文献阅读1
A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
会议/期刊:CVPR 2023;阿里达摩院;Biwen Lei
概述:这是一篇单张图片三维人脸重建的论文,这篇论文的主要目标是在三维人脸重建时尽量还原细节信息。
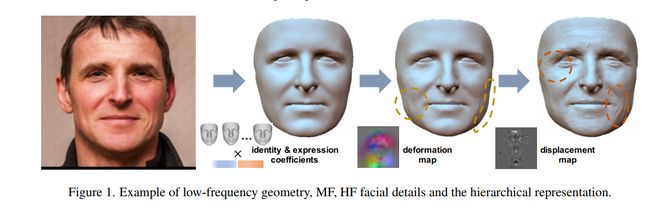
如上图所示,他们将人脸重建过程分为三个部分,分别用低频、中频、高频信号来区分。低频表示基本的形状,也就是用3dmm生成的部分;中频表示顶点尺度的几何变形,用deformation map (64*64*3)来记录;高频表示像素尺度的位移,也就是一个displacement map(normal map)(256*256),在渲染的时候根据像素进行高度的插值。
我觉得很神奇的一点是,他的中频信号尽管只用于每个顶点的变形,但他仍然是用贴图的方式来存储,实际上如果deformation map的分辨率大一些,是和displacement map有类似作用的。是否真的有必要强行拆分成两个部分呢?
下图展示了他们的方法流程图:

左上角部分是用一个网络去预测BFM的参数和纹理贴图;左下角是根据输入和BFM生成的形状生成离线的训练数据(用于右下角的一些loss的计算);右下角则体现了论文“Hierarchical”的思路,分级地去分别预测两个贴图,里面的“pix2pix”是前人提出的网络;右上角则是在训练中可微渲染成图像之后去学习网络权重。
他们的方法在REALY benchmark以及一些其它数据集上取得了SOTA。
Sdfusion: Multimodal 3d shape completion, reconstruction, and generation
会议/期刊:CVPR 2023;伊利诺伊大学厄巴纳-香槟分校(University of Illinois Urbana-Champaign,UIUC);Yen-Chi Cheng
概述:用diffusion model进行3D资源的生成。下图展示了核心方法流程:

首先diffusion model本身对计算性能要求就很高,再加上想用在三维数据上,原始分辨率肯定不可行。因此论文首先将三维模型(T-SDF显式表示)通过VQ-VAE压缩,这里的VQ-VAE是3D版本的,基本和图像类似,把一个“大图像”压缩成一个“小图像”。图中 E φ E_{\varphi} Eφ 和 D φ D_{\varphi} Dφ 就是对应的编码器和解码器。编码后的size论文里好像没说,我去看了下代码应该是 1 6 3 16^3 163 。
图中蓝色框框就是diffusion model,在逆扩散过程用一个UNet去学习概率分布。
图中左下角解释了文章为什么说是“multimodal”,文章使用了High-Resolution Image Synthesis with Latent Diffusion Models提出的方法对逆扩散过程进行条件控制。然后对其它模态的输入进行编码,则是用的现有的方法,例如图像用CLIP、文本用BERT。
High-Resolution Image Synthesis with Latent Diffusion Models
会议/期刊:CVPR 2022;Ludwig Maximilian University of Munich & IWR, Heidelberg University, Germany;Robin Rombach
概述:之前的diffusion model都是直接在图像上做的,因为对计算资源要求高,往往图像分辨率会受到很大的限制。像是guided diffusion的图像一般都是256*256,这就需要大量的GPU去进行训练。这篇论文提出的方案是将图像编码到latent space,然后在隐空间做diffusion。
按照我的理解,图像本身包含了大量的冗余信息,例如某个像素的颜色可能和其周围的非常接近,又比如将图像分辨率减半实际上并不会太影响对图像信息的理解。因此先进行压缩到最小的语义空间然后再进行diffusion,是一个很朴素的思想。

文章使用的编码器和解码器( ε \varepsilon ε和 D D D)是一个GAN架构,中间的latent space 用VQVAE的离散形式表示,通俗来讲就是”把大图像压缩成小图像“。文章中称为perceptual compression。进行压缩后的扩散模型优化目标可以写为
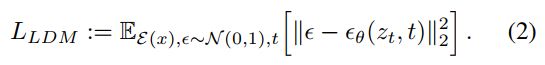
除了latent的特点之外,论文还给出了条件控制的方法,也就是图中右边框框所示。对于不同模态的控制条件输入 y y y,用一个domain specific encoder τ θ \tau_{\theta} τθ 进行编码,然后用 cross-attention 的注意力机制,实际上就是注意力机制,只不过QKV用 τ θ \tau_{\theta} τθ 的输出进行计算:
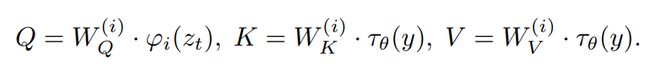
这样将控制信息引入diffusion过程。
NerVE: Neural Volumetric Edges for Parametric Curve Extraction from Point Cloud
会议/期刊:CVPR 2023;SSE, CUHKSZ(港中大深圳理工);Xiangyu Zhu
概述:一个从点云提取参数化曲线的工作。
传统的边缘提取的做法是,先识别出关键点,然后再提取边缘。本文则是直接提取出曲线,方法流程如下:
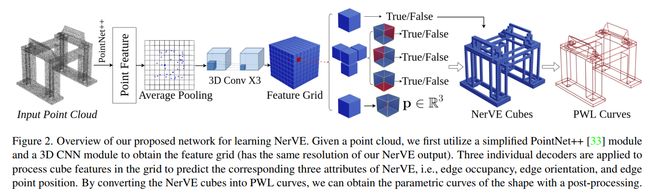
首先论文定义了“边”如何用体素来表示(Volumetric Edge),大致就是对每一个体素定义:(1)是否占用;(2)是否与邻居相连,论文定义了方向所以只有3个邻居;(3)顶点在体素,也就是一个小方块里面的坐标。
然后对于输入的点云,接一个PointNet++,最后池化为一个特征向量,然后再用3D CNN卷积为体素形式,也就是图中的“Feature Grid”。这个Feature Grid其实就是预测的Volumetric Edge,大括号右边的三个对应上一段介绍的三个数据。根据每个像素存储的3个数据,可以提取出分段线段表示(Piece-Wise Linear, PWL),虽然图中画的是"NerVE Cubes",但实际上用到的是存储的顶点坐标嘛,所以实际上就是一条一条的线段。最后用参数化样条去拟合这些线段,得到边缘结果。
我对这篇论文的看法是,首先分辨率有限,如中的Feature Grid分辨率是 3 2 3 32^3 323,不如说三维体素的神经网络分辨率都不会太高,论文里也提到这会导致很多交叉点;其次这种方法应该适合边缘比较规整的点云,通俗点讲就是“横平竖直”,比如论文只在CAD数据上做了测试。
Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
会议/期刊:arxiv;Google Research, Brain Team;Hshmat Sahak
概述:该论文将扩散模型用于超分辨率领域,超过了过去的由GAN得到的SOTA。我大致看了下论文,他们用的网络结构基本就是另外一篇论文的网络,然后介绍了很多对图像做“degradation”的方法,例如Blur、Resize、JPEG compression,最后再加上添加噪声去增强数据。感觉文章主要说了怎么构造数据去训练,之后就是对比实验。