Word2Vec的CBOW模型
Word2Vec中的CBOW(Continuous Bag of Words)模型是一种用于学习词向量的神经网络模型。CBOW的核心思想是根据上下文中的周围单词来预测目标单词。
例如,对于句子“The cat climbed up the tree”,如果窗口大小为5,那么当中心单词为“climbed”时,上下文单词为“The”、“cat”、“up”和“the”。CBOW模型要求根据这四个上下文单词,计算出“climbed”的概率分布。
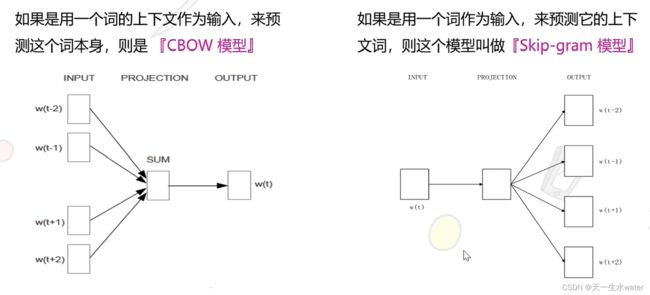

一个简单的CBOW模型
import torch
import torch.nn as nn
import torch.optim as optim
# 定义CBOW模型
class CBOWModel(nn.Module):
def __init__(self, vocab_size, embed_size):
super(CBOWModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_size)
self.linear = nn.Linear(embed_size, vocab_size)
def forward(self, context):
embedded = self.embeddings(context)
embedded_sum = torch.sum(embedded, dim=1)
output = self.linear(embedded_sum)
return output
# 定义训练函数
def train_cbow(data, target, model, criterion, optimizer):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
return loss.item()
# 假设有一个简单的语料库和单词到索引的映射
corpus = ["I like deep learning", "I enjoy NLP", "I love PyTorch"]
word_to_index = {"I": 0, "like": 1, "deep": 2, "learning": 3, "enjoy": 4, "NLP": 5, "love": 6, "PyTorch": 7}
# 将语料库转换为训练数据
context_size = 3
data = []
target = []
for sentence in corpus:
tokens = sentence.split()
for i in range(context_size, len(tokens) - context_size):
context = [word_to_index[tokens[j]] for j in range(i - context_size, i + context_size + 1) if j != i]
target_word = word_to_index[tokens[i]]
data.append(torch.tensor(context, dtype=torch.long))
target.append(torch.tensor(target_word, dtype=torch.long))
# 超参数
vocab_size = len(word_to_index)
embed_size = 10
learning_rate = 0.01
epochs = 100
# 初始化模型、损失函数和优化器
cbow_model = CBOWModel(vocab_size, embed_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(cbow_model.parameters(), lr=learning_rate)
# 开始训练
for epoch in range(epochs):
total_loss = 0
for i in range(len(data)):
loss = train_cbow(data[i], target[i], cbow_model, criterion, optimizer)
total_loss += loss
print(f'Epoch {epoch + 1}/{epochs}, Loss: {total_loss}')
# 获取词向量
word_embeddings = cbow_model.embeddings.weight.detach().numpy()
print("Word Embeddings:\n", word_embeddings)
-
CBOW模型定义(class CBOWModel):
__init__方法:在初始化过程中定义了两个层,一个是nn.Embedding用于获取词向量,另一个是nn.Linear用于将词向量求和后映射到词汇表大小的空间。forward方法:定义了模型的前向传播过程。给定一个上下文,首先通过Embedding层获取词向量,然后对词向量进行求和,最后通过Linear层进行映射。
-
训练函数(train_cbow):
train_cbow函数用于训练CBOW模型。接受训练数据、目标、模型、损失函数和优化器作为输入,并执行前向传播、计算损失、反向传播和优化器更新权重的过程。
-
语料库和单词到索引的映射:
corpus包含了三个简单的句子。word_to_index是单词到索引的映射。
-
将语料库转换为训练数据:
- 对每个句子进行分词,然后构建上下文和目标。上下文是目标词的上下文词的索引列表,目标是目标词的索引。
-
超参数和模型初始化:
vocab_size是词汇表大小。embed_size是词向量的维度。learning_rate是优化器的学习率。epochs是训练迭代次数。CBOWModel实例化为cbow_model。- 使用交叉熵损失函数和随机梯度下降(SGD)优化器。
-
训练过程:
- 使用嵌套的循环对训练数据进行多次迭代。
- 对每个训练样本调用
train_cbow函数,计算损失并更新模型权重。
-
获取词向量:
- 通过
cbow_model.embeddings.weight获取训练后的词向量矩阵,并将其转换为 NumPy 数组。
- 通过
需要注意的是,代码中的训练过程比较简单,通常在实际应用中可能需要更复杂的数据集、更大的模型和更多的训练策略。此处的代码主要用于展示CBOW模型的基本实现。
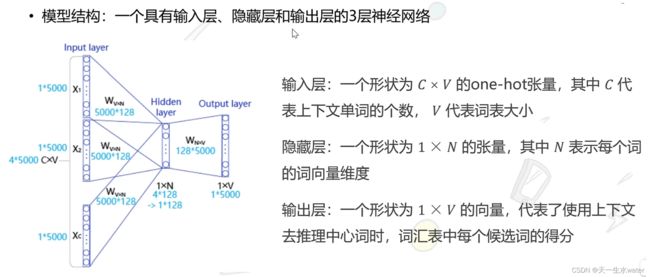
在CBOW(Continuous Bag of Words)模型中,神经网络的输入和输出数据的构造方式如下:
-
输入数据:
- 对于每个训练样本,输入数据是上下文窗口内的单词的独热编码(one-hot encoding)向量的拼接。
- 上下文窗口大小为3,因此对于每个目标词,上下文窗口内有3个单词。这3个单词的独热编码向量会被拼接在一起作为输入。
- 对于语料库中的每个目标词,都会生成一个对应的训练样本。
以 "I like deep learning" 为例:
- "deep" 是目标词,上下文窗口为["like", "I", "learning"]。
- 对应的独热编码向量分别是 [0, 1, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0]。
- 这三个向量拼接在一起作为神经网络的输入。
对于整个语料库,这个过程会生成一组输入数据。
-
输出数据:
- 输出数据是目标词的独热编码向量,表示模型要预测的词。
- 对于 "I like deep learning" 中的 "deep",其对应的独热编码向量是 [0, 0, 0, 1, 0, 0, 0, 0]。
- 整个语料库中,为每个目标词生成相应的输出数据。
综上所述,CBOW模型的神经网络输入数据是上下文窗口内单词的拼接独热编码向量,输出数据是目标词的独热编码向量。在训练过程中,模型通过学习输入与输出之间的映射关系,逐渐调整权重以更好地捕捉语境信息。