EM算法和VAE的学习笔记
文章目录
-
-
-
- 摘要
- EM算法流程
- EM算法对GMM的参数估计
- EM算法的证明
- EM算法的另一种理解
- VAE
- 参考文献
-
-
摘要
这是我学习EM算法(Expectation-Maximization Algorithm)和VAE(Variational Auto-Encoder)的学习笔记,首先总结了EM算法流程,然后举了一个例子,用EM算法对GMM进行参数估计,然后证明了EM算法的正确性,然后推导出EM算法的另外一种解释,以引入VAE,最后介绍了VAE的变分推断方法。
EM算法流程
假设有一个概率模型 P ( x , z ; θ ) P(x,z;\theta) P(x,z;θ),其中 z z z是隐变量(无法观测), θ \theta θ是参数,观测到的数据集合为 { x ( 1 ) , . . . , x ( m ) } \{x^{(1)},...,x^{(m)}\} {x(1),...,x(m)},EM算法的目的就是求解这个概率模型参数 θ \theta θ的最大似然估计,即:
θ ∗ = a r g m a x θ ∏ i = 1 m P ( x ( i ) ; θ ) \theta^*=\mathop{argmax}_{\theta} \prod_{i=1}^m P(x^{(i)};\theta) θ∗=argmaxθi=1∏mP(x(i);θ)
EM算法循环执行以下两个步骤直至收敛:
E步:
根据当前的参数 θ \theta θ,估计隐变量 z z z的分布
Q i ( z ( i ) ) : = P ( z ( i ) ∣ x ( i ) ; θ ) Q_i(z^{(i)}):=P(z^{(i)}|x^{(i)};\theta) Qi(z(i)):=P(z(i)∣x(i);θ)
M步:
根据当前隐变量的分布,最大化似然函数以获取新的参数
θ : = a r g m a x θ ∑ i ∑ z ( i ) Q i ( z ( i ) ) log P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \theta := \mathop{argmax}\limits_{\theta}\sum\limits_{i}\sum\limits_{z^{(i)}}Q_i(z^{(i)})\log\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} θ:=θargmaxi∑z(i)∑Qi(z(i))logQi(z(i))P(x(i),z(i);θ)
EM算法对GMM的参数估计
考虑一个一维的混合高斯模型(Gaussian Mixed Model, GMM) P ( x , z ; θ ) P(x,z;\theta) P(x,z;θ),从中有观测数据集合 { x ( 1 ) , . . . , x ( m ) } \{x^{(1)},...,x^{(m)}\} {x(1),...,x(m)},对于 x ( i ) x^{(i)} x(i), z ( i ) z^{(i)} z(i)服从多项式分布 multinomial ( ϕ ) \text{multinomial}(\phi) multinomial(ϕ)且 z ( i ) ∈ { 1 , . . . , K } z^{(i)}\in\{1,...,K\} z(i)∈{1,...,K},其中 K K K表示高斯分布的数目。也就是说 x ( i ) ∣ z ( i ) = j ∼ N ( μ j , σ j ) x^{(i)}|z^{(i)}=j \sim N(\mu_j,\sigma_j) x(i)∣z(i)=j∼N(μj,σj) 。
解释一下GMM存在什么问题:当我们根据混合高斯模型来采样一个数据 x ( i ) x^{(i)} x(i)时,这个数据必定服从某一个高斯分布,但是我们不知道是哪个高斯分布,这里的“哪个”其实就是一个隐变量,我们用 z ( i ) z^{(i)} z(i)来表示这个隐变量,并用 w j ( i ) = P ( z ( i ) = j ∣ x ( i ) ) w_j^{(i)}=P(z^{(i)}=j|x^{(i)}) wj(i)=P(z(i)=j∣x(i))来表示 z ( i ) z^{(i)} z(i)取值为 j j j的概率。
接下来套用EM算法进行混合高斯模型的参数估计:
E步:
w j ( i ) = P ( z ( i ) = j ∣ x ( i ) ; θ ) = P ( x ( i ) ∣ z ( i ) = j ) P ( z ( i ) = j ) ∑ l = 1 K P ( x ( i ) ∣ z ( i ) = l ) P ( z ( i ) = l ) \begin{aligned} w_j^{(i)} &= P(z^{(i)}=j|x^{(i)};\theta) \\ &= \frac{P(x^{(i)}|z^{(i)}=j)P(z^{(i)}=j)}{\sum\limits_{l=1}^K P(x^{(i)}|z^{(i)}=l)P(z^{(i)}=l)} \end{aligned} wj(i)=P(z(i)=j∣x(i);θ)=l=1∑KP(x(i)∣z(i)=l)P(z(i)=l)P(x(i)∣z(i)=j)P(z(i)=j)
这里用到了贝叶斯公式来计算后验概率,上式第二行的所有概率都是已知的,因为这一步固定了参数 θ \theta θ(当然包括了 μ , σ , ϕ \mu,\sigma,\phi μ,σ,ϕ),因此 P ( x ( i ) ∣ z ( i ) = j ) P(x^{(i)}|z^{(i)}=j) P(x(i)∣z(i)=j)就是高斯分布的取值, P ( z ( i ) = j ) P(z^{(i)}=j) P(z(i)=j)就是多项式分布的取值 ϕ j \phi_j ϕj,实际上对应E步中 Q i ( z ( i ) ) = w ( i ) Q_i(z^{(i)})=w^{(i)} Qi(z(i))=w(i) 。
M步:
对对数似然函数
∑ i ∑ z ( i ) = j w j ( i ) log P ( x ( i ) , z ( i ) ; θ ) w j ( i ) \sum_i\sum_{z^{(i)}=j} w^{(i)}_j\log\frac{P(x^{(i)},z^{(i)};\theta)}{w_j^{(i)}} i∑z(i)=j∑wj(i)logwj(i)P(x(i),z(i);θ)
求导等于0之后可解得:
ϕ j = 1 m ∑ i = 1 m w j ( i ) μ j = ∑ i = 1 m w j ( i ) x ( i ) ∑ i = 1 m w j ( i ) σ j = ∑ i = 1 m w j ( i ) ( x ( i ) − μ j ) ( x ( i ) − μ j ) T ∑ i = 1 m w j ( i ) \begin{aligned} \phi_j &= \frac{1}{m}\sum_{i=1}^m w_j^{(i)} \\ \mu_j &= \frac{\sum_{i=1}^m w_j^{(i)}x^{(i)}}{\sum_{i=1}^m w_j^{(i)}} \\ \sigma_j &= \frac{\sum_{i=1}^m w_j^{(i)}(x^{(i)}-\mu_j)(x^{(i)}-\mu_j)^T}{\sum_{i=1}^m w_j^{(i)}} \end{aligned} ϕjμjσj=m1i=1∑mwj(i)=∑i=1mwj(i)∑i=1mwj(i)x(i)=∑i=1mwj(i)∑i=1mwj(i)(x(i)−μj)(x(i)−μj)T
求导过程我也没推导,反正代入高斯分布的解析式后是可以算出来的,只是可能有点复杂。
可以看到EM算法与k-means有一定的相似之处:在E步相当于对每个样本 x ( i ) x^{(i)} x(i),计算它属于每个高斯分布 j j j的概率,而k-means算法则是直接选择一个最近的cluster,相比之下EM算法更加“软”一些;而在M步则是去更新参数,k-means算法则是去更新cluster的中心。
EM算法的证明
首先讲一下Jensen不等式,它讲的事情大概是这样的:对于凸函数(convex,一元函数里一般称为“下凸”) f ( x ) f(x) f(x),有不等式
∑ i α i f ( x i ) ≥ f ( ∑ i α i x i ) , ∑ i α i = 1 \sum_i\alpha_if(x_i)\ge f(\sum_i\alpha_ix_i), \quad\quad \sum_i\alpha_i=1 i∑αif(xi)≥f(i∑αixi),i∑αi=1
其中等号成立当且仅当所有 x i x_i xi都相等。这个通过画一个二次函数和一条弦的示意图就能很直观的理解并且记忆大小关系。
然后在概率统计中,我们把上式套用在“期望”上就可以得到:
E [ f ( x ) ] ≥ f ( E [ x ] ) E[f(x)]\ge f(E[x]) E[f(x)]≥f(E[x])
其中等号成立当且仅当 x x x是一个常数。
当然,如果 f f f是一个凹函数(concave),上面的不等关系都要反过来。
接下来我们考虑概率模型 P ( x , z ; θ ) P(x,z;\theta) P(x,z;θ)中参数 θ \theta θ的对数似然
L ( θ ) = ∑ i = 1 m log P ( x ( i ) ; θ ) = ∑ i = 1 m log ∑ z ( i ) P ( x ( i ) , z ( i ) ; θ ) \begin{aligned} L(\theta) &= \sum_{i=1}^m \log P(x^{(i)};\theta) \\ &= \sum_{i=1}^m \log \sum_{z^{(i)}} P(x^{(i)},z^{(i)};\theta) \end{aligned} L(θ)=i=1∑mlogP(x(i);θ)=i=1∑mlogz(i)∑P(x(i),z(i);θ)
为什么要把边缘概率变成联合概率的积分形式呢?这是因为直接对 θ \theta θ求导很困难,毕竟我们不知道隐变量 z z z的分布或具体取值。
接下来我们想办法把 L ( θ ) L(\theta) L(θ)变成“期望”的形式,亦即引入 z ( i ) z^{(i)} z(i)的分布:
L ( θ ) = ∑ i = 1 m log ∑ z ( i ) P ( x ( i ) , z ( i ) ; θ ) = ∑ i = 1 m log ∑ z ( i ) Q i ( z ( i ) ) P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) = ∑ i = 1 m log E z ( i ) ∼ Q i [ P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) ] \begin{aligned} L(\theta) &= \sum_{i=1}^m \log \sum_{z^{(i)}} P(x^{(i)},z^{(i)};\theta) \\ &= \sum_{i=1}^m \log \sum_{z^{(i)}} Q_i(z^{(i)}) \frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} \\ &= \sum_{i=1}^m \log E_{z^{(i)}\sim Q_i} [\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}] \end{aligned} L(θ)=i=1∑mlogz(i)∑P(x(i),z(i);θ)=i=1∑mlogz(i)∑Qi(z(i))Qi(z(i))P(x(i),z(i);θ)=i=1∑mlogEz(i)∼Qi[Qi(z(i))P(x(i),z(i);θ)]
其中 ∑ z ( i ) Q i ( z ( i ) ) = 1 \sum_{z^{(i)}}Q_i(z^{(i)})=1 ∑z(i)Qi(z(i))=1 。在这里对数函数是一个凹函数,运用Jensen不等式可以得到
L ( θ ) ≥ ∑ i = 1 m E z ( i ) ∼ Q i [ log P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) ] = ∑ i = 1 m ∑ z ( i ) Q i ( z ( i ) ) log P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} L(\theta) &\ge \sum_{i=1}^m E_{z^{(i)}\sim Q_i} [\log\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}] \\ &= \sum_{i=1}^m \sum_{z^{(i)}} Q_i(z^{(i)}) \log\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} \end{aligned} L(θ)≥i=1∑mEz(i)∼Qi[logQi(z(i))P(x(i),z(i);θ)]=i=1∑mz(i)∑Qi(z(i))logQi(z(i))P(x(i),z(i);θ)
上式等号成立当且仅当
log P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) = log c \log\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} = \log c logQi(z(i))P(x(i),z(i);θ)=logc
为一个常数,即
P ( x ( i ) , z ( i ) ; θ ) = c Q i ( z ( i ) ) P(x^{(i)},z^{(i)};\theta) = c Q_i(z^{(i)}) P(x(i),z(i);θ)=cQi(z(i))
左右两边对 z ( i ) z^{(i)} z(i)做个积分(求和)可以得到:
∑ z ( i ) P ( x ( i ) , z ( i ) ; θ ) = ∑ z ( i ) c Q i ( z ( i ) ) = c \sum_{z^{(i)}} P(x^{(i)},z^{(i)};\theta) =\sum_{z^{(i)}} c Q_i(z^{(i)})=c z(i)∑P(x(i),z(i);θ)=z(i)∑cQi(z(i))=c
也就是说
Q i ( z ( i ) ) = P ( x ( i ) , z ( i ) ; θ ) ∑ z ( i ) P ( x ( i ) , z ( i ) ; θ ) = P ( z ( i ) ∣ x ( i ) ; θ ) \begin{aligned} Q_i(z^{(i)}) &= \frac{P(x^{(i)},z^{(i)};\theta)}{\sum_{z^{(i)}} P(x^{(i)},z^{(i)};\theta)}\\ &= P(z^{(i)}|x^{(i)};\theta) \end{aligned} Qi(z(i))=∑z(i)P(x(i),z(i);θ)P(x(i),z(i);θ)=P(z(i)∣x(i);θ)
到这里我们算是推出了E步中估计 z ( i ) z^{(i)} z(i)分布的公式。然而我们引入不等式以及令等号成立,为什么要这样做呢?下面这张图可以直观地解释:

图中上面的大曲线表示 L ( θ ) L(\theta) L(θ),我们的目的是最大化似然函数,当迭代到 θ t \theta^t θt时,下面的小曲线就是用不等式放缩后的式子,它有两个特性:
- 恒在大曲线下方,对应小于等于的关系;
- 有一点与大曲线相切,对应等号成立的关系。
于是在E步,相当于固定 θ t \theta^t θt,我们构造一个这样的小曲线;
然后在M步,相当于固定 z ( i ) z^{(i)} z(i)的分布,最大化(放缩后的)似然函数以更新新的 θ t + 1 \theta^{t+1} θt+1。
从图像来理解,M步对应的 L ( θ ) L(\theta) L(θ)一定是递增的,而且显然存在上界,因此最终必然会收敛(到局部最优解,并不一定是全局最优解)。
EM算法的另一种理解
前面我们提到
L ( θ ) = ∑ i = 1 m log P ( x ( i ) ; θ ) = ∑ i = 1 m log ∑ z ( i ) Q i ( z ( i ) ) P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) ≥ ∑ i = 1 m ∑ z ( i ) Q i ( z ( i ) ) log P ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} L(\theta) &= \sum_{i=1}^m \log P(x^{(i)};\theta) \\ &= \sum_{i=1}^m \log \sum_{z^{(i)}} Q_i(z^{(i)}) \frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} \\ &\ge \sum_{i=1}^m \sum_{z^{(i)}} Q_i(z^{(i)}) \log\frac{P(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} \end{aligned} L(θ)=i=1∑mlogP(x(i);θ)=i=1∑mlogz(i)∑Qi(z(i))Qi(z(i))P(x(i),z(i);θ)≥i=1∑mz(i)∑Qi(z(i))logQi(z(i))P(x(i),z(i);θ)
也就是利用Jensen不等式的期望形式做了一个可以取到等号的放缩,网上绝大部分的资料都会这么解释EM算法。
然而,我们用另外一种方式去理解的话,其实可以去度量不等式左右两侧的差值:
首先为了公式简洁,我们不考虑求和形式,根据贝叶斯公式 P ( a , b ) = P ( a ∣ b ) P ( b ) P(a,b)=P(a|b)P(b) P(a,b)=P(a∣b)P(b) 可得
log P ( x ; θ ) = log P ( x , z ; θ ) P ( z ∣ x ; θ ) = log P ( x , z ; θ ) − log P ( z ∣ x ; θ ) = log P ( x , z ; θ ) Q ( z ) − log P ( z ∣ x ; θ ) Q ( z ) \begin{aligned} \log P(x;\theta) &=\log \frac{P(x,z;\theta)}{P(z|x;\theta)} \\ &=\log P(x,z;\theta)-\log P(z|x;\theta) \\ &= \log \frac{P(x,z;\theta)}{Q(z)}- \log\frac{P(z|x;\theta)}{Q(z)} \end{aligned} logP(x;θ)=logP(z∣x;θ)P(x,z;θ)=logP(x,z;θ)−logP(z∣x;θ)=logQ(z)P(x,z;θ)−logQ(z)P(z∣x;θ)
左右两边同时根据先验概率 Q ( z ) Q(z) Q(z)做期望可得
∑ z Q ( z ) log P ( x ; θ ) = ∑ z Q ( z ) log P ( x , z ; θ ) Q ( z ) − ∑ z Q ( z ) log P ( z ∣ x ; θ ) Q ( z ) \begin{aligned} \sum_z Q(z) \log P(x;\theta) &= \sum_z Q(z)\log \frac{P(x,z;\theta)}{Q(z)}- \sum_z Q(z)\log\frac{P(z|x;\theta)}{Q(z)} \end{aligned} z∑Q(z)logP(x;θ)=z∑Q(z)logQ(z)P(x,z;θ)−z∑Q(z)logQ(z)P(z∣x;θ)
左边因为 P ( x ; θ ) P(x;\theta) P(x;θ)与 z z z无关,因此结果还是 log P ( x ; θ ) \log P(x;\theta) logP(x;θ),右边的左部分实际上就是之前放缩后的结果,而右边的右部分实际上是KL散度。我们将上式写成带有上标的复杂的形式可以得到:
L ( θ ) = ∑ i = 1 m log P ( x ( i ) ; θ ) = ∑ i = 1 m ∑ z ( i ) Q ( z ( i ) ) log P ( x ( i ) , z ( i ) ; θ ) Q ( z ( i ) ) − ∑ i = 1 m ∑ z ( i ) Q ( z ( i ) ) log P ( z ( i ) ∣ x ( i ) ; θ ) Q ( z ( i ) ) = ∑ i = 1 m ∑ z ( i ) Q ( z ( i ) ) log P ( x ( i ) , z ( i ) ; θ ) Q ( z ( i ) ) + ∑ i = 1 m KL ( Q ( z ( i ) ) ∣ ∣ P ( z ( i ) ∣ x ( i ) ; θ ) ) \begin{aligned} L(\theta) &= \sum_{i=1}^m \log P(x^{(i)};\theta) \\ &=\sum_{i=1}^m \sum_{z^{(i)}} Q(z^{(i)})\log \frac{P(x^{(i)},z^{(i)};\theta)}{Q(z^{(i)})}- \sum_{i=1}^m \sum_{z^{(i)}} Q(z^{(i)})\log\frac{P(z^{(i)}|x^{(i)};\theta)}{Q(z^{(i)})} \\ &= \sum_{i=1}^m \sum_{z^{(i)}} Q(z^{(i)})\log \frac{P(x^{(i)},z^{(i)};\theta)}{Q(z^{(i)})} + \sum_{i=1}^m \text{KL}(Q(z^{(i)})||P(z^{(i)}|x^{(i)};\theta)) \end{aligned} L(θ)=i=1∑mlogP(x(i);θ)=i=1∑mz(i)∑Q(z(i))logQ(z(i))P(x(i),z(i);θ)−i=1∑mz(i)∑Q(z(i))logQ(z(i))P(z(i)∣x(i);θ)=i=1∑mz(i)∑Q(z(i))logQ(z(i))P(x(i),z(i);θ)+i=1∑mKL(Q(z(i))∣∣P(z(i)∣x(i);θ))
因此之前通过放缩得到的下界(常称为ELBO,Evidence Lower BOund)加上KL散度就是我们要最小化的似然函数,由于KL散度是非负的,因此确实符合。回顾EM算法,可以发现E步实际上就是让KL散度等于0,M步则是最大化ELBO。
VAE
之前讲到了在EM算法中我们直接令KL散度等于0,但是在实际中 P ( z ∣ x ) P(z|x) P(z∣x)一般是未知的,在参考文献[1]中用 “intractable” 来描述,我的理解就是难以计算的意思。
VAE(Variational Auto-Encoder,变分自编码器)就是一个编码-解码结构,用于学习数据集的分布。我们做如下假设:
- 编码器部分用于拟合 Q ( z ∣ x ) Q(z|x) Q(z∣x),也就是样本到隐空间的映射;解码器用于拟合 P ( x ∣ z ) P(x|z) P(x∣z),用于生成新的数据;
- Q ( z ∣ x ) Q(z|x) Q(z∣x)和 P ( x ∣ z ) P(x|z) P(x∣z)是高斯分布;
不论VAE如何,它始终是个概率模型,目标就是最小化似然函数,通俗一点来说就是使得数据集出现概率最大。我们沿用刚才EM算法中的推导(就省略参数了),即
log P ( x ) = ∑ z Q ( z ) log P ( x , z ) Q ( z ) + KL ( Q ( z ) ∣ ∣ P ( z ∣ x ) ) \begin{aligned} \log P(x) &= \sum_z Q(z)\log \frac{P(x,z)}{Q(z)}+ \text{KL}(Q(z)||P(z|x)) \end{aligned} logP(x)=z∑Q(z)logQ(z)P(x,z)+KL(Q(z)∣∣P(z∣x))
由于在推导过程中 Q ( z ) Q(z) Q(z)是我们引入的一个分布,因此不妨将它写作 Q ( z ∣ x ) Q(z|x) Q(z∣x)代入上式得到
log P ( x ) = ∑ z Q ( z ∣ x ) log P ( x , z ) Q ( z ∣ x ) + KL ( Q ( z ∣ x ) ∣ ∣ P ( z ∣ x ) ) = ∑ z Q ( z ∣ x ) log P ( x ∣ z ) + ∑ z Q ( z ∣ x ) log P ( z ) Q ( z ∣ x ) + KL ( Q ( z ∣ x ) ∣ ∣ P ( z ∣ x ) ) \begin{aligned} \log P(x) &= \sum_z Q(z|x)\log \frac{P(x,z)}{Q(z|x)}+ \text{KL}(Q(z|x)||P(z|x))\\ &= \sum_z Q(z|x)\log P(x|z)+\sum_z Q(z|x)\log \frac{P(z)}{Q(z|x)}+ \text{KL}(Q(z|x)||P(z|x)) \\ \end{aligned} logP(x)=z∑Q(z∣x)logQ(z∣x)P(x,z)+KL(Q(z∣x)∣∣P(z∣x))=z∑Q(z∣x)logP(x∣z)+z∑Q(z∣x)logQ(z∣x)P(z)+KL(Q(z∣x)∣∣P(z∣x))
实际上我们想要的是 P ( z ∣ x ) P(z|x) P(z∣x),也就是数据集的隐式概率分布,但之前也讲到过这个是不可计算的,因此VAE实际上是用 Q ( z ∣ x ) Q(z|x) Q(z∣x)去逼近 P ( z ∣ x ) P(z|x) P(z∣x),用EM算法的思想来看就是既然无法让KL散度等于0,那我们就让它尽可能小。现在就到了VAE的核心处理步骤,即最大化
ELBO = ∑ z Q ( z ∣ x ) log P ( x ∣ z ) + ∑ z Q ( z ∣ x ) log P ( z ) Q ( z ∣ x ) \text{ELBO}=\sum_z Q(z|x)\log P(x|z)+\sum_z Q(z|x)\log \frac{P(z)}{Q(z|x)} ELBO=z∑Q(z∣x)logP(x∣z)+z∑Q(z∣x)logQ(z∣x)P(z)
最大化ELBO的结果是什么呢?首先ELBO是似然函数的下界,我们最大化它实际上也是在最大化似然函数,就和EM算法一样;另外当我们最大化ELBO时,实际上是在让 KL ( Q ( z ∣ x ) ∣ ∣ P ( z ∣ x ) ) \text{KL}(Q(z|x)||P(z|x)) KL(Q(z∣x)∣∣P(z∣x))尽可能小,也就是说让编码器拟合的 Q ( z ∣ x ) Q(z|x) Q(z∣x)去逼近 P ( z ∣ x ) P(z|x) P(z∣x)。可以看出唯一与EM算法不同的就是我们无法直接让KL散度等于0而已。
至此,VAE的数学形式就很优美了:最大化ELBO,也就是最小化
− ELBO = − ∑ z Q ( z ∣ x ) log P ( x ∣ z ) + KL ( Q ( z ∣ x ) ∣ ∣ P ( z ) ) -\text{ELBO}=-\sum_z Q(z|x)\log P(x|z)+\text{KL}(Q(z|x)||P(z)) −ELBO=−z∑Q(z∣x)logP(x∣z)+KL(Q(z∣x)∣∣P(z))
我们看RHS的第一项: − ∑ z Q ( z ∣ x ) log P ( x ∣ z ) -\sum_z Q(z|x)\log P(x|z) −∑zQ(z∣x)logP(x∣z),将其称为重构损失。先上结论:
- 假如 P ( x ∣ z ) P(x|z) P(x∣z)服从伯01分布,那么重构损失就是交叉熵损失;
- 假如 P ( x ∣ z ) P(x|z) P(x∣z)服从正态分布,那么重构损失就是MSE(我们假设的就是这个);
至于为什么在这里是MSE呢?我在某个教授的课上得到的解释是:由于decoder部分是一个“确定的”函数,因此当考虑 P ( x ∣ z ) P(x|z) P(x∣z)时,实际上等价于考虑 P ( x ∣ x ^ ) P(x|\hat{x}) P(x∣x^),其中 x ^ = decoder ( z ) \hat{x}=\text{decoder}(z) x^=decoder(z),而由于是正态分布,因此 P ( x ∣ x ^ ) ∼ exp ( ∣ x − x ^ ∣ 2 ) P(x|\hat{x})\sim \exp(|x-\hat{x}|^2) P(x∣x^)∼exp(∣x−x^∣2),所以整个部分取对数后就正比于L2误差。然而我对于 z z z和 x ^ \hat{x} x^的替换还不是很明白,这一点我查了很多资料还是没弄懂。
再来看RHS的第二项: KL ( Q ( z ∣ x ) ∣ ∣ P ( z ) ) \text{KL}(Q(z|x)||P(z)) KL(Q(z∣x)∣∣P(z)),将其称为正则化损失。为了方便我们一般假设先验分布 P ( z ) ∼ N ( 0 , 1 ) P(z)\sim \mathcal{N}(0,1) P(z)∼N(0,1),而 Q ( z ∣ x ) ∼ N ( z ; μ , σ 2 ) Q(z|x)\sim\mathcal{N}(z;\mu,\sigma^2) Q(z∣x)∼N(z;μ,σ2), z z z的维度为 J J J,那么这个正则化损失就可以得到显式表示
KL ( Q ( z ∣ x ) ∣ ∣ P ( z ) ) = − 1 2 ∑ j = 1 J ( 1 + log ( σ j 2 ) − μ j 2 − σ j 2 ) \text{KL}(Q(z|x)||P(z))=-\frac{1}{2}\sum_{j=1}^{J}(1+\log(\sigma_j^2)-\mu_j^2-\sigma_j^2) KL(Q(z∣x)∣∣P(z))=−21j=1∑J(1+log(σj2)−μj2−σj2)
最后一个是采样不可导的问题,这可以用“重采样”的方式来解决。参考文献[2]的这张图清晰地说明了该方式:
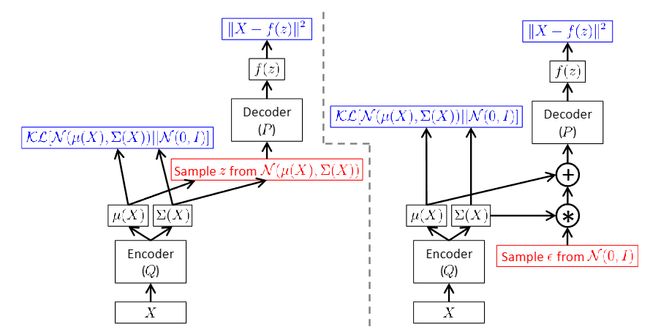
也就是在标准正态分布上随机采样,然后将Encoder的输出和随机采样结果做运算,这样能得到等价的在 Q ( z ∣ x ) ∼ N ( z ; μ , σ 2 ) Q(z|x)\sim\mathcal{N}(z;\mu,\sigma^2) Q(z∣x)∼N(z;μ,σ2)上随机采样的值。
所以使用VAE其实很简单,只需要Encoder部分输出 μ \mu μ和 log ( σ 2 ) \log(\sigma^2) log(σ2)(最后一个网络层复制为并行2个),然后在标准正态分布上随机采样 ϵ \epsilon ϵ,然后计算 z = σ × ϵ + μ z=\sigma\times\epsilon+\mu z=σ×ϵ+μ,然后Decoder部分输出 x ^ \hat{x} x^,然后合理的平衡两个Loss进行学习就可以了。
参考文献
[1] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
[2] Doersch, Carl. “Tutorial on variational autoencoders.” arXiv preprint arXiv:1606.05908 (2016).