《FITNETS: HINTS FOR THIN DEEP NETS》论文整理
目录
零、前言
一、Fitnet的目的及适用范围
1、目的:
2、适用范围:
3、背景及创新点:
二、Hint-Based Training思想
1、hint层与guided层:
2、核心思想:
三、Fitnet训练过程及效果
1、FItnet训练过程可以分为三个阶段:
2、需要注意的问题:
3、具体流程:
4、损失函数:
(1)预训练阶段:
(2)知识蒸馏阶段:
5、训练效果:
四、Q&A
1、小模型模仿大模型中间层的输出feature map的大小还是内容?
2、为什么小模型模仿大模型hint层及其之前的feature map可以提高训练效果?
文章传送门:[1412.6550] FitNets: Hints for Thin Deep Nets (arxiv.org)
零、前言

Hinton老爷子2014年凭借着一篇《Distilling the Knowledge in a Neural Network》开创了知识蒸馏领域的先河之后,另一位大牛Bengio便开始马不停蹄的加入了知识蒸馏的研究之中。他首次提出通过中间层学习knowledge,提出了Hint-Based Training的思想。
在当时resnet、MRSA初始化、BN算法还未提出的年代,深层网络往往训练效果不好,而Hint-Based Training的提出利用了知识蒸馏有效训练了更深的神经网络,在参数比大模型更少的情况下利用了深度的优势达到的准确率甚至超过大模型。
一、Fitnet的目的及适用范围
1、目的:
利用基于feature的知识将宽而较浅的大网络压缩(知识蒸馏)为窄而较深的小网络,且有不错的表现
2、适用范围:
小模型比大模型深且窄,示意图如下
深:蒸馏得到的小模型的层数比大模型多
窄:小模型卷积层的面积比大模型小
3、背景及创新点:
2015年当时残差神经网络还未出现,深层次网络虽然效果好但是难以训练(容易过拟合),本文利用知识蒸馏高效训练深层模型,提出在知识蒸馏时第一阶段让更深的小模型模仿大模型卷积层的输出进行预训练(基于featrue的知识),在第二阶段进行正常的知识蒸馏(基于响应的知识)的方法,在保证深层模型效果的同时压缩模型
二、Hint-Based Training思想
要想搞明白什么是Hint-Based Training,就需要先定义Hint和Guided。
1、hint层与guided层:
(1)hint层:大模型的某一个选定的隐藏层
(2)hint:大模型hint层及其之前层的输出
(3)guided层:从小模型的某一个选定的隐藏层 我们在训练的第二阶段希望guided层能预测与hint层相近的输出
2、核心思想:
拓宽了知识的定义,知识不仅仅是大模型输入到输出的响应,也隐含在一些中间层的表达上
三、Fitnet训练过程及效果
1、FItnet训练过程可以分为三个阶段:
大模型训练、小模型预训练、小模型知识蒸馏
(1)大模型训练: 同第一篇,用真实标签训练好大模型;随机初始化小模型
(2)小模型预训练: 用教师的hint来预训练学生的guided layer及之前的层,使guided layer及其之前的层的输出与hint及其之前的层的输出相同。
(3)小模型知识蒸馏: 使用经典的基于响应的知识整理对小模型继续训练
2、需要注意的问题:
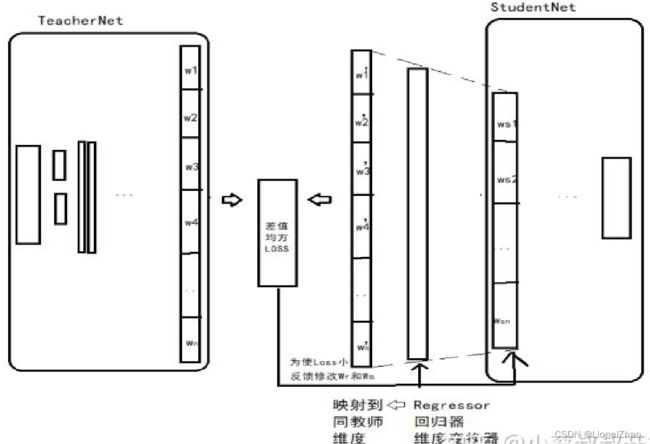
(1)要让小模型的guided层的输出学习大模型hint层的输出,由于卷积层大小不同,两者输出feature map大小不同(guided输出比hint大),因此需要再经过卷积保证guided层与hint层输出大小一致。
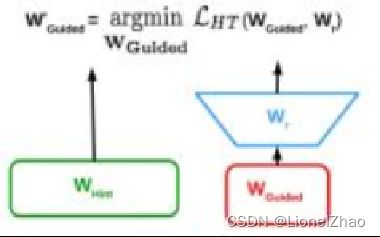
(2)hint来进行引导是一种正则化手段,学生guided层越深,那么正则化作用就越明显,为了避免过度正则化,需要仔细选择hint和guided层。
3、具体流程:
具体训练流程如图所示:

(1)大模型训练,小模型随机初始化
(2)将大模型特征提取器的第H层作为hint,从第一层到第H层的参数对应图(a)中的![]() ,选择小模型特征提取器的第G层作为guided,从第一层到第G层对应图(a)中
,选择小模型特征提取器的第G层作为guided,从第一层到第G层对应图(a)中![]() ;
;
(3)两者feature map大小可能不匹配,引入卷积层调整器(Wr)对guided层进行调整,对应图(b);
(4)优化均方损失函数
(5)对预训练好的小模型进行进一步知识蒸馏,对应图(c)

4、损失函数:
(1)预训练阶段:
Teacher网络的某一中间层的权值为Wt=Whint,Student网络的某一中间层的权值为Ws=Wguided。使用一个映射函数Wr来使得Wguided的维度匹配Whint,得到Ws。其中对于Wr的训练使用均方误差损失函数MSEloss:

uh和vg是教师/学生的深度嵌套函数,直到他们各自的提示/引导层,带有参数WHint和WGuided,r是引导层顶部带有参数Wr的回归函数。请注意,这个和r的输出必须是可比的,即这个和r必须是相同的非线性。
(2)知识蒸馏阶段:
同上篇一样的交叉熵损失函数:
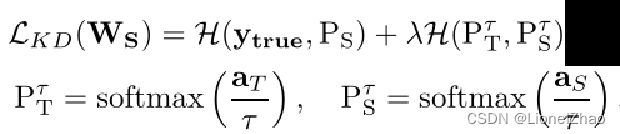
5、训练效果:
细节大家自己看论文吧我实在是懒。

四、Q&A
1、小模型模仿大模型中间层的输出feature map的大小还是内容?
小模型的guided及其之前的层经过Wr卷积层之后的结果去模仿大模型hint及其之前的层的feature map 两者feature map大小可能不匹配,引入卷积层调整器(Wr)对guided层进行调整,对应图(b);

Hint-Based Training所做的一切努力就是为了 使小模型guided层的feature map在经过Wr回归矩阵之后的内容与大模型hint层的feature map匹配,是大小和内容都模仿。
2、为什么小模型模仿大模型hint层及其之前的feature map可以提高训练效果?
fitnets模型提高了网络性能的影响因素之一:网络的深度
网络越深,非线性表达能力越强,可以学习更复杂的变换,从而可以拟合更复杂的特征,更深的网络可以更容易的学习复杂特征。
fitnets是深而窄的网络模型,在当时resnet、MRSA初始化、BN算法还未提出的情况下深层网络往往训练效果不好,而Hint-Based Training的提出利用了知识蒸馏有效训练了更深的神经网络,在参数比大模型更少的情况下利用了深度的优势达到的准确率甚至超过大模型。