TF-IDF(Term Frequency-Inverse Document Frequency)算法详解
目录
概述
术语解释
词频(Term Frequency)
文档频率(Document Frequency)
倒排文档频率(Inverse Document Frequency)
计算(Computation)
代码语法
代码展示
安装相关包
测试代码及其结果
结果整理
概述
TF-IDF代表记录的词频倒排文档频率。它可以定义为计算一个词在一系列或语料库中与文本的相关性。其含义与词在文本中出现的次数成比例增加,但受语料库(数据集)中该词的频率的补偿。
术语解释
词频(Term Frequency)
在文档d中,频率表示给定词t的实例数量。因此,我们可以看到当一个词在文本中出现时,它变得更相关,这是合理的。由于术语的顺序不重要,我们可以使用一个向量来描述基于词袋模型的文本。对于论文中的每个特定术语,都有一个条目,其值是词频。
在文档中出现的术语的权重与该术语的词频成正比。
延伸:BM25 TF 计算(Bese Match25 Term Frequency)
用于测量特定文档中词项的频率,同时进行文档长度和词项饱和度的调整。
![]() : 词项在文档中的频率。
: 词项在文档中的频率。 ![]() : 用于控制词项频率饱和度的调节参数(通常为1.2)。
: 用于控制词项频率饱和度的调节参数(通常为1.2)。  : 用于控制字段长度归一化的调节参数(通常为0.75)。
: 用于控制字段长度归一化的调节参数(通常为0.75)。 ![]() : 文档中字段的长度。
: 文档中字段的长度。 ![]() : 所有文档中字段平均长度。
: 所有文档中字段平均长度。
文档频率(Document Frequency)
这测试了文本在整个语料库集合中的意义,与TF非常相似。唯一的区别在于,在文档d中,TF是词项t的频率计数器,而df是词项t在文档集N中的出现次数。换句话说,包含该词的论文数量即为DF。
倒排文档频率(Inverse Document Frequency)
主要用于测试词语的相关性。搜索的主要目标是找到符合需求的适当记录。由于tf认为所有术语同等重要,因此仅使用词频来衡量论文中术语的权重并不充分。首先,通过计算包含术语t的文档数量来找到术语t的文档频率:
![]()
其中,![]() 为术语
为术语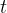 的文档频率,
的文档频率,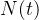 为包含术语的文档数量。
为包含术语的文档数量。
术语频率是指一个单一文档中术语出现的次数;而文档的频率是该术语在多个文档中出现的独立次数,它取决于整个语料库。现在让我们来看一下倒排文档频率的定义。词语的倒排文档频率是语料库中包含该词的文档数量与文本频率的倒数。 表示总文档数。
表示总文档数。
常见的词语应被认为不太重要,但是采用最确定的整数元素似乎过于严格。因此,我们取该词在文档中的逆频率的对数(以2为底)。因此,术语t的逆文档频率(idf)变为:
延伸:在ES中使用的形式如下,通过设置ES查询的 "explain": true 参数可见。
0.5 是为了平滑,以避免由零除和对非常罕见的术语进行过度加权。
计算(Computation)
TF-IDF是确定一个词对于一系列文本或语料库的重要性的最佳度量之一。TF-IDF是一个加权系统,根据词频(TF)和逆文档频率(IDF)为文档中的每个词分配权重。具有更高权重得分的词被视为更重要。
通常,TF-IDF权重由两个术语组成:
- 规范化词频(TF)
- 逆文档频率(IDF)
代码语法
在Python中,可以使用sklearn模块中的TfidfVectorizer()方法计算TF-IDF值。
sklearn.feature_extraction.text.TfidfVectorizer(input)
Parameters:
input: 指定要传递的文档参数,可以是文件名、文件或文本内容本身。
Attributes:
vocabulary_: 返回一个字典,其中术语是键,特征索引是值。**
idf_: 返回作为参数传递的文档的逆文档频率向量。
Returns:
fit_transform(): 返回一个包含术语及其TF-IDF值的数组。
get_feature_names():返回一个特征名称列表。
代码展示
安装相关包
pip install scikit-learn
测试代码及其结果
from sklearn.feature_extraction.text import TfidfVectorizer
# 定义文档
d0 = 'Euler is a great man'
d1 = 'Euler'
d2 = 'nothing'
# 合并文档成为一个单一的语料库。
string = [d0, d1, d2]
# 从fit_transform()方法中获取TF-IDF值。
# 创建对象
tfidf = TfidfVectorizer()
# 获取 tf-df 值
result = tfidf.fit_transform(string)
# 打印语料库中单词的逆文档频率(IDF)值。
for ele1, ele2 in zip(tfidf.get_feature_names_out(), tfidf.idf_):
print(ele1, ':', ele2)
# IDF结果输出 >>>
"""
euler : 1.2876820724517808
great : 1.6931471805599454
is : 1.6931471805599454
man : 1.6931471805599454
nothing : 1.6931471805599454
"""
# 索引获取
>>> tfidf.vocabulary_
"""
{'euler': 0, 'is': 2, 'great': 1, 'man': 3, 'nothing': 4}
"""
# tf-idf
>>> print(result)
# (文档编号,单词索引) tf-idf
"""
(0, 3) 0.5286346066596935
(0, 1) 0.5286346066596935
(0, 2) 0.5286346066596935
(0, 0) 0.4020402441612698
(1, 0) 1.0
(2, 4) 1.0
"""
# 可通过如下方式转成matrix形式
>>> result.toarray()
"""
array([[0.40204024, 0.52863461, 0.52863461, 0.52863461, 0. ],
[1. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 1. ]])
"""
结果整理
| Document | Word | Document Index | Word Index | tf-idf value |
|---|---|---|---|---|
| d0 | euler | 0 | 0 | 0.4020402441612698 |
| d1 | euler | 1 | 0 | 1.0 |
| d0 | is | 0 | 2 | 0.5286346066596935 |
| d0 | great | 0 | 1 | 0.5286346066596935 |
| d0 | man | 0 | 3 | 0.5286346066596935 |
| d2 | nothing | 2 | 4 | 1.0 |