc);
System.out.println("--------------------------------------------------");
BaseResult baseResult2 = userOrderFegin.testUrlParam(111);
System.out.println("url中的参数: "+baseResult2);
}
}
返回结果
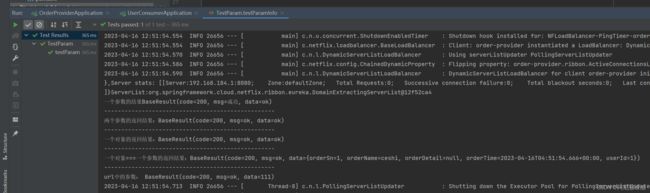
时间日期参数问题
使用 feign 远程调用时,传递 Date 类型,接收方的时间会相差 14 个小时,是因为时区造成
的
服务提供者 :ParamTestController增加方法
// 测试日期传递
@GetMapping("/testDate")
public BaseResult testDate(@RequestParam("testDate")Date testDate){
System.out.println(testDate);
return BaseResult.success(200, "ok","");
}
消费者: UserOrderFegin 同样增加该方法:
/**
* 测试日期传参的问题
* @param testDate
* @return
*/
@GetMapping("/testDate")
public BaseResult testDate(@RequestParam("testDate") Date testDate);
测试调用
@Test
public void testDate(){
Date date = new Date();
System.out.println("发送的日期参数为:"+date);
BaseResult baseResult2 = userOrderFegin.testDate(new Date());
System.out.println("--------------------------------------------------");
Order order = Order.builder().userId("1").orderSn("1").orderName("ceshi").orderTime(new Date()).build();
BaseResult baseResult1 = userOrderFegin.objectParam(order);
}
提供方打印收到的参数
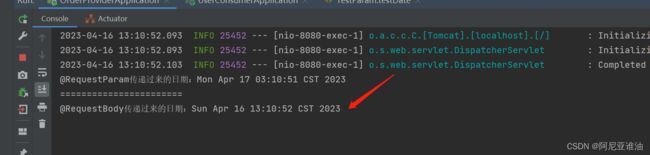
总结:
1、 在feign接口调用时使用表单形式(@RequestParam)传date类型会发生时间精度错乱,在8时区会多14个小时。
2、使用json格式(@RequestBody)传date类型不会发生这种情况。
处理方案:
- 使用字符串传递参数,接收方转换成时间类型(推荐使用)不要单独传递时间
- 使用 JDK8 的 LocalDate(日期) 或 LocalDateTime(日期和时间,接收方只有秒,没有毫秒)
- 自定义转换方法
传参总结:
get 请求只用来传递基本参数 而且加注解@RequestParam
post 请求用来传递对象参数 并且加注解@RequestBody
OpenFeign 源码分析
学习别人的思想,可以找 bug,优化你的代码,提高代码的健壮性)
看源码之前要先大致猜想一下 他是怎么实现的?(先使用在分析)
OpenFeign 的原理是什么?
根据上面的案例,我们知道 feign 是接口调用,接口如果想做事,必须要有实现类。可是我们并没有写实现类,只是加了一个@FeignClient(value=”xxx-service”)的注解
所以我们猜测 feign 帮我们创建了代理对象,然后完成真实的调用。
动态代理 1 jdk (invoke) 2 cglib 子类继承的
- 给接口创建代理对象(启动扫描)
- 代理对象执行进入 invoke 方法
- 在 invoke 方法里面做远程调用
具体我们这次的流程:
A. 扫描注解得到要调用的服务名称和 url

B. 拿到 provider-order-service/doOrder,通过 ribbon 的负载均衡拿到一个服务,
provider-order-service/doOrder—》http://ip:port/doOrder
C. 发起请求,远程调用
fegin常用状态码
只要是 feign 调用出了问题
看 feign 包下面的 Client 接口下面的 108 行
-
200 成功
-
400 请求参数错误
-
401 没有权限
-
403 权限不够
-
404 路径不匹配
-
405 方法不允许
-
500 提供者报错了
-
302 资源重定向
-
200 成功
-
400 请求参数错误
-
401 没有权限
-
403 权限不够
-
404 路径不匹配
-
405 方法不允许
-
500 提供者报错了
-
302 资源重定向
OpenFeign 总结
OpenFeign 主要基于接口和注解实现了远程调用
源码总结:面试
- OpenFeign 用过吗?它是如何运作的?
在 主 启 动 类 上 加 上 @EnableFeignClients 注解 后,启 动会进 行包扫 描,把 所有 加 了
@FeignClient(value=”xxx-service”)注解的接口进行创建代理对象通过代理对象,使用
ribbon 做了负载均衡和远程调用 - 如何创建的代理对象?
当 项 目 在 启 动 时 , 先 扫 描 , 然 后 拿 到 标 记 了 @FeignClient 注 解 的 接 口 信 息 , 由
ReflectiveFeign 类的 newInstance 方法创建了代理对象 JDK 代理 - OpenFeign 到底是用什么做的远程调用?
使用的是 HttpURLConnection (java.net) - OpenFeign 怎么和 ribbon 整合的?
在代理对象执行调用的时候
OpenFeign 其他
OpenFeign 的日志功能
从前面的测试中我们可以看出,没有任何关于远程调用的日志输出,如请头,参数
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别,从而揭开 Feign 中 Http 请求的所有细节
OpenFeign 的日志级别
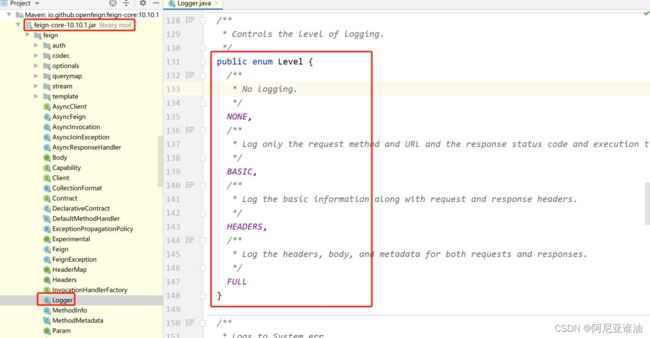
- NONE 默认的,不显示日志
- BASE 仅记录请求方法,URL ,响应状态码及执行时间
- HEADERS 在 BASE 之上增加了请求和响应头的信息
- FULL 在 HEADERS 之上增加了请求和响应的正文及无数据
第一步:创建配置类
package com.example.userconsumer;
@SpringBootApplication
@EnableFeignClients(basePackages ={"com.example.userconsumer.fegin"} )
@EnableEurekaClient
public class UserConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(UserConsumerApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
@Bean
Logger.Level getLevel(){
return Logger.Level.FULL;
}
}
第二步:修改配置文件
logging:
level:
com.example.userconsumer.fegin.UserOrderFegin: debug
查看结果

Spring Cloud Hystrix
前言
什么是服务雪崩
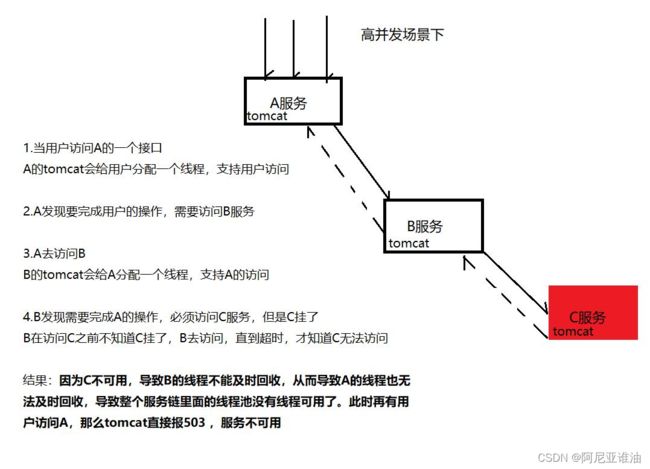
服务雪崩的本质:线程没有及时回收。
不管是调用成功还是失败,只要线程可以及时回收,就可以解决服务雪崩
服务雪崩怎么解决
- 修改调用的超时时长(不推荐)
将服务间的调用超时时长改小,这样就可以让线程及时回收,保证服务可用
优点:非常简单,也可以有效的解决服务雪崩
缺点:不够灵活,有的服务需要更长的时间去处理(写库,整理数据)
-
设置拦截器
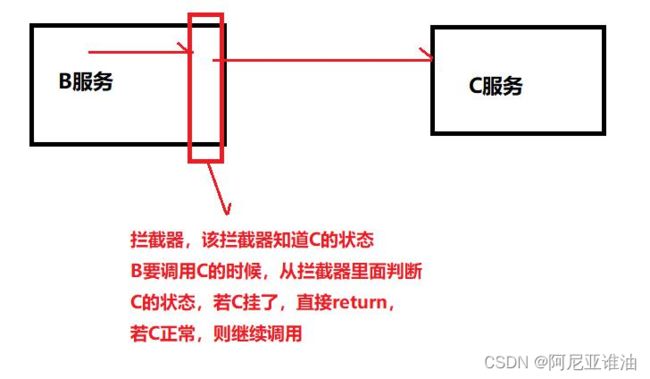
Spring Cloud Hystrix 简介
熔断器,也叫断路器!(正常情况下 断路器是关的 只有出了问题才打开)
用来保护微服务不 雪崩的方法。思想和我们上面画的拦截器一样。 Hystrix 是 Netflix 公司开源的一个项目,它提供了熔断器功能,能够阻止分布式系统中出现
联动故障。Hystrix 是通过隔离服务的访问点阻止联动故障的,并提供了故障的解决方案,从
而提高了整个分布式系统的弹性。 微博 弹性云扩容 Docker K8s
Hystrix 快速入门
当有服务调用的时候,才会出现服务雪崩,所以 Hystrix 常和 OpenFeign,Ribbon 一起出现
tips:
openfeign中已经集成了负载均衡、断路器等功能,不需要再引入相关依赖,但是ribbon没有
创建提供者
1、application.yml
server:
port: 8080
spring:
application:
name: order-provider
eureka:
client:
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
fetch-registry: true
register-with-eureka: true
instance:
hostname: localhost # 这里的名称不能乱写,要么是 localhost 要么是ip ,后续访问会识别这个
instance-id: ${eureka.instance.hostname}:${spring.application.name}
2、编写业务代码
package com.example.providerorder.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OrderController {
@GetMapping("/doOrder")
public String doOrder(){
System.out.println("我来提供服务了");
return "下单成功";
}
}
3、启动类开启eureka客户端
@SpringBootApplication
@EnableEurekaClient
public class ProviderOrderApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderOrderApplication.class, args);
}
}
创建消费者
1、application.yml
server:
port: 8081
spring:
application:
name: user-consumer
eureka:
client:
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
register-with-eureka: true
fetch-registry: true
instance:
instance-id: ${eureka.instance.hostname}:${spring.application.name}
hostname: localhost
feign:
hystrix:
enabled: true # 开启断路器,默认是关闭
2、编写FeignClient接口
package com.example.consumeruser.fegin;
import com.example.consumeruser.hystrix.OrderProviderHystrix;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
/**
* fallback 指定的是断路器对应的类(也就是服务提供者发生异常以后要执行的逻辑)
*/
@FeignClient(value = "order-provider",fallback = OrderProviderHystrix.class)
public interface UserOrderFegin {
@GetMapping("/doOrder")
public String doOrder();
}
3、断路器接口内容
开发步骤:
1、编写断路器实现类实现FeignClient接口,重写接口返回值方法
2、声明为spring组件(加上 @Component)
3、FeignClient注解内部,指定 fallback属性为 刚开发的实现类
4、配置文件中 hyxtrix开关开启
package com.example.consumeruser.hystrix;
import com.example.consumeruser.fegin.UserOrderFegin;
import org.springframework.stereotype.Component;
@Component
public class OrderProviderHystrix implements UserOrderFegin {
@Override
public String doOrder() {
System.out.println("进入熔断逻辑了");
return "我是备胎";
}
}
4、编写消费者的业务代码
package com.example.consumeruser.controller;
import com.example.consumeruser.fegin.UserOrderFegin;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@Autowired
private UserOrderFegin userOrderFegin;
@GetMapping("/addOrder")
public String addOrder(){
System.out.println("用户来消费了");
return userOrderFegin.doOrder();
}
}
5、启动类打开开关
package com.example.consumeruser;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients(basePackages = {"com.example.consumeruser.fegin"})
public class ConsumerUserApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerUserApplication.class, args);
}
}
调用
1、当服务者正常提供服务的时候,请求正常返回
2、当服务者挂掉的时候,如果断路器没有开启,页面报错
断路器开启,页面走备用逻辑

Ribbon 中使用 Hystrix(了解)
1、 启动 eureka-server
2、 启动 provider-order-service
3、 修改 consumer-user-service
3.1、 添加 Hystrix 的依赖,ribbon 没有集成 hystrix
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
3.2 修改启动类
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
@EnableCircuitBreaker
//开启断路器
public class ConsumerUserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerUserServiceApplication.class, args);
}
}
3.3 修改 controller
/**
* 用户下单方法
ribbon 的熔断
*
* @return
* @HystrixCommand(fallbackMethod = "ribbonHystrix")
* 指定熔断的方法
*/
@GetMapping("userDoOrderRibbon")
@HystrixCommand(fallbackMethod = "ribbonHystrix")
public String testRibbonHystrix(String serviceId) {
String result = restTemplate.getForObject("http:" + serviceId + "/doOrder", String.class);
System.out.println(result);
return "成功";
}
//方法签名要和原来的方法一致
public String ribbonHystrix(String serviceId) {
return "我是 ribbon 的备选方案";
}
手写断路器
断路器的设计
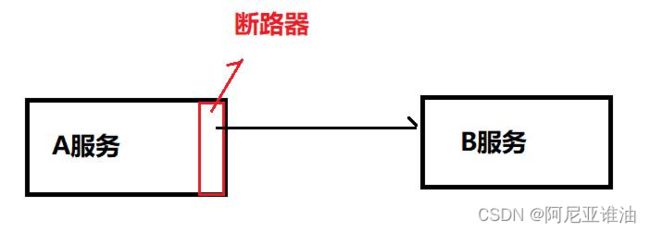
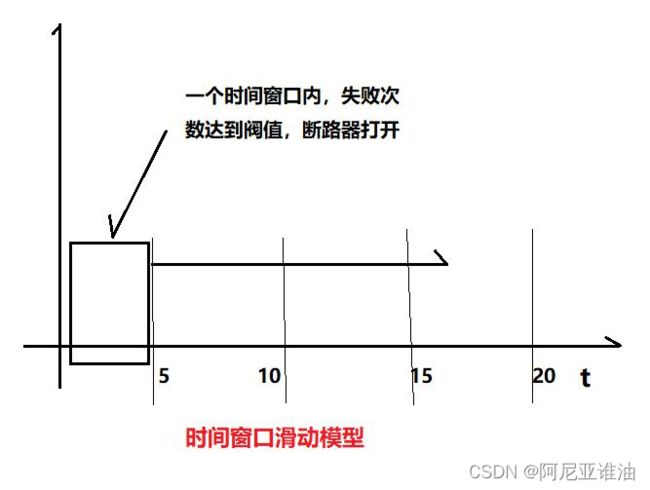
断路器的状态说明以及状态转变
关: 服务正常调用 A—》B
开: 在一段时间内,调用失败次数达到阀值(5s 内失败 3 次)(5s 失败 30 次的)则断路器
打开,直接 return
半开:断路器打开后,过一段时间,让少许流量尝试调用 B 服务,如果成功则断路器关闭,
使服务正常调用,如果失败,则继续半开
开始设计断路器模型
创建断路器状态模型
package com.example.consumeruserdiy.myHystrix;
public enum HystrixStatus {
OPEN(0,"打开"),
CLOSE(1,"关闭"),
HALF_OPEN(2,"半开");
HystrixStatus (Integer status,String desc){
}
}
创建断路器 MyHystrix
package com.example.consumeruserdiy.myHystrix;
import lombok.Data;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Data
public class MyHystrix {
/**
* 断路器状态 默认是关闭的
*/
private HystrixStatus hystrixStatus = HystrixStatus.CLOSE;
/**
* 断路器的窗口时间 默认是5s
* (这个属性是属于类的,所以用的是static)
*/
private static final Long WINDOWS_SLEEP_TIME = 5L;
/**
* 最大失败次数 全剧 阈值
*/
private static final Integer MAX_FAIL_COUNT = 3;
/**
* 当前对象的失败次数
*/
private AtomicInteger currentFailCount = new AtomicInteger(0);
/**
* 定义对象的一个线程池属性
*/
private ExecutorService dealSatusPool = Executors.newFixedThreadPool(5);
/**
* 定义对象的锁,优化线程等待时间
*/
private Object lock = new Object();
//如何实现每个 5s 内 统计到失败次数达到阀值呢? 看清楚是每个5s
// 可以每 5s 清空一下失败次数 (对象创建就调用)
{System.out.println("初始化以后,----我来执行了");
dealSatusPool.execute(()->{
while (true){
try {
if (this.getHystrixStatus().equals(HystrixStatus.CLOSE)){
TimeUnit.SECONDS.sleep(5l);
//5s 以后 清空失败次数
this.currentFailCount.set(0);
System.out.println("定时把次数清0");
}else {
synchronized (lock){
lock.wait();
//当半开调用成功以后,线程被唤醒了,往下执行,又开始了循环统计了
System.out.println("测试调用成功,我们统计线程再次启动");
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 调用失败时,失败次数+1
*/
public void failCount() {
//失败次数+1
this.currentFailCount.incrementAndGet();
//超过最大次数 断路器打开
if (this.currentFailCount.get()>=MAX_FAIL_COUNT){
this.setHystrixStatus(HystrixStatus.OPEN);
//断路器不能一直开着啊 异步处理 把断路器状态改为半开
dealSatusPool.execute(()->{
try {
System.out.println("执行了线程池");
TimeUnit.SECONDS.sleep(3);
this.setHystrixStatus(HystrixStatus.HALF_OPEN);
this.currentFailCount.set(0);
System.out.println("设置完半开以后,把次数清0");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
/**
* 半开状态下 调用成功
*/
public void invokeSuccess() {
this.setHystrixStatus(HystrixStatus.CLOSE);
this.currentFailCount.set(0);
}
}
自定义需要熔断处理的注解
package com.example.consumeruserdiy.myannotation;
import java.lang.annotation.*;
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Inherited
public @interface MyAnnotation {
String value() default "";
}
注解的切面处理
package com.example.consumeruserdiy.myannotation;
import com.example.consumeruserdiy.myHystrix.MyHystrix;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
@Component
@Aspect
public class HyxtrixAspect {
/**
* 模拟在服务调用时,会拿到当前调用服务的断路器对象进行处理
*/
private static Map<String, MyHystrix> provider_service = new HashMap<>();
static {
provider_service.put("order-provider",new MyHystrix());
}
/**
* Aop 切入点
*/
// public static final String POINTCUT = "execution(* com.example.consumeruserdiy.controller.testRpc(..))";
@Around(value = "@annotation(com.example.consumeruserdiy.myannotation.MyAnnotation)")
public Object hyxtrixAround(ProceedingJoinPoint joinPoint) throws Throwable {
System.out.println("进入切面了");
String result = "";
MyHystrix curHyxtrix = provider_service.get("order-provider");
switch (curHyxtrix.getHystrixStatus()){
case OPEN:
result = "我是断路器打开状态下,返回的备胎";
break;
case CLOSE:
try {
Object proceed = joinPoint.proceed();
result = (String) proceed;
} catch (Throwable e) {
//调用失败 失败次数+1
curHyxtrix.failCount();
result = "我是断路器关闭状态下,调用异常,返回的备胎";
};
break;
case HALF_OPEN:
int i = (int)(Math.random() * 5) + 1;
System.out.println("随机数字:"+i);
if (i==1){
// 少许流量尝试去调用服务 看看服务有没有起来
try {
Object proceed = joinPoint.proceed();
// 调用成功 关闭断路器 次数清0
curHyxtrix.invokeSuccess();
result = (String) proceed;
break;
} catch (Throwable e) {
curHyxtrix.failCount();
System.out.println("少许流量调用失败");
result = "半开状态下,调用失败";
break;
}
}
default:
result = "半开状态下,直接返回备胎";
}
return result;
}
}
测试访问
可以根据熔断器状态走入不同的处理逻辑
总结:
1、设置对象属性时,是否需要用static,品读一下
设置属性时,有些属性是属于类的,比如窗口期,最大失败次数等,可以用static进行修饰,特别是那些不会修改的,可以再加上final作为常量使用,像当前失败次数这种,是属于对象的,不能用static
2、自定义注解时,可以直接使用@Around注解种的value属性指定切入点
3、代码块是在对象创建的时候去执行,在里面可以设置一个线程池定时去执行任务(如果有在类初始化完成以后就需要循环执行的业务逻辑的话)
Hystrix 的常用配置
server:
port: 8081
spring:
application:
name: consumer-user-service
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/
fetch-registry: true
register-with-eureka: true
instance:
instance-id: ${spring.application.name}:${server.port}
prefer-ip-address: true
feign:
hystrix:
enabled: true
hystrix: #hystrix 的全局控制
command:
default: #default 是全局控制,也可以换成单个方法控制,把 default 换成方法名即可
fallback:
isolation:
semaphore:
maxConcurrentRequests: 1000 #信号量隔离级别最大并发数
circuitBreaker:
enabled: true #开启断路器
requestVolumeThreshold: 3 #失败次数(阀值)
sleepWindowInMilliseconds: 20000 #窗口时间
errorThresholdPercentage: 60 #失败率
execution:
isolation:
Strategy: thread #隔离方式 thread 线程隔离集合和 SEMAPHORE 信号量隔离级别
thread:
timeoutInMilliseconds: 3000 #调用超时时长
ribbon:
ReadTimeout: 5000 #要结合 feign 的底层 ribbon 调用的时长
ConnectTimeout: 5000
隔离方式 两种隔离方式
1、thread 线程池 按照 group(10 个线程)划分服务提供者,用户请求的线程 和做远程的线程不一样好处:
当 B 服务调用失败了 或者请求 B 服务的量太大了 不会对 C 服务造成影响 用户访问比较大的情况下使用比 较好 异步的方式
缺点:
线程间切换开销大,对机器性能影响
应用场景: 调用第三方服务 并发量大的情况下
2、SEMAPHORE 信号量隔离
每次请进来 有一个原子计数器 做请求次数的++,当请求完成以后 –
好处:
对 cpu 开销小
缺点:
并发请求不易太多 当请求过多 就会拒绝请求 做一个保护机制
场景: 使用内部调用 ,并发小的情况下
源码入门
HystrixCommand AbstractCommand HystrixThreadPool
Feign 的工程化实例
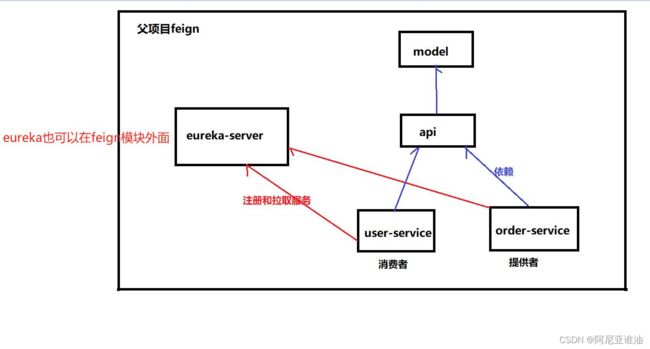
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LvXp9kL0-1682254688204)(C:\Users\17310\AppData\Roaming\Typora\typora-user-images\image-20230419221157991.png)]
注意:
1、每个boot项目只有一个父项目,可以让最外层项目的父项目为springboot,子项目依赖外层父项目即可
2、整体思想就是实体类抽取出一个模块,接口抽取出一个模块、订单服务以及用户分别是一个模块
然后api依赖domain ,然后user和order 再分别去依赖api
dubbo 中,其实会把api和domain放在一个模块,让别的服务直接去依赖
1、创建父工程 openfegin-project
父项目主要用来做依赖管理和版本控制的,并没有什么代码
这里主要明白父项目中pom文件的含义:
- : 子模块,子模块创建以后会自动生成
- : 父项目的依赖,依赖boot,其内部有约束相对应依赖的版本,在引入时可以不指定版本
- :全局版本控制的地方
- :这里的依赖所有的子模块都会有
- : 加载这里的依赖不会真的被引入项目,只是做了一个版本控制
- : 打包、仓库相关配置
父节点的pom:
4.0.0
org.example
openfegin-project
pom
1.0-SNAPSHOT
project-domain
common-api
order-center
user-center
org.springframework.boot
spring-boot-starter-parent
2.3.12.RELEASE
8
8
1.8
Hoxton.SR12
org.projectlombok
lombok
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
2、创建子模块
分别创建 project-domain、common-api、order-center、user-center 子模块。
创建的时候直接用原生的maven就行,方便指定父项目,也可以创建boot,后面需要在pom手动设置父项目
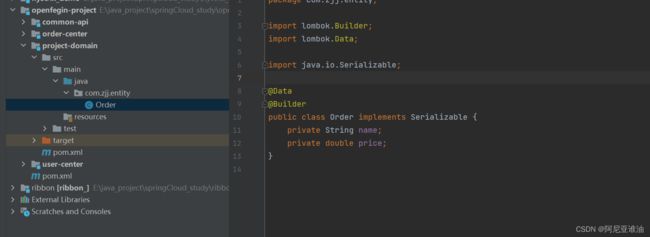
project-domain:
只包含实体类,结构比较简单
common-api
主要是开发接口,包括对应熔断
该接口会在order-center中的controller进行开发,并且会在user-center 中进行调用,所以这里会打成jar包让两个服务都依赖;
order-center :可以直接实现这个接口
user-center :正常注入 实现
order-center
需要独立部署,所以要引入web和eureka依赖,需要注册到注册中心
controller可以按照实现接口的方式实现**:**
如果不这么实现,方法签名一定要和api服务中的OrderFegin保持一致
@RestController
public class OrderController implements OrderFegin {
@Override
public Order doOrder() {
System.out.println("有人来下单了");
return Order.builder().name("我来下单了").price(20).build();
}
}
自己创建boot启动类
@SpringBootApplication
@EnableEurekaClient
public class OrderCenterApplication {
public static void main(String[] args) {
SpringApplication.run(OrderCenterApplication.class,args);
}
}
user-center
同order,需要独立部署,所以要引入web和eureka依赖,需要注册到注册中心
注意:调用消费者服务时,要开启FeginClient 以及熔断
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
public class UserCenterApplication {
public static void main(String[] args) {
SpringApplication.run(UserCenterApplication.class,args);
}
}
开启熔断
server:
port: 8081
spring:
application:
name: user-consumer
eureka:
client:
service-url:
defaultZone: http://82.157.233.2:8762/eureka/
register-with-eureka: true
fetch-registry: true
instance:
instance-id: ${eureka.instance.hostname}:${spring.application.name}
hostname: localhost
feign:
hystrix:
enabled: true # 开启断路器,默认是关闭
总结
就是项目工程的一种构建方式
1、创建父项目,管理依赖以及版本号等
2、开发domain以及api服务,让消费者和提供者共同去依赖
3、提供者直接实现接口开发服务,消费者按照之前的方式进行开发
Spring Cloud Sleuth
什么是链路追踪
链路追踪就是:追踪微服务的调用路径
链路追踪的由来
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协
同产生最后的请求结果,每一个请求都会开成一条复杂的分布式服务调用链路,链路中的任何
一环出现高延时或错误都会引导起整个请求最后的失败。(不建议微服务中链路调用超过 3 次)
分布式链路调用的监控
sleuth+zipkin(zipkin 就是一个可视化的监控控制台)
Zipkin 是 Twitter 的一个开源项目,允许开发者收集 Twitter 各个服务上的监控数据,并提
供查询接口。
该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处
理时间等,可方便的监测系统中存在的瓶颈
Zipkin(可视化平台)
1、下载 zipkin
SpringCloud 从 F 版以后已不需要自己构建 Zipkin server 了,只需要调用 jar 包即可
https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/
2、运行 zipkin
java -jar zipkin-server-2.12.9-exec.jar
3、查看 zipkin 的控制台
http://localhost:9411
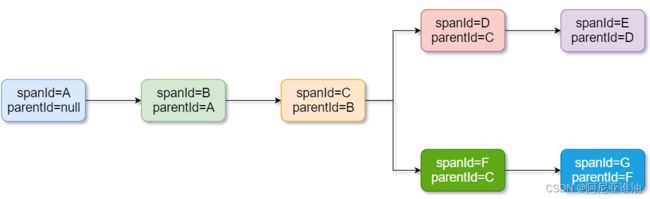
相关术语和名词解释
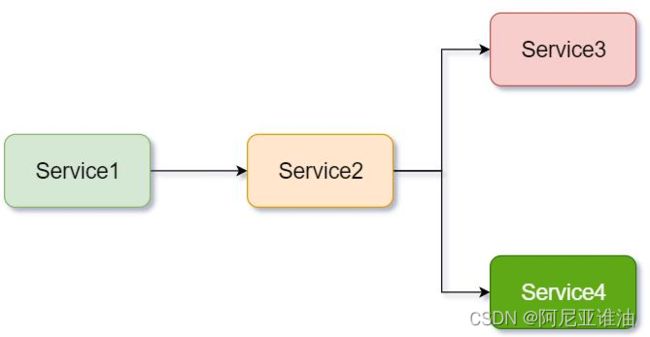
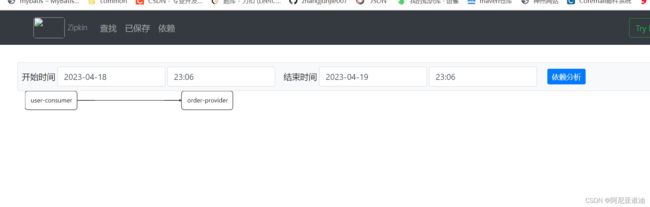
调用链路的依赖关系
Sleuth 快速入门
添加依赖
org.springframework.cloud
spring-cloud-starter-zipkin
修改配置文件
consumer-user-service 和 provider-order-service 都要该配置文件
server:
port: 8081
spring:
application:
name: user-consumer
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1 #配置采样率 默认的采样比例为: 0.1,即 10%,所设的置的值介于 0 到 1 之间,1 则表示全部采集
rate: 10 #为了使用速率限制采样器,选择每秒间隔接受的 trace 量,最小数字为 0,最大值为 2,147,483,647(最大 int) 默认为 10。
启动访问,远程调用一下
查看 zipkin
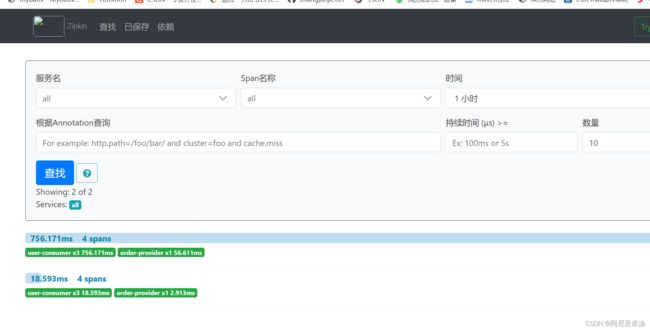
点一下依赖
Admin监控(略)
Spring Cloud Gateway
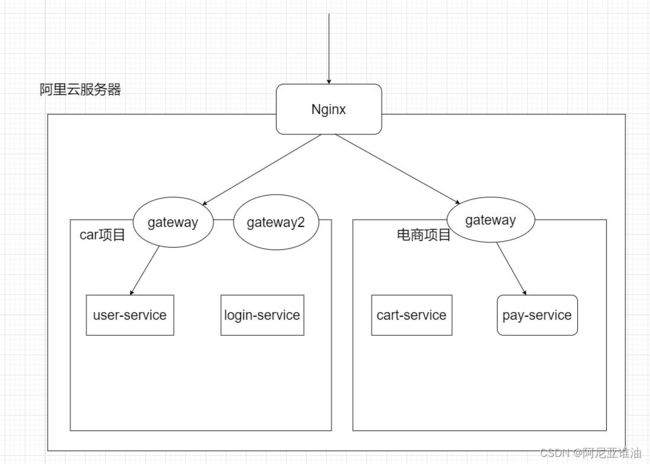
1.什么是网关
网关是微服务最边缘的服务,直接暴露给用户,用来做用户和微服务的桥梁
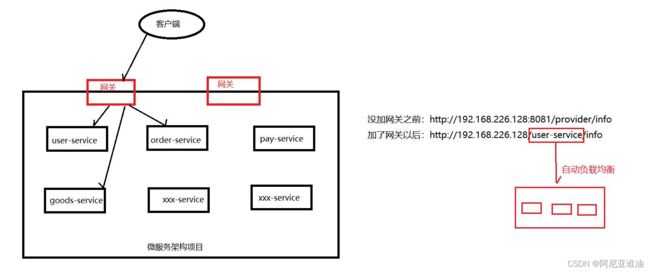
-
没有网关:客户端直接访问我们的微服务,会需要在客户端配置很多的 ip:port,如果
user-service 并发比较大,则无法完成负载均衡 -
有网关:客户端访问网关,网关来访问微服务,(网关可以和注册中心整合,通过服务名
称找到目标的 ip:prot)这样只需要使用服务名称即可访问微服务,可以实现负载均衡,可
以实现 token 拦截,权限验证,限流等操作
2.Spring Cloud Gateway 简介
你们项目里面 用的什么网关? gateway zuul
它是 Spring Cloud 官方提供的用来取代 zuul(netflix)的新一代网关组件
(zuul:1.0 , 2.0 ,zuul 的本质,一组过滤器,根据自定义的过滤器顺序来执行,本质就是web 组件
web 三大组件(监听器(listener) 过滤器(filter) servlet):
拦截器:springMVC内容,主要用来拦截controller请求
过滤器:除了访问controller还包括静态资源、cs等其他请求(范围更广)
Zuul1.0 使用的是 BIO(Blocking IO) tomcat7.0 以前都是 BIO 性能一般
Zuul2.0 性能好 NIO
AIO 异步非阻塞 io a+nio = aio = async + no blocking io
它基于 spring5.x,springboot2.x 和 ProjectReactor 等技术。
它的目地是让路由更加简单,灵活,还提供了一些强大的过滤器功能,例如:熔断、限流、重
试,自义定过滤器等 token 校验 ip 黑名单等
SpringCloud Gateway作为Spring Cloud生态的网关,目标是替代Zuul,在SpringCloud2.0
以上的版本中,没有对新版本的 zuul2.0 以上的最新高性能版本进行集成,仍然还是使用的
zuul1.x[可 以 看项 目 依 赖 找 到] 非 Reactor 模式的老版本。而为了提升网关的性能,
SpringCloud Gateway 是基于 webFlux 框架实现的,而 webFlux 框架底层则使用了高性能
的 Reactor 模式通信框架的 Netty

3.Spring Cloud Gateway 工作流程
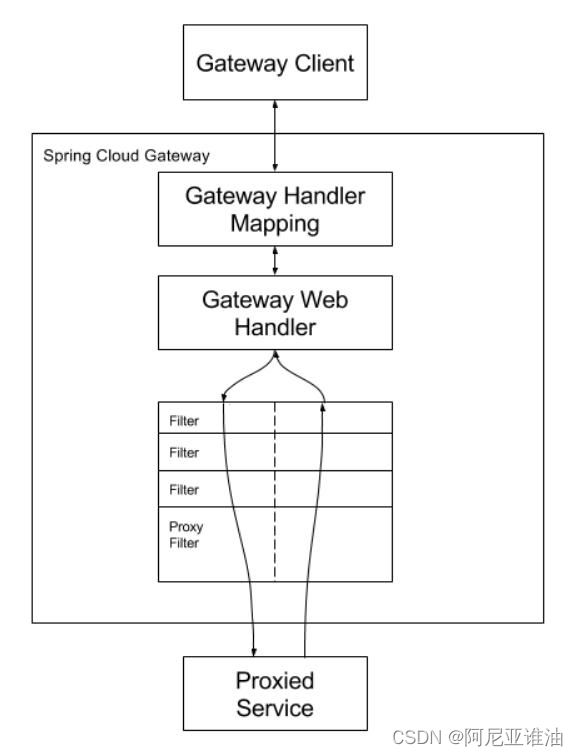
- 客户端向 springcloud Gateway 发出请求,然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。
- Handler 再通过指定的过滤器来将请求发送到我们实际的服务的业务逻辑,然后返回。 过滤器之间用虚线分开是因为过滤器可能会在发送请求之前【pre】或之后【post】执行业务逻辑,对其进行加强或处理。
- Filter 在 【pre】 类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等
- 在【post】 类型的过滤器中可以做响应内容、响应头的修改、日志的输出,流量监控等有着非常重要的作用。
总结:Gateway 的核心逻辑也就是 路由转发 + 执行过滤器链
4.Spring Cloud Gateway 三大核心概念
4.1 Route(路由)(重点 和 eureka 结合做动态路由)
路由信息的组成:
由一个 ID、一个目的 URL、一组断言工厂、一组 Filter 组成。
如果路由断言为真,说明请求 URL 和配置路由匹配
4.2 Predicate(断言)(就是一个返回 bool 的表达式)
Java 8 中的断言函数。 lambda 四大接口 供给形,消费性,函数型,断言型
Spring Cloud Gateway 中 的 断 言 函 数 输 入 类 型 是 Spring 5.0 框 架 中 的 ServerWebExchange。Spring Cloud Gateway 的断言函数允许开发者去定义匹配来自于 Http Request 中的任何信息比如请求头和参数。
4.3 Filter(过滤) (重点)
一个 标准的 Spring WebFilter。 Web 三大组件(servlet listener filter)
Spring Cloud Gateway 中的 Filter 分为两种类型的 Filter,分别是 Gateway Filter 和 Global Filter。过滤器 Filter 将会对请求和响应进行修改处理。
一个是针对某一个路由(路径)的 filter :
功能: 对某一个接口做限流
一个是针对全局的 filter:
功能:token ip 黑名单
5.Nginx 和 Gateway 的区别
Nginx 在做路由,负载均衡,限流之前,都有修改 nginx.conf 的配置文件,把需要负载均衡,路由,限流的规则加在里面。Eg:使用 nginx 做 tomcat 的负载均衡
但是 gateway 不同,gateway 自动的负载均衡和路由,gateway 和 eureka 高度集成,实现自动的路由,和 Ribbon 结合,实现了负载均衡(lb),gateway 也能轻易的实现限流和权限验证。
Nginx(c)比 gateway(java)的性能高一点。
本质的区别呢?
Nginx:(更大 服务器级别的)
Gateway: (项目级别的)
6.Gateway 快速入门
路由
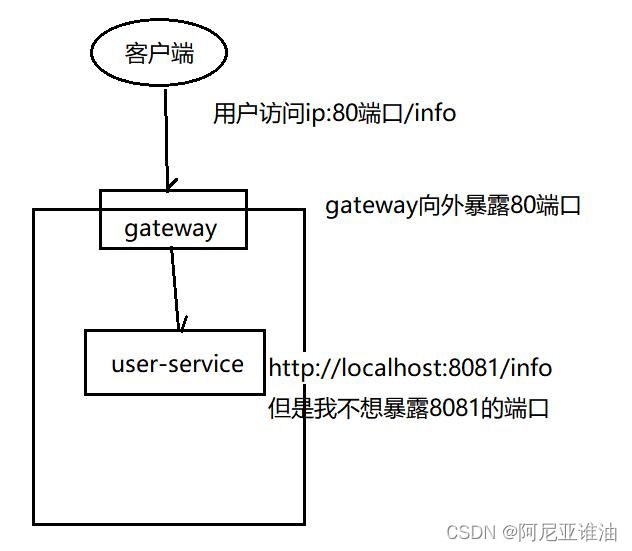
6.1 本次访问流程
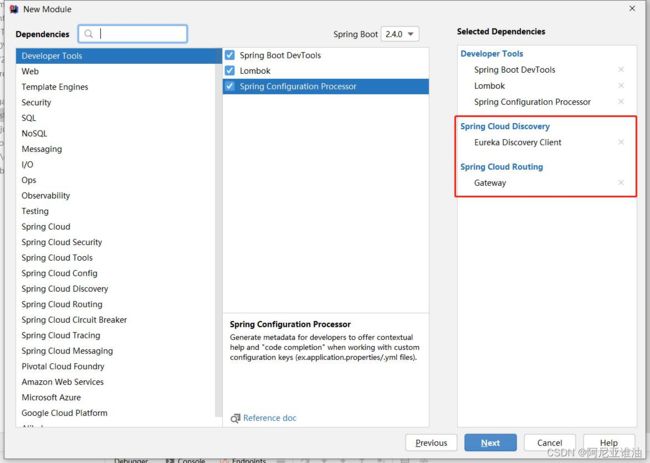
6.2 新建项目选择依赖(不要选 web)
(先不注册eureka)
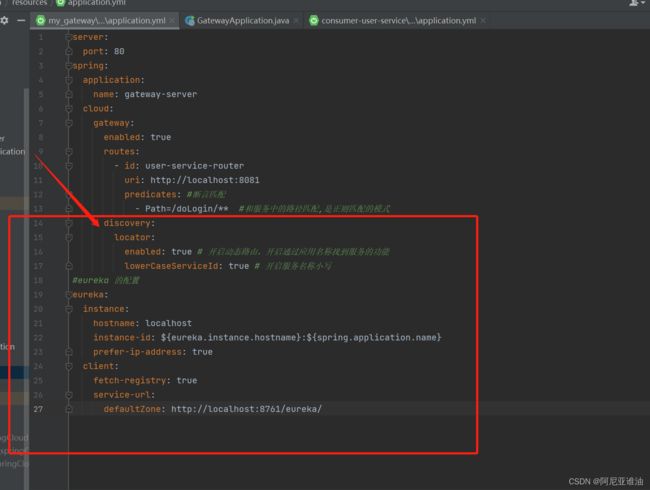
6.3 修改配置文件
server:
port: 80
spring:
application:
name: gateway-server
cloud:
gateway:
enabled: true
routes:
- id: user-service-router
uri: http://localhost:8081
predicates: #断言匹配
- Path=/doLogin #和服务中的路径匹配,是正则匹配的模式

6.4 写一个user-service服务
此时gateway并没有注册eureka,所以user服务是否注册eureka都没有关系
@RestController
public class UserController {
@RequestMapping("/doLogin")
public String doLogin(){
return UUID.randomUUID().toString();
}
}
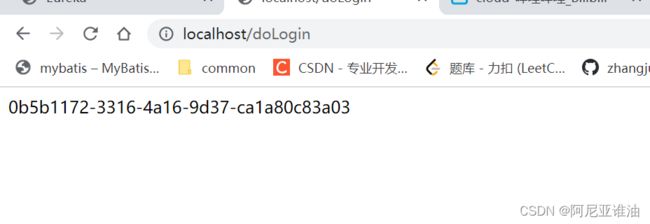
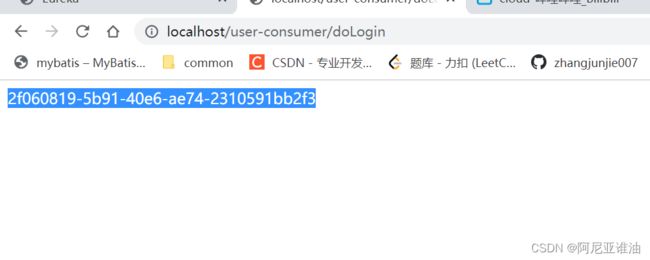
6.5 页面访问 localhost:80/doLogin
自动跳转到user服务
6.6 代码方式配置路由
参考官网写法
package com.zjj.config;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DiyGateWay {
/**
* 代码方式的路由,和yml不冲突
* 如果你 uri 后面跟了一个地址和 path 里面地址一致,它不会再拼接
* @param builder
* @return
*/
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes().
route("user-login", r -> r.path("/doLogin").uri("http://localhost:8081"))
.route("redirect-other", r -> r.path("/v/aaa").uri("http://www.baidu.com"))
.route("redirect-other", r -> r.path("/index.html").uri("https://tieba.baidu.com/index.html")) //不会再进行拼接
.build();
}
}
如下图,可定位到别的网络
6.7 通配符
一个模块可以加一个前缀,后面用通配符的方式,直接跳转
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("user-login", r -> r.path("/doLogin").uri("http://localhost:8081"))
.route("user-login", r -> r.path("/doLogin/**").uri("http://localhost:8081"))
.route("redirect-other", r -> r.path("/v/aaa").uri("http://www.baidu.com"))
.route("redirect-other", r -> r.path("/index.html").uri("https://tieba.baidu.com/index.html")) //不会再进行拼接
.build();
}
注意:
这个通配符可以用正则的方式使用
当然yml配置文件也可以使用
server:
port: 80
spring:
application:
name: gateway-server
cloud:
gateway:
enabled: true
routes:
- id: user-service-router
uri: http://localhost:8081
predicates: #断言匹配
- Path=/doLogin/** #和服务中的路径匹配,是正则匹配的模式
6.8 分析问题
以上方式路由针对单个服务确实可以,如果服务是以集群的形式出现呢?不能只设置一台。
怎么做动态路由呢?
1、把gateway服务也注册到eureka注册中心去,eureka可以根据服务名称获取到所有服务的ip和端口
2、把user等集群中所有的服务都注册上去,进行路由调用
注意:Gateway在开启了自动路由之后,自带负载均衡
6.8.1 改造为动态路由
@SpringBootApplication
@EnableEurekaClient
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class,args);
}
}
同样的,消费者也要注册到eureka中
注释掉routes,直接用服务名进行调用
server:
port: 80
spring:
application:
name: gateway-server
cloud:
gateway:
enabled: true
# routes:
# - id: user-service-router
# uri: http://localhost:8081
# predicates: #断言匹配
# - Path=/doLogin/** #和服务中的路径匹配,是正则匹配的模式
discovery:
locator:
enabled: true # 开启动态路由,开启通过应用名称找到服务的功能
lowerCaseServiceId: true # 开启服务名称小写
#eureka 的配置
eureka:
instance:
hostname: localhost
instance-id: ${eureka.instance.hostname}:${spring.application.name}
prefer-ip-address: true
client:
fetch-registry: true
service-url:
defaultZone: http://localhost:8761/eureka/
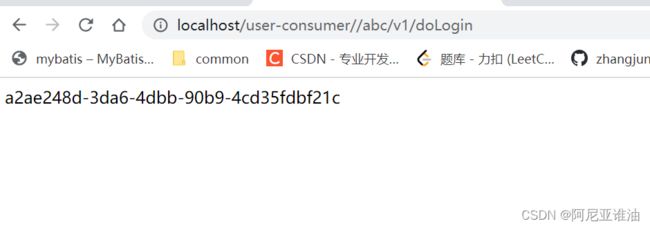
6.8.2 结果
服务名调用,可以直接根据路径的服务前缀,直接路由到对应的服务
如果不些服务名,默认不走动态路由,还是按路径匹配的规则
Predicate 断言工厂【了解】
在 gateway 启动时会去加载一些路由断言工厂(判断一句话是否正确 一个 boolean 表达式 )
[官网说明](https://docs.spring.io/spring-cloud-gateway/docs/2.2.5.RELEASE/reference/html/#g
ateway-request-predicates-factories)
什么是断言,Gateway 里面有哪些断言
断言就是路由添加一些条件(丰富路由功能的)
通俗的说,断言就是一些布尔表达式,满足条件的返回 true,不满足的返回 false。Spring Cloud Gateway 将路由作为 Spring WebFlux HandlerMapping 基础架构的一部分进行匹配。Spring Cloud Gateway 包括许多内置的路由断言工厂。所有这些断言都与 HTTP请求的不同属性匹配。您可以将多个路由断言可以组合使用
Spring Cloud Gateway 创建对象时,使用 RoutePredicateFactory 创建 Predicate 对象,
Predicate 对象可以赋值给 Route。
如何使用这些断言
使用断言判断时,我们常用 yml 配置文件的方式进行配置
server:
port: 80
spring:
application:
name: gateway-server
cloud:
gateway:
enabled: true
routes: #设置路由,注意是数组,可以设置多个,按照 id 做隔离
- id: user-service-router #路由 id,没有要求,保持唯一即可
uri: lb://provider #使用 lb 协议 微服务名称做负均衡
predicates: #断言匹配
- Path=/doLogin/**
#和服务中的路径匹配,是正则匹配的模式
- After=2020-01-20T17:42:47.789-07:00[Asia/Shanghai]
#此断言匹配发生在指定日期时间之后的请求,ZonedDateTime dateTime=ZonedDateTime.now()获得
- Before=2020-06-18T21:26:26.711+08:00[Asia/Shanghai]
#此断言匹配发生在指定 日期时间之前的请求
- Between=2020-06-18T21:26:26.711+08:00[Asia/Shanghai],2020-06-18T21:32:26.711+08:00[Asia/Shanghai]
#此断言匹配发生在指定日期时间之间的请求
- Cookie=name,xiaobai
#Cookie 路由断言工厂接受两个参数,Cookie 名称和 regexp(一个 Java 正则表达式)。此断言匹配具有给定名称且其值与正则表达式匹配的 cookie
- Header=token,123456
#头路由断言工厂接受两个参数,头名称和 regexp(一个 Java 正则表达式)。此断言与具有给定名称的头匹配,该头的值与正则表达式匹配。
- Host=**.bai*.com:*
#主机路由断言工厂接受一个参数:主机名模式列表。该模式是一个 ant 样式的模式。作为分隔符。此断言匹配与模式匹配的主机头
- Method=GET,POST
#方法路由断言工厂接受一个方法参数,该参数是一个或多个参数: 要匹配的 HTTP 方法
- Query=username,cxs
#查询路由断言工厂接受两个参数:一个必需的 param 和一个可选的 regexp(一个 Java 正则表达式)。
- RemoteAddr=192.168.1.1/24
#RemoteAddr 路由断言工厂接受一个源列表(最小大小 1),这些源是 cidr 符号(IPv4 或 IPv6)字符串,比如 192.168.1.1/24(其中 192.168.1.1 是 IP 地址,24 是子网掩码)。
-
id: weight_high
uri: https://weighthigh.org
predicates:
- Weight=group1, 8
-
id: weight_low
uri: https://weightlow.org
predicates:
- Weight=group1, 2 # 80%的请求,由 https://weighthigh.org 这个 url 去处理
# 20%的请求由 https://weightlow.org 去处理
discovery:
locator:
enabled: true # 开启动态路由,开启通过应用名称找到服务的功能
lowerCaseServiceId: true # 开启服务名称小写
#eureka 的配置
eureka:
instance:
hostname: localhost
instance-id: ${eureka.instance.hostname}:${spring.application.name}
prefer-ip-address: true
client:
fetch-registry: true
service-url:
defaultZone: http://localhost:8761/eureka/
断言总结
Predicate 就是为了实现一组匹配规则,让请求过来找到对应的 Route 进行处理
Filter 过滤器工厂(重点)
概述:
gateway 里面的过滤器和 Servlet 里面的过滤器,功能差不多,路由过滤器可以用于修改进入
Http 请求和返回 Http 响应
自定义全局过滤器
全局过滤器的优点:
初始化时默认挂到所有路由上,我们可以使用它来完成 IP 过滤,限流等功能
demo测试
@Component
public class MyGlobalFilter implements GlobalFilter , Order {
/**
* 这个就是过滤的方法
* 责任链模式
* @param exchange
* @param chain
* @return
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//针对请求的过滤,拿到请求 header url 等参数
ServerHttpRequest request = exchange.getRequest();
URI uri = request.getURI();
System.out.println("路径相关参数:"+uri.toString());
HttpHeaders headers = request.getHeaders();
System.out.println("请求头相关参数:"+headers.toString());
HttpMethod method = request.getMethod();
System.out.println("请求方式:"+method);
//相应相关的数据
ServerHttpResponse response = exchange.getResponse();
//过滤器校验通过
// return chain.filter(exchange);
// 校验不通过时,要响应回数据
response.getHeaders().set("content-type","application/json;utf-8");
//组装业务返回值
HashMap<String, Object> resultMap = new HashMap<>();
resultMap.put("code", HttpStatus.UNAUTHORIZED.value());
resultMap.put("msg","您未授权");
ObjectMapper objectMapper = new ObjectMapper();
byte[] bytes = new byte[0];
try {
bytes = objectMapper.writeValueAsBytes(resultMap);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
DataBuffer wrap = response.bufferFactory().wrap(bytes);
return response.writeWith(Mono.just(wrap));
}
/**
* 责任链中,要指定过滤器调用的顺序,可以用实现 Order接口的方式
* 返回值越小越先执行
* @return
*/
@Override
public int value() {
return 10;
}
@Override
public Class<? extends Annotation> annotationType() {
return null;
}
}
IP 认证拦截实战
@Component
public class IPCheckFilter implements GlobalFilter, Order {
/**
* 网关的并发比较高 不要在网关里直接操作 mysql
* 后台系统这种 用户量不大的 可以去查询
* 并发量大就用 redis这种
*
* 模拟缓存中的数据
*/
private static HashSet<String> BLACK_LIST = new HashSet(Arrays.asList("127.0.0.1", "192.168.59.128"));
/**
* 1、拿到ip
* 2、校验ip是否符合规范
* 3、放行/拦截
*
* @return
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String host = request.getURI().getHost();
if (!BLACK_LIST.contains(host)) {
// 不是黑名单 放行
return chain.filter(exchange);
}
//定义了一个工具方法,返回Mono结果
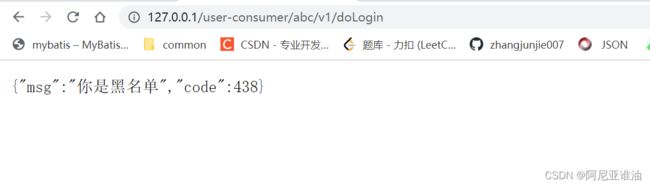
return ResponseDataUtil.getMono(exchange.getResponse(), 438, "你是黑名单");
}
@Override
public int value() {
return 20;
}
@Override
public Class<? extends Annotation> annotationType() {
return null;
}
}
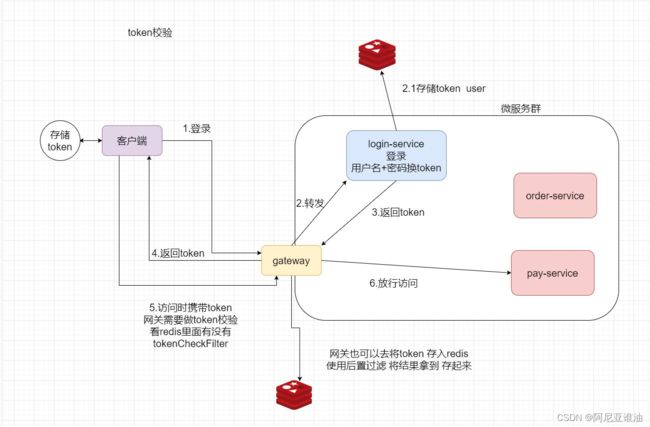
token校验原理
代码:略
限流实战(会问)
什么是限流?
通俗的说,限流就是限制一段时间内,用户访问资源的次数,减轻服务器压力,限流大致分为
两种:
- IP 限流(5s 内同一个 ip 访问超过 3 次,则限制不让访问,过一段时间才可继续访问)
- 请求量限流(只要在一段时间内(窗口期),请求次数达到阀值,就直接拒绝后面来的访问了,
过一段时间才可以继续访问)(粒度可以细化到一个 api(url),一个服务)
本次限流模型
限流模型:漏斗算法 ,令牌桶算法,窗口滑动算法 计数器算法
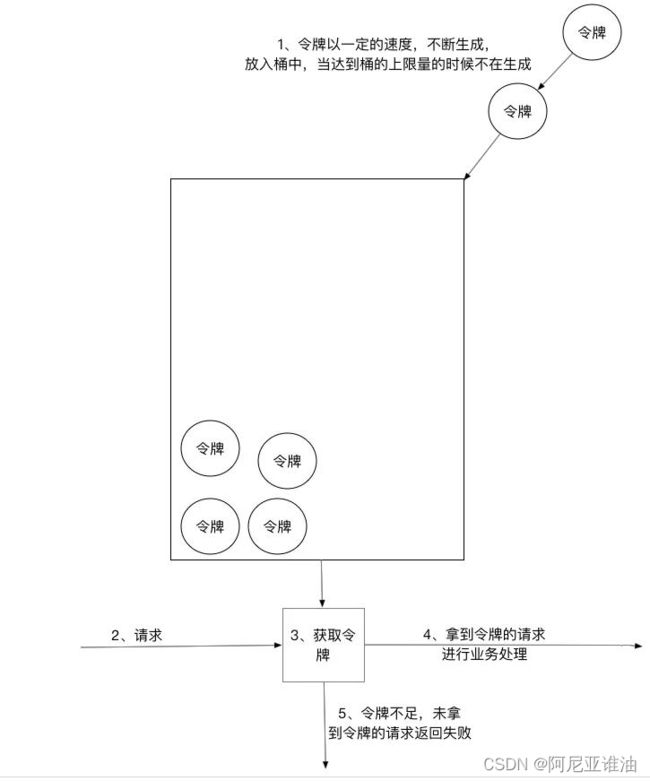
入不敷出
1)、所有的请求在处理之前都需要拿到一个可用的令牌才会被处理;
2)、根据限流大小,设置按照一定的速率往桶里添加令牌
3)、桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝;
4)、请求达到后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务逻辑,处理完业务逻辑之后,将令牌直接删除;
5)、令牌桶有最低限额,当桶中的令牌达到最低限额的时候,请求处理完之后将不会删除令牌,以此保证足够的限流
Gateway 结合 redis 实现请求量限流
Spring Cloud Gateway 已经内置了一个 RequestRateLimiterGatewayFilterFactory,我们可以直接使用。
目前 RequestRateLimiterGatewayFilterFactory 的实现依赖于 Redis,所以我们还要引入
spring-boot-starter-data-redis-reactive。
添加依赖
org.springframework.boot
spring-boot-starter-data-redis-reactive
routes:
- id: user-service
uri: lb://consumer-user-service
predicates:
- Path=/info/**
filters:
- name: RequestRateLimiter
args:
key-resolver: '#{@hostAddrKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 3
配置文件说明
在上面的配置文件,配置了 redis 的信息,并配置了 RequestRateLimiter 的限流过滤器,该过滤器需要配置三个参数:
burstCapacity:令牌桶总容量。
replenishRate:令牌桶每秒填充平均速率。
key-resolver:用于限流的键的解析器的 Bean 对象的名字。它使用 SpEL 表达式根据#{@beanName}从 Spring 容器中获取 Bean 对象。
创建配置类 RequestRateLimiterConfig
@Configuration
public class RequestRateLimiterConfig {
/**
* IP 限流
* 把用户的 IP 作为限流的 Key
*
* @return
*/
@Bean
@Primary
public KeyResolver hostAddrKeyResolver() {
return (exchange) -> Mono.just(exchange.getRequest().getRemoteAddress().getHostName());
}
/**
* 用户 id 限流
* 把用户 ID 作为限流的 key
*
* @return
*/
@Bean
public KeyResolver userKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getQueryParams().getFirst("userId"));
}
/**
* 请求接口限流
* 把请求的路径作为限流 key
*
* @return
*/
@Bean
public KeyResolver apiKeyResolver() {
return exchange -> Mono.just(exchange.getRequest().getPath().value());
}
}
启动快速访问测试
跨域配置
跨域? ajax 同源策略
8080 8081
因为网关是微服务的边缘 所有的请求都要走网关 跨域的配置只需要写在网关即可
@Configuration
public class CorsConfig {
@Bean
public CorsWebFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
config.addAllowedMethod("*");
config.addAllowedOrigin("*");
config.addAllowedHeader("*");
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(new PathPatternParser());
source.registerCorsConfiguration("/**", config);
return new CorsWebFilter(source);
}
}
spring:
cloud:
gateway:
globalcors:
corsConfigurations:
'[/**]':
# 针对哪些路径
allowCredentials: true # 这个是可以携带 cookie
allowedHeaders: '*'
allowedMethods: '*'
allowedOrigins: '*'
总结和面试
- 你们网关用的什么 ? Gateway zuul
- 你们网关里面写什么代码?
跨域,路由(动态路由,负载均衡)ip 黑名单拦截,Token 的校验,对请求进行过滤(请求
参数校验) 对响应做处理(状态码,响应头) 熔断 限流
微服务的网关,可以很好地将具体的服务和浏览器隔离开,只暴露网关的地址给到浏览器在微服务网关中,可以很好的实现校验认证,负载均衡(lb),黑名单拦截,限流等
Gateway 和 zuul 的区别 ZuulFilter
Zuul 也是 web 网关,本质上就是一组过滤器,按照定义的顺序,来执行过滤操作
二者的区别:
- 两者均是 web 网关,处理的是 http 请求
- Gateway 是 springcloud 官方的组件,zuul 则是 netflix 的产品 springcloud,netflix ,alibaba(nacos,sentinel,dubbo zk,seata,rocketmq)
- gateway 在 spring 的支持下,内部实现了限流、负载均衡等,扩展性也更强,但同时也限制了仅适合于 Spring Cloud 套件。而 zuul 则可以扩展至其他微服务框架中,其内部没有实现限流、负载均衡等
- Gateway(Netty NIO)很好的支持异步(spring5.x ,webFlux 响应式编程默认是异步的),而 zuul1.0 仅支持同步
BIO zuul2.0 以后也支持异步了
Nginx 在微服务中的地位
最后简单聊一下 nginx,在过去几年微服务架构还没有流行的日子里,nginx 已经得到了广大开发者的认可,其性能高、扩展性强、可以灵活利用 lua 脚本构建插件的特点让人没有抵抗力。(nginx 的请求转发 最大并发是多个次,每秒 5w-10w 左右)3w 左右
有一个能满足我所有需求还很方便我扩展的东西,还免费,凭啥不用??
但是,如今很多微服务架构的项目中不会选择 nginx,我认为原因有以下几点:
- 微服务框架一般来说是配套的,集成起来更容易
- 如今微服务架构中,仅有很少的公司会面对无法解决的性能瓶颈,而他们也不会因此使用
nginx,而是选择开发一套适合自己的微服务框架(很多公司会对现有框架进行修改) - spring boot 对于一些模板引擎如 FreeMarker、themleaf 的支持是非常好的,很多应用还没
有达到动、静态文件分离的地步,对 nginx 的需求程度并不大。
动静分离: css js 可以放在 nginx
单体项目需要部署 对 nginx 的使用的需求还是比较大的
斗鱼 不是使用后端技术 如何实现大规模缓存?
使用 Nginx 做大规模的静态资源缓存
不是为了用技术而用技术,按照实际业务来, 目的是盈利
无论如何,nginx 作为一个好用的组件,最终使不使用它都是由业务来驱动的,只要它能为我们方便的解决问题,那用它又有何不可呢?
关于限流,面试不会直接问,而是间接来问 问 不卖超
比如:如果在抢购过程中,用户量请求非常大,怎么确保商品不会卖超
Redis 单线程 (IO 为什么快,因为我们现在的处理器是多核心数的,redis 底层使用的是IO 的多路复用)
一般人只会在意商品卖超,而忘记了限流的重要性
Mq(限流 削峰,异步,解耦合)
Spring Cloud Alibaba
项目简介:
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
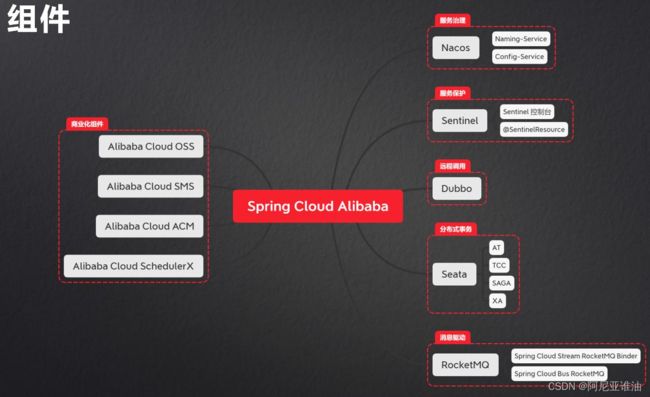
组件
项目地址
https://github.com/alibaba/spring-cloud-alibaba
版本说明
官方地址
Nacos 注册中心
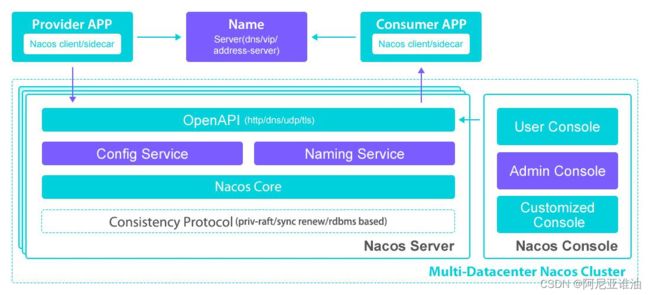
1.Nacos 简介
官网: https://nacos.io/zh-cn/
Nacos 致力于发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
2.Nacos 的核心概念
2.1 服务 (Service)
服务是指一个或一组软件功能(例如特定信息的检索或一组操作的执行),其目的是不同的客户端可以为不同的目的重用(例如通过跨进程的网络调用)。Nacos 支持主流的服务生态,如
Kubernetes Service 、 gRPC|Dubbo RPC Service 或者Spring Cloud RESTful Service.
2.2 服务注册中心 (Service Registry)
服务注册中心,它是服务实例及元数据的数据库。服务实例在启动时注册到服务注册表,并在关闭时注销。服务和路由器的客户端查询服务注册表以查找服务的可用实例。服务注册中心可能会调用服务实例的健康检查 API 来验证它是否能够处理请求。
2.3 服务元数据 (Service Metadata)
服务元数据是指包括服务端点(endpoints)、服务标签、服务版本号、服务实例权重、路由规则、安全策略等描述服务的数据
2.4 服务提供方 (Service Provider)
是指提供可复用和可调用服务的应用方
2.5 服务消费方 (Service Consumer)
是指会发起对某个服务调用的应用方
2.6 配置 (Configuration)—配置文件中心
在系统开发过程中通常会将一些需要变更的参数、变量等从代码中分离出来独立管理,以独立的配置文件的形式存在。目的是让静态的系统工件或者交付物(如 WAR,JAR 包等)更好地和实际的物理运行环境进行适配。配置管理一般包含在系统部署的过程中,由系统管理员或者运维人员完成这个步骤。配置变更是调整系统运行时的行为的有效手段之一。
2.7 配置管理 (Configuration Management)
在数据中心中,系统中所有配置的编辑、存储、分发、变更管理、历史版本管理、变更审计等所有与配置相关的活动统称为配置管理。
2.8 名字服务 (Naming Service)
提供分布式系统中所有对象(Object)、实体(Entity)的“名字”到关联的元数据之间的映射管理服务,例如 ServiceName -> Endpoints Info, Distributed Lock Name -> LockOwner/Status Info, DNS Domain Name -> IP List, 服务发现和 DNS 就是名字服务的2 大场景。
2.9 配置服务 (Configuration Service)
在服务或者应用运行过程中,提供动态配置或者元数据以及配置管理的服务提供者。
3.NacosServer 的安装和启动
NacosServer 相当于 EurekaServer,只不过 eurekaServer 使我们自己搭建的一个项目,而 NacosServer 别人已经提供好了
3.1 NacosServer 的下载
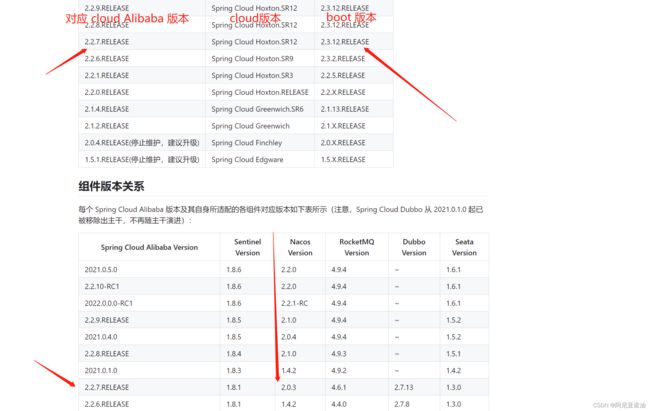
我们要对应版本,目前 alibaba 稳定版是 2.2.7.RELEASE
根据分支选择对应的版本
地址: https://github.com/alibaba/nacos/releases/tag/2.0.3
所以下载2.0.3 版本就行(迅雷下载比较快)
3.2 解压以及目录说明

- bin:可执行文件夹目录,包含:启动、停止命令等等
- conf:配置文件目录
- target:存放 naocs-server.jar
- LICENSE:授权信息,Nacos 使用
- Apache License Version 2.0 授权
- NOTICE:公告信息
3.3 修改配置文件【重点】
修改conf文件夹下 application.properties 文件内容
Nacos 默认使用嵌入式数据库实现数据的存储,并不方便观察数据存储的基本情况,这里面 我们修改为使用 Mysql 数据库做数据的存储,方便我们观察数据的结构。
在配置文件末尾添加如下配置:
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://82.157.233.2:3306/nacos?characterEncoding=utf8&connectTimeout10000&socketTimeout=30000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user=root
db.password=123456
3.4 Mysql 表的导入
在 config 目录下找到对应的 sql 脚本,提示:Nacos 建议使用 5.7 的 Mysql 数据库,版本较低或者较高可能存储兼容性问题
3.5 NacosServer 的启动
可以直接 startup.cmd -m standalone 启动单击版本
上面工作都完成后,现在我们来启动一个单机版的 Nacos 服务器。
默认是集群方式启动,会报错
进入到 /bin 目录里面:
使用 nodepad++打开 startup.cmd 修改默认参数
将 set MODE=”cluster”修改为 standalone : 默认是集群的方式启动,修改为单机
双击 startup.cmd 文件,完成 nacosServer 的启动
http://localhost:8848/nacos ,即可访问启动 Nacos 实例
Nacos 默认用户名和密码都是 nacos。
如果想修改密码,可以直接修改数据库的 user 表,密码可以使用 BcryptPasswordEncoder 加密
输入正确的用户名和密码提交后,出现 Nacos 的控制台界面
至此,Nacos Server 已经安装成功
4.使用 Nacos 做注册中心
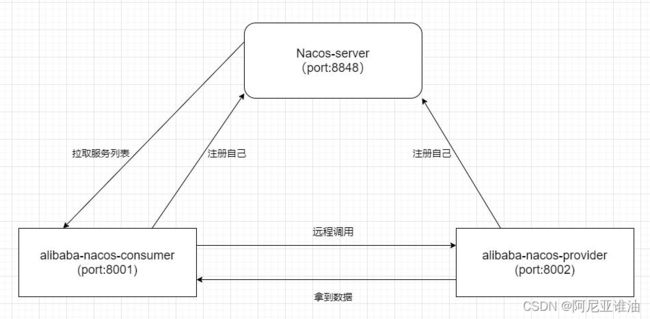
4.1 搭建两个 nacos 的客户端
我们搭建 alibaba-nacos-consumer 和 alibaba-nacos-provider,就是一个消费者一个提供者
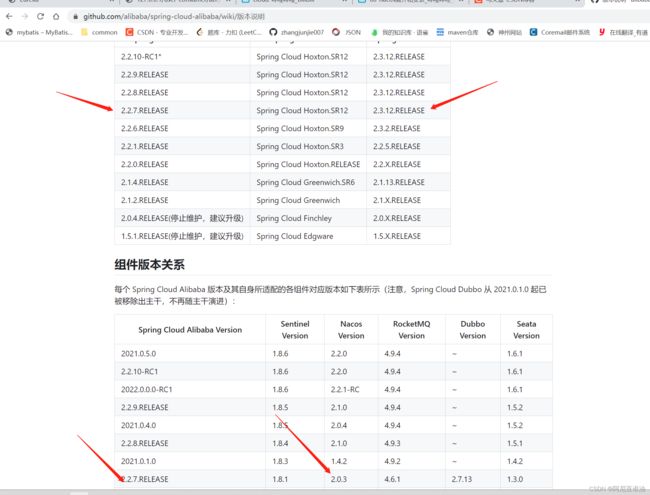
4.2 版本依赖【重点-再贴图一次】
4.3 创建父项目,做依赖管理
"1.0" encoding="UTF-8"?>
"http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0</modelVersion>
pom</packaging>
org.example</groupId>
nacos</artifactId>
1.0-SNAPSHOT</version>
org.springframework.boot</groupId>
spring-boot-starter-parent</artifactId>
2.3.12.RELEASE</version>
.compiler.source>8</maven.compiler.source>
.compiler.target>8</maven.compiler.target>
.version>1.8</java.version>
.version>Hoxton.SR12</spring-cloud.version>
.version>2.2.7.RELEASE</spring-cloud-alibaba.version>
</properties>
org.springframework.boot</groupId>
spring-boot-starter-web</artifactId>
</dependency>
com.alibaba.cloud</groupId>
spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
</dependencies>
org.springframework.cloud</groupId>
spring-cloud-dependencies</artifactId>
${spring-cloud.version}</version>
<type>pom</type>
import</scope>
</dependency>
com.alibaba.cloud</groupId>
spring-cloud-alibaba-dependencies</artifactId>
${spring-cloud-alibaba.version}</version>
<type>pom</type>
import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
子项目根据需要引入相应依赖就好
4.4 创建生产者 alibaba-nacos-provider
配置文件
server:
port: 8080
spring:
application:
name: alibaba-nacos-provider
cloud:
nacos: # 客户端注册的地址 如果不指定命名空间 会默认注册到 public里面去,如果没有指定分组 会注册到 DEFAULT_GROUP
username: nacos
password: nacos
server-addr: localhost:8848
# discovery: 不设置 走默认逻辑
# namespace: # 命名空间 可以做项目隔离
# group: 在命名空间下的组别,可以用来做细粒度的隔离
启动类
@SpringBootApplication
@EnableDiscoveryClient //开启服务发现客户端 也就是 nacosServer 的客户端
public class AlibabaNacosProviderApplication {
public static void main(String[] args) {
SpringApplication.run(AlibabaNacosProviderApplication.class, args);
}
}
启动服务
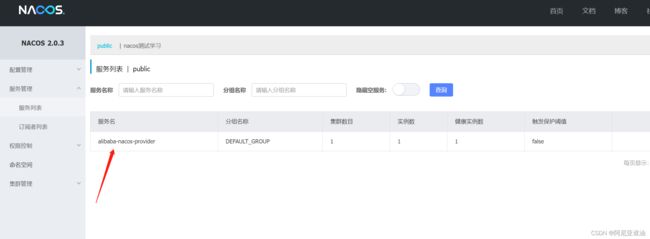
服务名:默认取的是 spring.application.name 的名称
分组名称:配置文件不配置的话默认是DEFAULT_GROUP
4.5 创建消费者
配置文件
server:
port: 8081
spring:
application:
name: alibaba-nacos-consumer
cloud:
nacos: # 客户端注册的地址
username: nacos
password: nacos
server-addr: localhost:8848
discovery:
group: jj
namespace: nacos-study # 要提前在 nacos 网页上创建好 然后把空间的id拿过来
service: nacos-consumer-service # 默认取得是 ${spring.application.name}
注意:
当要指定nacos中的命名空间时,这个空间必须要提前创建好,要不无法注册到该空间下;
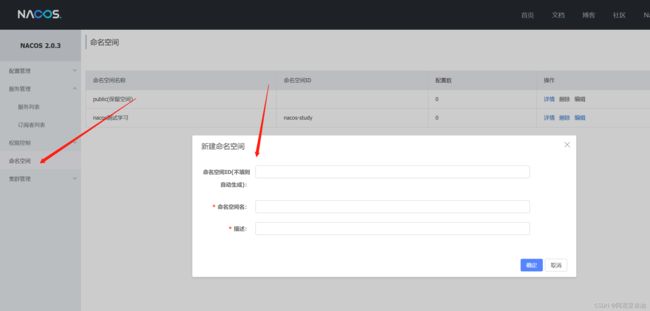
namespace:就写提前生成好的命名空间的id,可以自动生成,也可以手动设置。
group: 可以开发的时候自己指定
启动类同上
启动服务
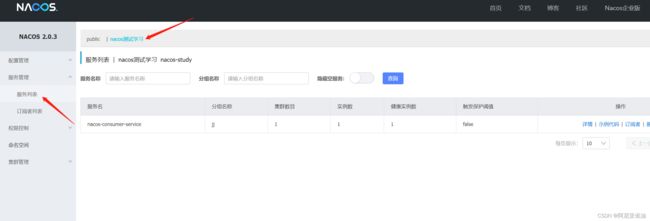
启动成功
4.6 测试命名空间的隔离性
用 alibaba-nacos-consumer 来进行测试
再启动两个服务:
同一个命名空间不同分组;
同一个命名空间,相同分组;
加上原来 alibaba-nacos-provider : 是不同命名空间,不同分组。
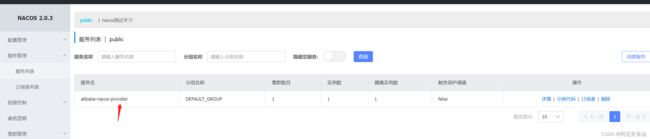
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xqUc4uY2-1682254688205)(C:\Users\17310\AppData\Roaming\Typora\typora-user-images\image-20230423142055310.png)]
如上图:启动以后和consumer在一个空间下的有两个,其中一个在同一个分组,两个不在该空间下;
测试是消费者服务能否拿到其他服务实例
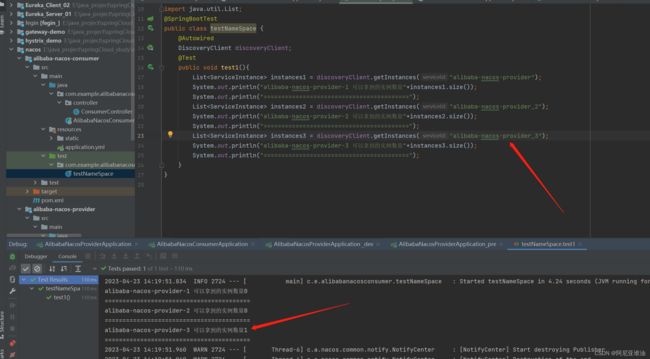
只有同一个空间同一个分组下才能拿到
eureka 相比nacos有一个弊端,就是如果多个项目用的同一个eureka注册中心,如果多个项目里有名称一样的服务模块,那么调用的时候就很可能会出现问题。
如果一个项目用一个注册中心的话,又会很浪费资源,这点nacos比较有优势
5. 集成 openfeign
做远程调用和负载均衡
5.1 启动多台 alibaba-nacos-provider
我们可以再建一个项目,来达到多台 provider 的效果,
也可以通过修改配置文件的方式启动多台,只有端口改变,其他都不改变
把proivder 改为和消费者同一个命名空间,同一个组,然后指定环境启动:
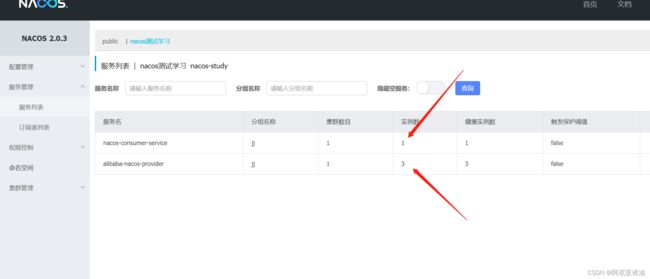
启动以后,如上图,和消费者在一个空间一个组里,有三个实例
5.2 提供者服务
@RestController
public class ProviderController {
@GetMapping("/info")
public String testResult(){
System.out.println("来访问了");
return "ok";
}
}
除了端口不一样,其他都一样,构建集群
server:
port: 8082
spring:
application:
name: alibaba-nacos-provider
cloud:
nacos: # 客户端注册的地址 如果不指定命名空间 会默认注册到 public里面去,如果没有指定分组 会注册到 DEFAULT_GROUP
username: nacos
password: nacos
server-addr: localhost:8848
discovery:
namespace: nacos-study
group: jj
5.3 消费者服务
引入fegin的依赖
org.springframework.cloud</groupId>
spring-cloud-starter-openfeign</artifactId>
</dependency>
版本在父项目中已经定义好springcloud 的版本
编写 feginclient
@FeignClient(value = "alibaba-nacos-provider")
public interface CousumeFeginClinet {
@GetMapping("/info")
public String testResult();
}
编写消费者
@RestController
public class ConsumerController {
@Autowired
CousumeFeginClinet cousumeFeginClinet;
@RequestMapping("/test")
public String getInfo(){
return cousumeFeginClinet.testResult();
}
修改启动类
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
public class AlibabaNacosConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(AlibabaNacosConsumerApplication.class, args);
}
测试接口
访问: http://localhost:8081/test
服务会负载到每台提供者
6.Nacos Discovery 对外暴露 Endpoint
Nacos Discovery 内 部 提 供 了 一 个 Endpoint, 对 应 的 endpoint id 为 nacos-discovery。我们通过该 Endpoint,能获取到:
- 当前服务有哪些服务订阅者 ;
- 当前应用 Nacos 的基础配置信息 ;
6.1 给任意项目添加依赖
org.springframework.boot</groupId>
spring-boot-starter-actuator</artifactId>
</dependency>
6.2 修改配置文件
Endpoint 本身对外界隐藏显示,我们需要在配置里面开启对 Endponit 的显示支持。修改 application.yml 配置文件,在里面添加如下的配置:
management:
endpoints:
web:
exposure:
include: '*'
exposure.include:对外界保留那些 Endpoint,若是所有则使用 ;*
6.3 启动项目访问查看效果
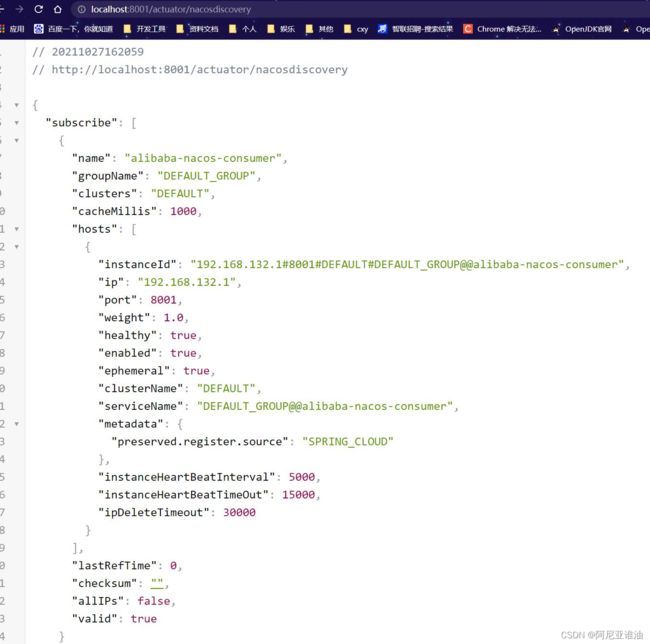
7.Nacos Discovery Starter 更多的配置项
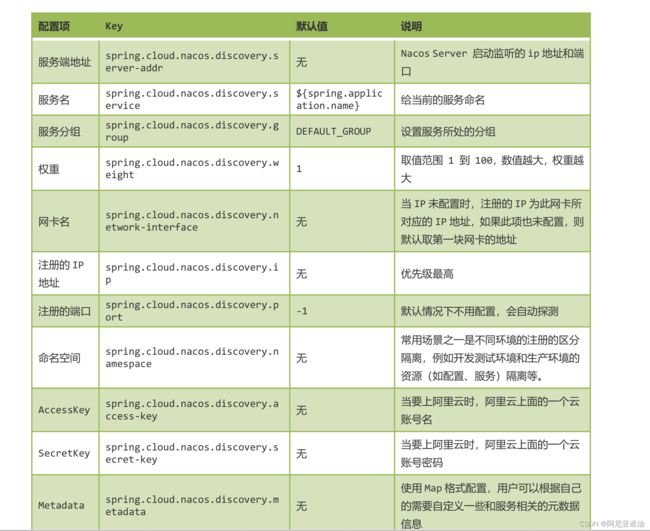
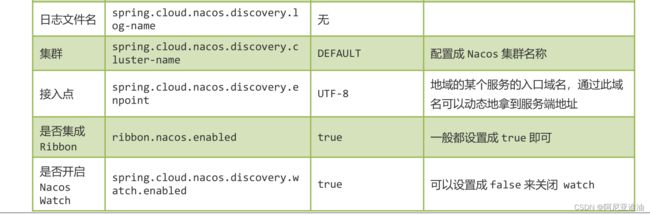
Nacos 配置文件中心
使用 Spring Cloud Alibaba Nacos Config,可基于 Spring Cloud 的编程模型快速接入 Nacos 配置管理功能。 Spring Cloud Alibaba Nacos 注册中心记录了 Nacos 作为注册中心的使用方式,
这节 继 续 记 录 下 Nacos 作 为 配 置 中 心 的使 用方 式。 本节使 用的
- Spring Cloud 版 本 为Hoxton.SR12 ,
- Spring Cloud Alibaba 版 本 为 2.2.7.RELEASE,
- Spring Boot 版 本 为 2.3.12.RELEASE。
2.创建项目 config-client-a
2.1 创建项目选择依赖
com.alibaba.cloud</groupId>
spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
2.2 在 Nacos Server 里面添加一个配置文件
找到配置列表 ,点击添加按钮:
注意先选中具体的命名空间
填写具体信息:
也可以用 yml形式:
hero:
name: jj
age: 11
address: 北京
返回查看配置文件发布成功了

在该命名空间下,有这样的配置文件了
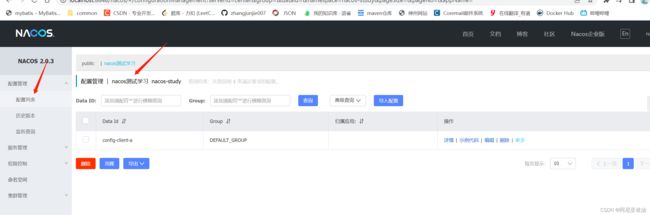
2.3 查看 数据库中的信息
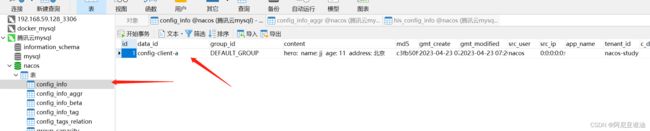
我们添加的配置文件就是插入到数据库里面的一条数据
2.4 修改配置文件
config-client-a 项目中添加一个配置文件 bootstrap.yml
注意:不是 application.yml ,bootstrap.yml 比 application 有更高的优先级。
server:
port: 8080
spring:
application:
name: config-client
cloud:
nacos:
config:
server-addr: localhost:8848
username: nacos
password: nacos
file-extension: yml
prefix: config-client-a
namespace: nacos-study
# group: 不写走默认
2.5 增加实体类
config-client-a 中添加一个实体类 Hero
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
@RefreshScope // 刷新的域,当配置文件修改后可以动态刷新
public class Hero {
@Value("${hero.name}")
private String name ;
@Value("${hero.age}")
private int age ;
@Value("${hero.address}")
private String addreaa;
}
@RefreshScope : 配置文件更新以后,会实时更新类中的取值
2.6 增加 controller 测试
config-client-a 中添加一个测试类 Controller
@RestController
public class HeroController {
/**
* 注入 hero
*/
@Autowired
private Hero hero;
/**
* 获取信息的接口
*
* @return
*/
@GetMapping("heroInfo")
public String heroInfo() {
return hero.getName() + ":" + hero.getAge() + ":" + hero.getAddress();
}
}
2.7 启动测试
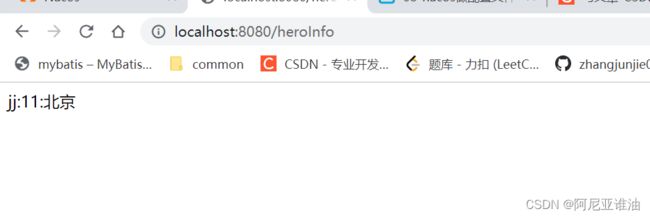
2.8 测试配置文件的动态刷新
配置文件更新
@RefreshScope // 刷新的域,当配置文件修改后可以动态刷新
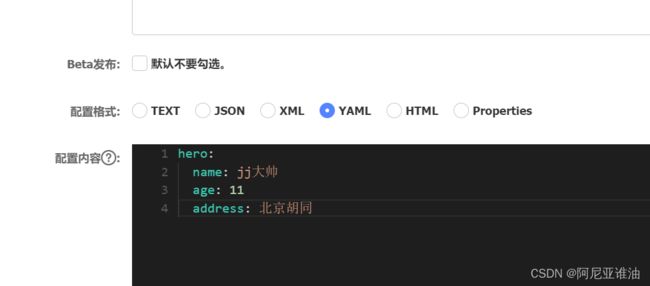
访问结果即时更新
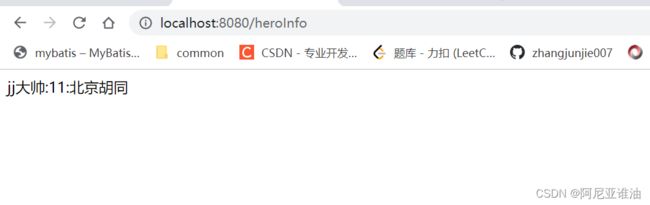
2.9 配置文件的历史版本查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jUWg17hz-1682254688206)(C:\Users\17310\AppData\Roaming\Typora\typora-user-images\image-20230423171345745.png)]
点击历史版本查看,注意历史版本只保留 30 天
可以直接回滚
3.配置文件的读取方式【重点】
nacos 配置中心通过 namespace、dataId 和 group 来唯一确定一条配置。
- Namespace:即命名空间。默认的命名空间为 public,我们可以在 Nacos 控制台中新建命名空间;
- dataId:即配置文件名称
- Group:即配置分组,默认为 DEFAULT_GROUP,可以通过
spring.cloud.nacos.config.group配置
其中:dataId 是最关键的配置字段:格式如下:
${prefix} - ${spring.profiles.active} . ${file-extension}
说明:
prefix默 认 为spring.application.name的值, 也可以通过配置项spring.cloud.nacos.config.prefix来配置;spring.profiles.active即 为 当 前 环 境 对 应 的profile。 注 意 , 当spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension};file-extension为 配 置 内 容 的 数 据 格 式 , 可 以 通 过 配 置 项spring.cloud.nacos.config.file-extension来配置。
这就是上面我们为什么能获得到配置的原因了。
注意:在写 dataId 的时候一定要添加文件类型后缀
Eg: nacos-config-dev.yml
4.配置文件划分
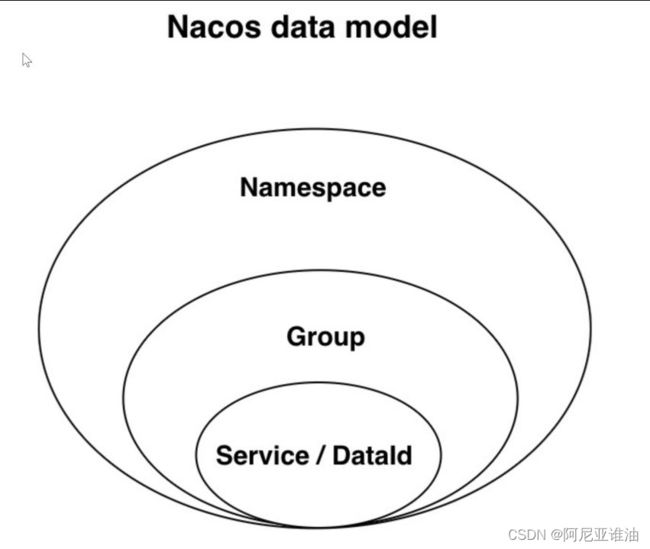
Nacos 配置中心的 namespace、dataId 和 group 可以方便灵活地划分配置。
比如,我们现在有一个项目需要开发,项目名称为 bjpowernode,项目开发人员分为两个组:GROUP_A 和GROUP_B,项目分为三个环境:开发环境 dev、测试环境 test 和生产环境 prod。
powernode->GRUOR_A->dev
4.1 在 Nacos 中新建一个 powernode 的命名空间
点击新添加一个命名空间
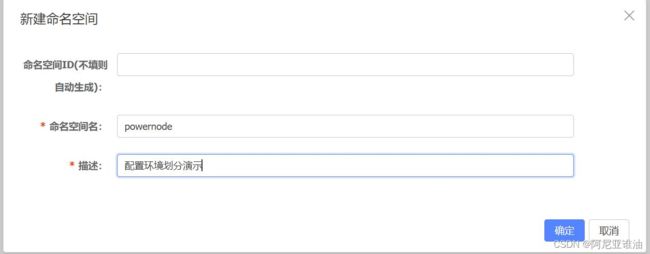
填写信息后确认
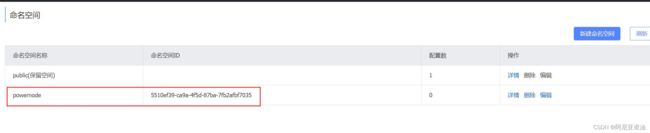
他给我们生成了一个 id,要记住这个 id:5510ef39-ca9a-4f5d-87ba-7fb2afbf7035
4.2 在 Nacos 中新建一个配置文件 config-client-dev.yml
注意先选择 命名空间,然后在选择添加配置文件
点击完成
4.3 修改 config-client-a 项目的配置文件
server:
port: 8080
spring:
application:
name: config-client-a
cloud:
nacos:
config:
server-addr: localhost:8848
namespace: 5510ef39-ca9a-4f5d-87ba-7fb2afbf7035 # 命名空间 注意使用 id
group: GROUP_A # 组别
prefix: config-client # 配置文件前缀,如果不写 默认使用${spring.application.name}的值
file-extension: yml # 后缀 文件格式
profiles:
active: dev # spring 的环境配置
4.4 重启 nacos-config-client 项目测试
配置文件的信息已经获取成功
5.获取多配置文件
除了通过上面的方式指定一个唯一配置外,我们还可以同时获取多个配置文件的内容。提供这个功能 可以再次封装和抽象配置文件管理
5.1 在 Nacos 中新建两个配置文件
5.2 修改 config-client-a 项目的配置文件
server:
port: 8082
spring:
application:
name: nacos-config-test
cloud:
nacos:
config:
server-addr: localhost:8848
username: nacos
password: nacos
namespace: nacos-study # 目前读取多配置文件的方式只支持在同一个命名空间下
file-extension: yaml
extension-configs: # 可以读多个配置文件 需要在同一个命名空间下面 可以是不同的组
- dataId: user-center-dev.yml
group: A_GROUP
refresh: true
- dataId: member-center-dev.yml
group: B_GROUP
refresh: false # 不去动态刷新配置文件
上面配置不行。一直没找到原因。。。。。
-
spring.cloud.nacos.config.extension-configs[n].dataId , 指 定 多 个 配 置 的 dataId,必须包含文件格式,支持 properties、yaml 或 yml;
-
spring.cloud.nacos.config.extension-configs[n].group,指定分组;
-
spring.cloud.nacos.config.extension-configs[n].refresh,是否支持刷新。
上面的配置中,我们分别从 DEFAULT_GROUP 中获取了 config-a.yml 和 config-b.yml 配置
内容,并且 config-a.yml 支持刷新,config-b.yml 不支持刷新。
注意:
没有 namespace 的配置,言外之意就是 Nacos 目前还不支持多个配置指定不同的命名空间。
.7 启动测试
2.8 测试配置文件的动态刷新
配置文件更新
@RefreshScope // 刷新的域,当配置文件修改后可以动态刷新
访问结果即时更新
2.9 配置文件的历史版本查询
[外链图片转存中…(img-jUWg17hz-1682254688206)]
点击历史版本查看,注意历史版本只保留 30 天
可以直接回滚
3.配置文件的读取方式【重点】
nacos 配置中心通过 namespace、dataId 和 group 来唯一确定一条配置。
- Namespace:即命名空间。默认的命名空间为 public,我们可以在 Nacos 控制台中新建命名空间;
- dataId:即配置文件名称
- Group:即配置分组,默认为 DEFAULT_GROUP,可以通过
spring.cloud.nacos.config.group配置
其中:dataId 是最关键的配置字段:格式如下:
${prefix} - ${spring.profiles.active} . ${file-extension}
说明:
prefix默 认 为spring.application.name的值, 也可以通过配置项spring.cloud.nacos.config.prefix来配置;spring.profiles.active即 为 当 前 环 境 对 应 的profile。 注 意 , 当spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension};file-extension为 配 置 内 容 的 数 据 格 式 , 可 以 通 过 配 置 项spring.cloud.nacos.config.file-extension来配置。
这就是上面我们为什么能获得到配置的原因了。
注意:在写 dataId 的时候一定要添加文件类型后缀
Eg: nacos-config-dev.yml
4.配置文件划分
Nacos 配置中心的 namespace、dataId 和 group 可以方便灵活地划分配置。
比如,我们现在有一个项目需要开发,项目名称为 bjpowernode,项目开发人员分为两个组:GROUP_A 和GROUP_B,项目分为三个环境:开发环境 dev、测试环境 test 和生产环境 prod。
powernode->GRUOR_A->dev
4.1 在 Nacos 中新建一个 powernode 的命名空间
点击新添加一个命名空间
填写信息后确认
他给我们生成了一个 id,要记住这个 id:5510ef39-ca9a-4f5d-87ba-7fb2afbf7035
4.2 在 Nacos 中新建一个配置文件 config-client-dev.yml
注意先选择 命名空间,然后在选择添加配置文件
点击完成
4.3 修改 config-client-a 项目的配置文件
server:
port: 8080
spring:
application:
name: config-client-a
cloud:
nacos:
config:
server-addr: localhost:8848
namespace: 5510ef39-ca9a-4f5d-87ba-7fb2afbf7035 # 命名空间 注意使用 id
group: GROUP_A # 组别
prefix: config-client # 配置文件前缀,如果不写 默认使用${spring.application.name}的值
file-extension: yml # 后缀 文件格式
profiles:
active: dev # spring 的环境配置
4.4 重启 nacos-config-client 项目测试
配置文件的信息已经获取成功
5.获取多配置文件
除了通过上面的方式指定一个唯一配置外,我们还可以同时获取多个配置文件的内容。提供这个功能 可以再次封装和抽象配置文件管理
5.1 在 Nacos 中新建两个配置文件
5.2 修改 config-client-a 项目的配置文件
server:
port: 8082
spring:
application:
name: nacos-config-test
cloud:
nacos:
config:
server-addr: localhost:8848
username: nacos
password: nacos
namespace: nacos-study # 目前读取多配置文件的方式只支持在同一个命名空间下
file-extension: yaml
extension-configs: # 可以读多个配置文件 需要在同一个命名空间下面 可以是不同的组
- dataId: user-center-dev.yml
group: A_GROUP
refresh: true
- dataId: member-center-dev.yml
group: B_GROUP
refresh: false # 不去动态刷新配置文件
上面配置不行。一直没找到原因。。。。。
-
spring.cloud.nacos.config.extension-configs[n].dataId , 指 定 多 个 配 置 的 dataId,必须包含文件格式,支持 properties、yaml 或 yml;
-
spring.cloud.nacos.config.extension-configs[n].group,指定分组;
-
spring.cloud.nacos.config.extension-configs[n].refresh,是否支持刷新。
上面的配置中,我们分别从 DEFAULT_GROUP 中获取了 config-a.yml 和 config-b.yml 配置
内容,并且 config-a.yml 支持刷新,config-b.yml 不支持刷新。
注意:
没有 namespace 的配置,言外之意就是 Nacos 目前还不支持多个配置指定不同的命名空间。