Redis学习之基础知识普及
Redis学习之基础知识普及
-
-
- 1、 Redis安装(单机)
- 2、Redis基本数据结构
- 3、Redis常用命令
-
- 3.1、Redis 键(key)
- 3.2、Redis 字符串(String)
- 3.3、Redis hash 命令
- 3.4、Redis list 命令
- 3.5、Redis 集合(Set)
- 3.6、Redis 有序集合(sorted set)
- 3.7、Redis 高级命令
- 4、Redis的单线程和高性能
-
- 4.1、Redis是单线程吗?
- 4.2、Redis 单线程为什么还能这么快?
- 5、疑问
-
- 5.1、Redis 单线程如何处理那么多的并发客户端连接?
- 5.2、Redis 的瓶颈?
- 6、Redis持久化
-
- 6.1、RDB快照(snapshot)
-
- 6.1.1、bgsave的写时复制(COW)机制
- 6.1.2、save与bgsave对比
- 6.2、AOF(append-only file)
-
- 6.2.1、AOF重写
- 6.3、Redis 4.0 混合持久化
-
1、 Redis安装(单机)
下载地址:http://redis.io/download
安装步骤:
# 安装gcc
yum install gcc
# 把下载好的redis-5.0.3.tar.gz放在/usr/local文件夹下,并解压
wget http://download.redis.io/releases/redis-5.0.3.tar.gz
tar xzf redis-5.0.3.tar.gz
cd redis-5.0.3
# 进入到解压好的redis-5.0.3目录下,进行编译与安装
make
# 修改配置
daemonize yes #后台启动
protected-mode no #关闭保护模式,开启的话,只有本机才可以访问redis
# 需要注释掉bind
#bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
#设置密码 设置密码后才能进行远程登录
password xxxx
# 启动服务
src/redis-server redis.conf
# 验证启动是否成功
ps -ef | grep redis
# 进入redis客户端
src/redis-cli
#登录
auth password
# 退出客户端
quit
# 关闭redis服务
(1)pkill redis-server
(2)kill 进程号
(3)src/redis-cli shutdown
2、Redis基本数据结构
- String: 字符串
- Hash: 散列
- List: 列表
- Set: 集合
- Sorted Set: 有序集合
3、Redis常用命令
3.1、Redis 键(key)
| 命令 | 命令 |
|---|---|
| DEL key该命令用于在 key 存在时删除 key。 | EXISTS key检查给定 key 是否存在。 |
| EXPIRE keyseconds为给定 key 设置过期时间,以秒计。 | KEYS pattern查找所有符合给定模式( pattern)的 key |
| TTL key以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 | TYPE key 返回 key 所储存的值的类型。 |
3.2、Redis 字符串(String)
| 命令 | 命令 |
|---|---|
| SET key value 设置指定 key 的值 | GET key 获取指定 key 的值。 |
| GETRANGE key start end 返回 key 中字符串值的子字符 | GETSET key value 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| SETEX key seconds value 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 | SETNX key value 只有在 key 不存在时设置 key 的值。 |
| SETRANGE key offset value 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 | STRLEN key 返回 key 所储存的字符串值的长度。 |
| MSET key value [key value …] 同时设置一个或多个 key-value 对。 | MSETNX key value [key value …] 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 |
| INCR key 将 key 中储存的数字值增一。 | INCRBY key increment将 key 所储存的值加上给定的增量值(increment) |
| DECR key 将 key 中储存的数字值减一。 | DECRBY key decrementkey 所储存的值减去给定的减量值(decrement) |
3.3、Redis hash 命令
| 命令 | 命令 |
|---|---|
| HMSET key field1 value1 [field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表 key 中。 | HSET key field value [field2 value2 ] 将哈希表 key 中的字段 field 的值设为 value |
| HSETNX key field value 只有在字段 field 不存在时,设置哈希表字段的值。 | HVALS key 获取哈希表中所有值。 |
| HLEN key 获取哈希表中字段的数量 | HKEYS key 获取所有哈希表中的字段 |
| HGET key field 获取存储在哈希表中指定字段的值。 | HGETALL key 获取在哈希表中指定 key 的所有字段和值 |
| HDEL key field1 [field2] 删除一个或多个哈希表字段 | HEXISTS key field 查看哈希表 key 中,指定的字段是否存在。 |
3.4、Redis list 命令
| 添加操作 | |
|---|---|
| LPUSH key value1 [value2] 将一个或多个值插入到列表头部 | LPUSHX key value 将一个值插入到已存在的列表头部 (key应该存在不存在插入不成功) |
| RPUSH key value1 [value2] 在列表中添加一个或多个值 | RPUSHX key value 为已存在的列表添加值 |
| LINSERT key BEFORE|AFTER pivot value在列表的元素前或者后插入元素 pivot需要插入元素的位置,value需要插入的值 | |
| 查找操作 | LRANGE key start stop 获取列表指定范围内的元素start 0 stop -1则获取所有 |
| 修改操作 : | LSET key index value 通过索引设置列表元素的值 |
| 删除操作 | |
| RPOP key移除列表的最后一个元素,返回值为移除的元素 | LPOP key移出并获取列表的第一个元素 |
| BLPOP key1 [key2 ] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 | BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
| LREM key count value 移除列表元素 | LTRIM key start stop 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 统计 | |
| LINDEX key index 通过索引获取列表中的元素 | LLEN key 获取列表长度 |
| 其他 | |
| RPOPLPUSH source destination 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 | BRPOPLPUSH source destination timeout 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
3.5、Redis 集合(Set)
| 命令 | 命令 |
|---|---|
| SADD key member1 [member2] 向集合添加一个或多个成员 | SMEMBERS key 返回集合中的所有成员 |
| SPOP key 移除并返回集合中的一个随机元素 | SREM key member1 [member2] 移除集合中一个或多个成员 |
3.6、Redis 有序集合(sorted set)
| 命令 | 命令 |
|---|---|
| ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 | ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合指定区间内的成员 |
| ZRANK key member 返回有序集合中指定成员的索引 | ZREM key member [member …] 移除有序集合中的一个或多个成员 |
3.7、Redis 高级命令
Info:查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
Server 服务器运行的环境参数
Clients 客户端相关信息
Memory 服务器运行内存统计数据
Persistence 持久化信息
Stats 通用统计数据
Replication 主从复制相关信息
CPU CPU 使用情况
Cluster 集群信息
KeySpace 键值对统计数量信息
connected_clients:2 # 正在连接的客户端数量
instantaneous_ops_per_sec:789 # 每秒执行多少次指令
used_memory:929864 # Redis分配的内存总量(byte),包含redis进程内部的开销 #和数据占用的内存
used_memory_human:908.07K # Redis分配的内存总量(Kb,human会展示出单位)
used_memory_rss_human:2.28M # 向操作系统申请的内存大小(Mb)(这个值一般是大于 #used_memory的,因为Redis的内存分配策略会产生内存碎 片)
used_memory_peak:929864 # redis的内存消耗峰值(byte)
used_memory_peak_human:908.07K # redis的内存消耗峰值(KB)
maxmemory:0 # 配置中设置的最大可使用内存值(byte),默认0,不限制
maxmemory_human:0B # 配置中设置的最大可使用内存值
maxmemory_policy:noeviction # 当达到maxmemory时的淘汰策略
4、Redis的单线程和高性能
4.1、Redis是单线程吗?
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
4.2、Redis 单线程为什么还能这么快?
-
纯内存级别的处理,数据的读写以及相应处理均在内存中进行。
-
单线程避免了线程切换、加锁/解锁、线程竞争的消耗 。
-
读写IO请求使用IO多路复用技术,一个线程可以同时处理多个Socket连接的读写请求事件
-
redis内部使用一个redisObject对象来表示所有的key和value,括数据类型、编码方式、数据指针、虚拟内存等
针对不同的场景使用对应的数据类型,减少内存使用的同时,节省网络流量传输。
5、疑问
5.1、Redis 单线程如何处理那么多的并发客户端连接?
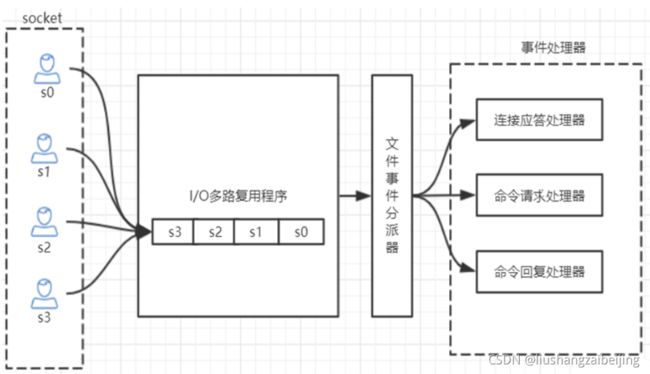
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
# 查看redis支持的最大连接数,在redis.conf文件中可修改,# maxclients 10000
127.0.0.1:6379> CONFIG GET maxclients
##1) "maxclients"
##2) "10000"
5.2、Redis 的瓶颈?
CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
redis是单线程的,所有对于多核CPU来说无法发挥其优势,所以可以在一台机器上启动多个redis实例组成集群来充分使用机器的多核优势。
6、Redis持久化
6.1、RDB快照(snapshot)
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。
你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:
**# save 60 1000 //**关闭RDB只需要将所有的save保存策略注释掉即可
还可以手动执行命令生成RDB快照,进入redis客户端执行命令save或bgsave可以生成dump.rdb文件,每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
6.1.1、bgsave的写时复制(COW)机制
Redis 借助操作系统提供的写时复制技术(Copy-On-Write, COW),在生成快照的同时,依然可以正常处理写命令。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
6.1.2、save与bgsave对比
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函数时会有短暂阻塞) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置自动生成rdb文件后台使用的是bgsave方式。
6.2、AOF(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化,将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间fsync到磁盘)
比如执行命令**“set zhuge 666”**,aof文件里会记录如下数据
*3
$3
set
$5
zhuge
$3
666
这是一种resp协议格式数据,星号后面的数字代表命令有多少个参数,$号后面的数字代表这个参数有几个字符
注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的时间戳
比如执行**“set tuling 888 ex 1000”**
你可以通过修改配置文件来打开 AOF 功能:
# appendonly yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。
这样的话, 当 Redis 重新启动时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。
有三个选项:
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。 appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。 appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
6.2.1、AOF重写
AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据生成aof文件
例如,执行了如下几条命令:
127.0.0.1:6379> incr readcount
(integer) 1
127.0.0.1:6379> incr readcount
(integer) 2
127.0.0.1:6379> incr readcount
(integer) 3
127.0.0.1:6379> incr readcount
(integer) 4
127.0.0.1:6379> incr readcount
(integer) 5
重写后AOF文件里变成
*3
$3
SET
$2
readcount
$1
5
如下两个配置可以控制AOF自动重写频率
#aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
auto-aof-rewrite-min-size 64mb
#aof文件自上一次重写后文件大小增长了100%则再次触发重写
auto-aof-rewrite-percentage 100
当然AOF还可以手动重写,进入redis客户端执行命令bgrewriteaof重写AOF
注意,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多影响
6.1.2、RDB 和 AOF ,我应该用哪一个?
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更全一点。
6.3、Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志,但是AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。
通过如下配置可以开启混合持久化(必须先开启aof):
aof-use-rdb-preamble yes
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,因此重启效率大幅得到提升。
混合持久化AOF文件结构如下
