深入理解 Flink(一)Flink 架构设计原理
大数据分布式计算引擎设计实现剖析
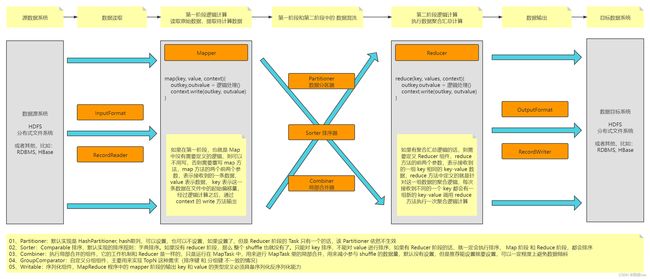
MapReduce
MapReduce 执行引擎解析

MapReduce 的组件设计实现图
Spark
执行引擎解析

Spark 相比于 RM 的真正优势的地方在哪里:(Simple、Fast、Scalable、Unified)
- DAG 引擎
- 中间计算结果可以进行内存持久化
- 基于内存计算(不完全对,确切地说是把数据都加载(从内存中间件中读取)到内存中,然后来执行计算)
- 生态多样,算子丰富,API 应用库丰富,支持的资源调度也丰富
Spark 执行引擎组件图

Flink 流式计算引擎官网解读
简介
Flink 官网定义: Stateful Computations over Data Streams(https://flink.apache.org/)

Flink 官网导航
Flink 各种特性介绍:https://flink.apache.org/
What is Apache Flink?:https://flink.apache.org/flink-architecture.html
Flink 应用场景:https://flink.apache.org/usecases.html
Flink 应用企业:https://flink.apache.org/poweredby.html
Flink 版本升级迭代:https://flink.apache.org/downloads.html
Flink Quick Start:https://nightlies.apache.org/flink/flink-docs-release-1.14//docs/try-flink/local_installation/
Flink 架构:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
Flink 核心概念:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/glossary/
Flink 流式应用程序开发相关:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/
Flink Checkpoint:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/state/checkpoints/
Flink State 和 StateBackend:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/state/state_backends/
Flink 部署:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/overview/
要点01:Flink 处理无界数据流:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#stream-processing
要点02:Flink 关于并行数据流的处理方案:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#parallel-dataflows
要点03:Flink 的有状态计算和状态管理:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#stateful-stream-processing
要点04:Flink Operator 和 Task:https://nightlies.apache.org/flink/flink-docs-release-1.14/fig/levels_of_abstraction.svg
要点05:Flink 资源管理 和 Slot:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/#task-slots-and-resources
要点06:Flink 应用程序运行模式:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/#flink-application-execution
有界数据流和无界数据流的区别
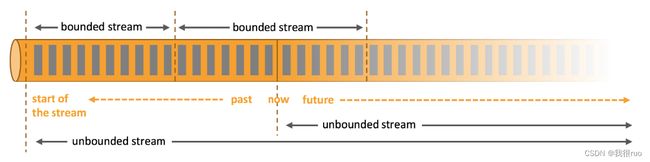
名词解释
离线和实时指的是:数据处理的延迟;
批量和流式指的是:数据处理的方式。
批处理的特点是有界、持久、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
实时计算结果一般是给机器自动化处理,离线计算结果一般用于人的决策。
Flink 架构设计实现和应用模块分工
Flink 整体架构设计实现请参考官网:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
Flink API 设计
请参考官网: https://nightlies.apache.org/flink/flink-docs-release-1.14/fig/levels_of_abstraction.svg
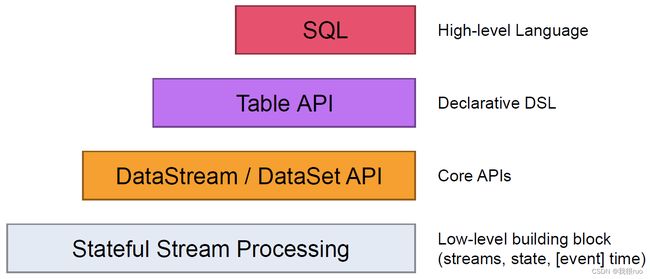
Flink 整体架构体系:API 和 Libaries 体系
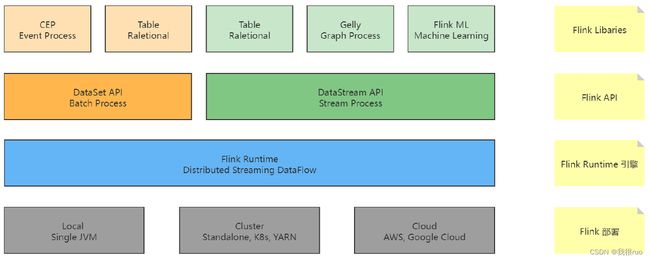
Flink 编程入门到模式总结

Flink 的程序和数据流结构

编程套路总结
1、获得一个执行环境:(Execution Environment)
2、加载/创建初始数据:(Source)
3、指定转换这些数据:(Transformation)
4、指定放置计算结果的位置:(Sink)
5、触发程序执行:(Action)
Flink 核心概念和并行度
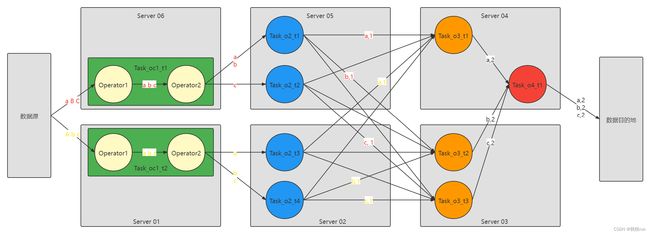
- 图中的 o: Operator, oc 表示 OperatorChain, t 表示 Task。
- 图中的 圆圈 就是一个 Task,绿色的是 Task,只不过是包含两个 Operator, 箭头是数据流, Task 是预先启动不转移位置的,数据流中的数据是流动的。
- OperatorChain 可以理解成类似于 Spark 中的 Stage。
- OperatorChain 包含了多个 Operator,基于并行度并行运行成多个 Task。
- Stage 包含了多个 算子,其实包含了多个 RDD, Stage 中的 Task 数量取决于 这个 Stage 的 最后一个 RDD 的分区数量。
Flink Runtime 四层 Graph 详解
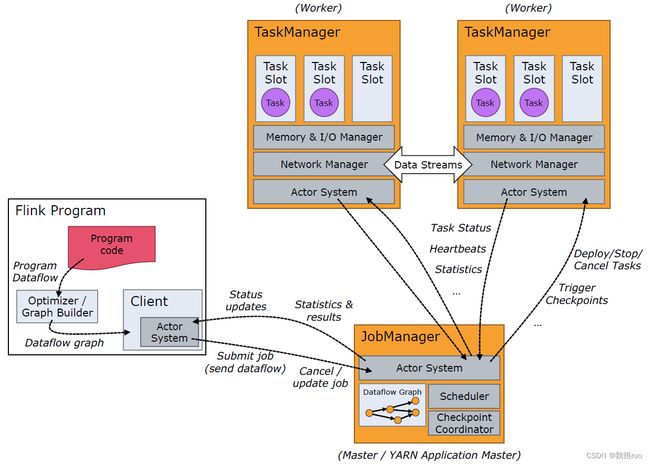
关于上图中的一些概念的解释:
- DataFlow Graph 是一个逻辑概念,表示这个应用程序的一个执行图。事实上在客户端的时候,会生成两个图:StreamGraph + JobGraph
- StreamGraph 中两种非常重要的概念: StreamNode(Operator 算子) + StreamEdge
- JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration); pipeline = StreamGraph
- Client 就是一个 Http 方式的 Restful Client ,负责提交 JobGraph 到 JobManager
- Jobmanager 接收到 JobGraph 之后,会做一件非常重要的事情:启动一个 JobMaster , 这个 JobMaster 就负责这个 Job 的执行。JobMaster 的内部,维护了一个 JobGraph ,在构造 JobMaster 的时候,同时也会吧 JobGraph 构造成 ExecutionGraph。
- ExecutionGraph = ExecutionVertex (里面有一个抽象就代表了一个 Task 的一切信息:Execution, 一个 Execution 会启动一个 Task)
- JobMaster 接下会会向 ResourceManager( 不是 YARN 里面的) JobManager 里面的管理资源的组件 申请 Slot 资源,部署 Task 启动执行。
- 当所有的 Task 都部署到 TaskManager 里面去了,都启动好了,并且上下游 Task 之间都建立了链接,则最终形成了一个 物理执行图。
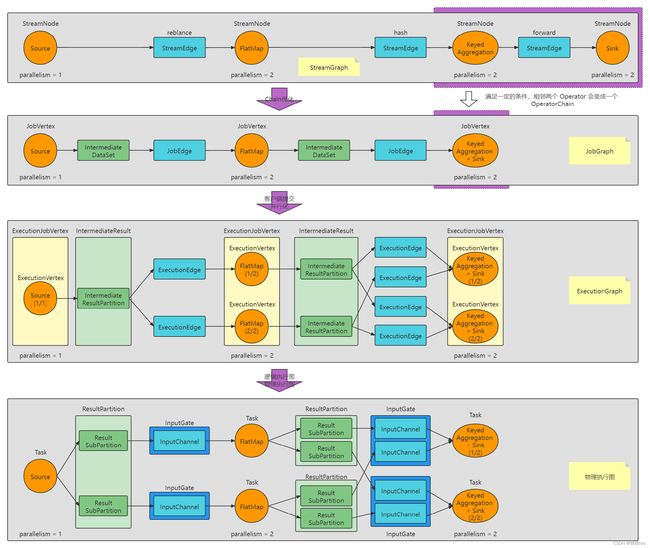
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。简单说就是进行算子拼接。
JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化反序列化传输消耗。简单说就是把能优化的算子拼接在一起。
ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是JobGraph 的并行化版本,是调度层最核心的数据结构,用来执行调度。简单说就是 JobGraph 的并行化版本
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的图,并不是一个具体的数据结构。简单说就是最终运行状态图。
注意:最后一个物理执行图并非 Flink 的数据结构,而是程序开始执行后,各个 Task 分布在不同的节点上,所形成的物理上的关系表示。

Flink 内存模型全详解
Flink Application 运行流程回顾
Flink Task 和 TaskSlot 和 TaskManager 之间的关系:
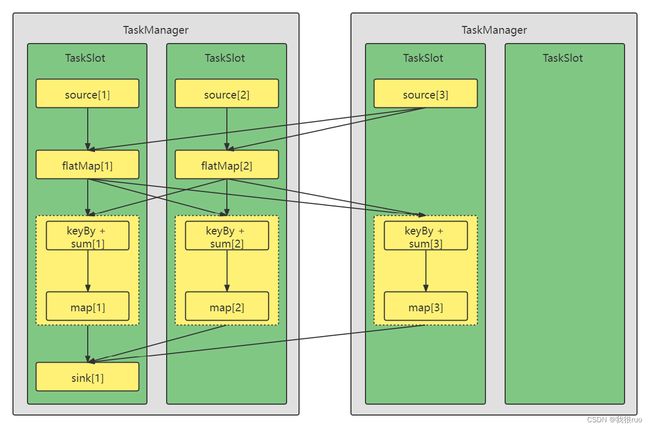
Flink TaskManager 和 TaskManager 之间的数据传输关系:
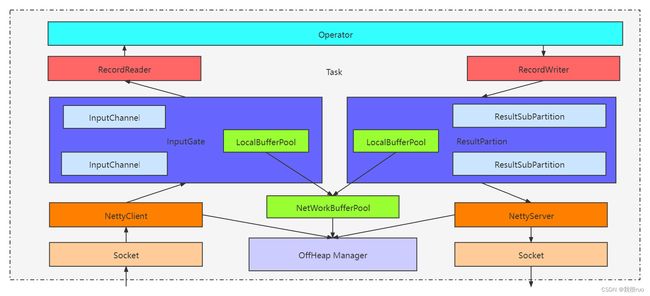
Flink 内存管理
JVM 管理内存的缺陷,其实上是一个共性问题,Spark, HBase 等等,都会涉及到内存模型。
- Java 对象存储密度低:一个只包含 boolean 属性的对象占用 16 个字节内存:对象头占了 8 个, boolean 属性占了 1 个,对其填充占了 7 个,而实际只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的 JVM 来说,GC 会达到秒级甚至分钟级。大量的内存碎片,会把 JVM 的堆内存划分成一个个的区域。
- OOM 问题影响稳定性:OutOfMenoryError 是分布式计算框架经常会遇到的问题,当 JVM 中所有 对象大小超过分配给 JVM 的内存大小时,就会发生OutOfMenoryError 错误,导致 JVM 崩溃,分布式框架的健壮性和性能都会受到影响。
Flink 内存模型
参考官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/memory/mem_setup/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/memory/mem_setup_tm/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/memory/mem_setup_jobmanager/
Flink 的内存模型从 Flink-1.10 发生了比较大的改变,新版本的内存模型如下:
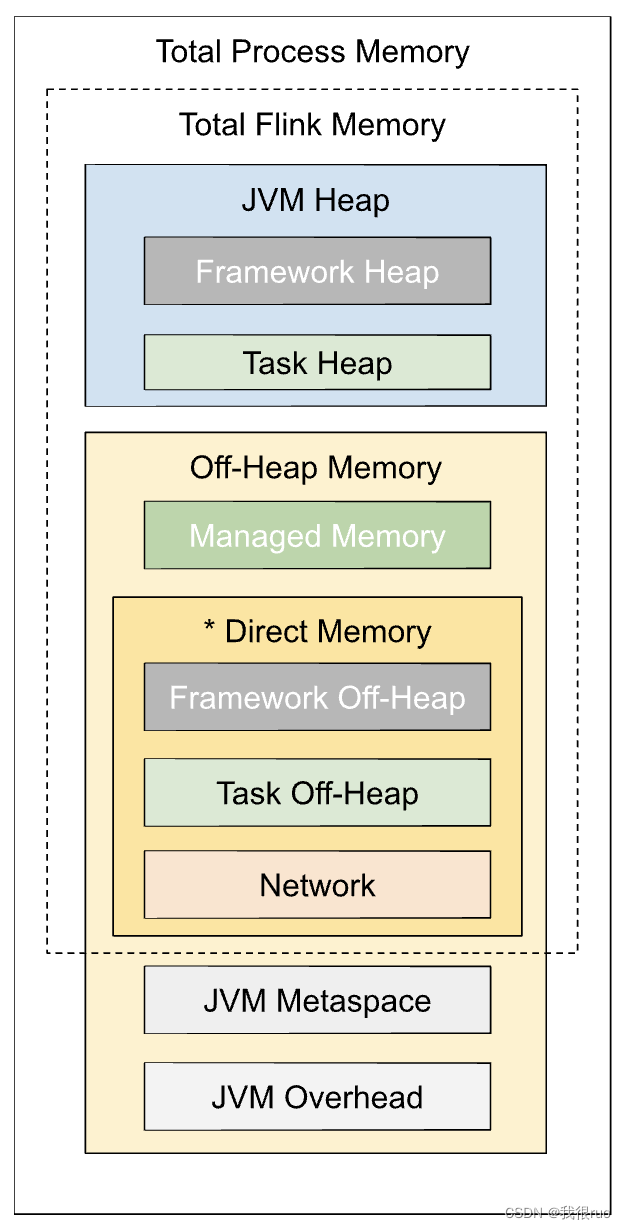
- Total Process Memory,TaskManager 进程总内存,比如在 YARN 环境中,其实就是 Container 的内存大小。
- taskmanager.memory.process.size :无默认值,需要用户指定。
- Total Flink Memory,Flink 总内存,TaskManager 进程占用的所有与 Flink 相关的内存(不包括 JVM 元空间和其他额外开销)。具体包含4大块:Flink 框架内存(堆内、堆外)、托管内存(仅堆外)、网络缓存(仅堆外)、任务内存(堆内、堆外)。
- taskmanager.memory.flink.size :无默认值,需要用户指定。
- FrameWork Heap / Off-heap,Flink 框架内存,Flink Runtime 底层占用的内存,一般来讲相对固定,不需要更改。一般在 Flink 算子并行度特别高的时候,才需要调整。
- taskmanager.memory.framework.heap.size :堆内部分(Framework Heap),默认值 128MB;
- taskmanager.memory.framework.off-heap.size :堆外部分(Framework Off-Heap),以直接内存形式分配,默认值 128MB。
- Managed Memory,Flink 托管内存,纯堆外内存,由 MemoryManager 管理,用于中间结果缓存、排序、哈希表等,以及 RocksDB 状态后端。
- taskmanager.memory.managed.fraction :托管内存占Flink总内存 taskmanager.memory.flink.size 的比例,默认值 0.4;
- taskmanager.memory.managed.size :托管内存的大小,无默认值,一般也不指定,而是依照上述比例来推定,更加灵活。
- Network 网络内存, 纯堆外内存,用于 TaskManager 之间(shuffle、广播等)及与外部组件的数据传输,以直接内存形式分配。
- taskmanager.memory.network.min : 网络缓存的最小值,默认 64MB;
- taskmanager.memory.network.max : 网络缓存的最大值,默认 1GB;
- taskmanager.memory.network.fraction : 网络缓存占 Flink 总内存 taskmanager.memory.flink.size 的比例,默认值 0.1。若根据此比例算出的内存量比最小值小或比最大值大,就会限制到最小值或者最大值。
- Task heap / Off-heap 内存,是算子逻辑和用户代码、自定义数据结构真正占用的内存。
- taskmanager.memory.task.heap.size : 堆内部分(Task Heap),无默认值,一般不建议设置,会自动用 Flink 总内存减去框架、托管、网络三部分 的内存推算得出。
- taskmanager.memory.task.off-heap.size : 堆外部分(Task Off-Heap),以直接内存形式分配,默认值为 0,即不使用。
- JVM Metaspace,Flink JVM 进程的元数据空间大小
- taskmanager.memory.jvm-metaspace.size :默认值 256MB。
- JVM Overhead,为 JVM 进程预留的其他本地内存,用于线程栈、代码缓存、垃圾收集。它是 Total Process Memory(整个进程) 的一个有上下限的细分组件。
- taskmanager.memory.jvm-overhead.min : JVM 额外开销的最小值,默认 192MB;
- taskmanager.memory.jvm-overhead.max : JVM 额外开销的最大值,默认 1GB;
- taskmanager.memory.jvm-overhead.fraction : JVM 额外开销占 TM 进程总内存 taskmanager.memory.process.size 的比例,默认值 0.1。若根据此比例算出的内存量比最小值小或比最大值大,就会限制到最小值或者最大值。
生产环境中,主要要调整的参数:
- 在 Standalone 模式下,调整 taskmanager.memory.flink.size 指定 Flink 从节点 TaskManager 总内存
- 在 Flink On YARN 模式下,调整 taskmanager.memory.process.size 指定 Flink 从节点 TaskManager 总内存
- 根据网络流量大小修改网络缓存占比:taskmanager.memory.network.fraction,默认 0.1
- 根据 RocksDB 状态大小等调整托管内存占比:taskmanager.memory.managed.fraction,默认 0.4
案例:
# Flink On YARN 模式下
taskmanager.memory.process.size = 4096 MB = 4G
taskmanager.memory.network.fraction=0.15
taskmanager.memory.managed.fraction=0.45
根据以上参数,就可以计算得到各部分的内存大小:
taskmanager.memory.jvm-overhead = 4096 * 0.1 = 409.6 MB
taskmanager.memory.flink.size = 4096 - 409.6 - 256 = 3430.4 MB
taskmanager.memory.network = 3430.4 * 0.15 = 514.56 MB
taskmanager.memory.managed = 3430.4 * 0.45 = 1543.68 MB
taskmanager.memory.task.heap.size = 3430.4 - 128 * 2 - 1543.68 - 514.56 = 1116.16 MB

另外,还有可以指定 JVM 相关参数的一些选项,也请注意:
