基于Python的线上书籍推荐系统的设计与实现
摘 要
本系统旨在打造将传统的书籍分类和最热书籍转型升级为依靠基于用户和物品的协同过滤推荐算法达到个性化书籍的推荐系统,毕业论文参考目前的豆瓣系统,开发出多类多样、个性化、高效率、功能性强以及更适合用户的在线书籍推荐系统。
该系统采用Python程序应用开发平台Pycharm技术平台,运用三层架构以及MTV的开发模式,利用Mysql作为服务器数据库,应用了Tomcat,Python、Web、Html、Ajax、JQuery等技术实现了基于用户的协同过滤的书籍推荐,并利用python web实现系统可视化,为用户提供书籍评分功能,更针对不同用户,做出个性化的书籍推荐。
本系统以用户为基础,根据用户的浏览记录、收藏记录、评分记录等以基于邻域的协调过滤算法实现“猜你喜欢”的功能;基于用户的信息、用户选的书籍等以基于物品的协调过滤算法实现“为你推荐”的功能。实现毕业论文将参考目前单一分类、推荐大众化、效率低、功能薄弱的线上书籍推荐系统平台,开发出更适合用户的个性化在线书籍推荐系统。
关键词:书籍推荐;协调过滤;Python;Pycharm技术平台
ABSTRACT
This system aims to create a traditional book classification and the hottest book transformation and upgrading into a recommendation system that relies on the collaborative filter recommendation algorithm based on users and items to achieve personalized books, and the graduation thesis refers to the current Douban system to develop a multi-variety, personalized, efficient, functional and more suitable online book recommendation system.
The system adopts Python program application development platform Pycharm technology platform, the use of three-layer architecture and MTV development mode, the use of Mysql as a server database, the application of Tomcat, Python, Web, Html, Ajax, JQuery and other technologies to achieve user-based collaborative filtering of book recommendations, and the use of Python web to achieve system visualization, to provide users with book scoring function, more for different users, Make personalized book recommendations.
The system is based on the user, according to the user's browsing records, collection records, scoring records, etc. to achieve the function of "guess what you like" based on the neighborhood-based coordinated filtering algorithm; based on the user's information, the user's selected books, etc. to achieve the "recommended for you" function based on the item-based coordinated filtering algorithm. The graduation thesis will refer to the current online book recommendation system platform with single classification, popularization of recommendation, low efficiency and weak functions, and develop a personalized online book recommendation system that is more suitable for users.
KEYWORDS: Book recommendations; coordinated filtering; Python; Pycharm technology platform
目 录
诚信声明
摘 要
ABSTRACT
1绪论
1.1 研究背景与意义
1.1.1 研究背景
1.1.2 研究意义
1.2 国内外研究现状
1.2.1 国外研究现状
1.2.2 国内研究现状
1.2.3 研究现状评述
1.3 主要研究内容
1.4 本章小结
2相关技术介绍
2.1 Python程序应用开发平台Pycharm简介
2.2 Django框架简介
2.3 MySQL数据库简介
2.4 基于邻域的算法简介
2.5 本章小结
3系统需求分析
3.1 可行性分析
3.2 功能需求分析
3.2.1登录注册需求分析
3.2.2常规书籍推荐需求分析
3.2.3个性化书籍推荐需求分析
3.3 非功能需求分析
3.4 本章小结
4系统设计
4.1 系统功能模块设计
4.2 系统流程图设计
4.2.1 注册登录流程
4.2.2 常规书籍推荐流程
4.2.3 个性化书籍推荐流程
4.2.4 书籍评论点赞流程
4.2.5 书籍评分流程
4.2.6 前台个人信息修改流程
4.2.7 管理书籍信息流程
4.2.8 管理书籍评分流程
4.2.9 管理书籍评论流程
4.2.10 管理用户信息流程
4.2.11 权限管理流程
4.3 数据库设计
4.3.1 数据库概念设计
4.3.2 数据库逻辑设计
4.4 本章小结
5系统实现
5.1 注册登陆实现
5.1.1 系统注册
5.1.2 系统登陆
5.2 系统首页
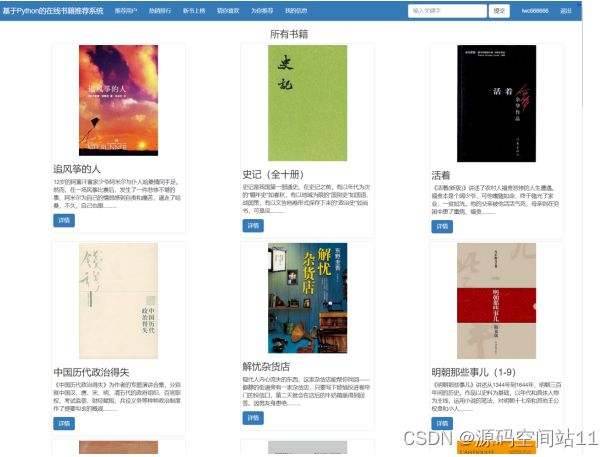
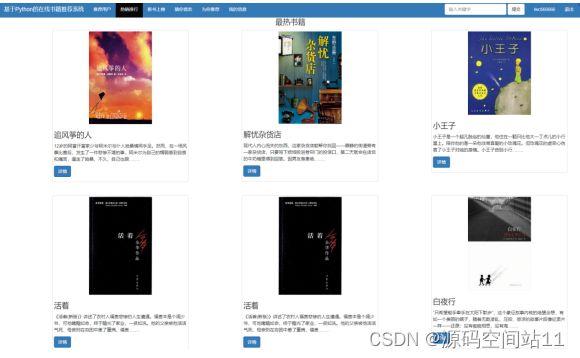
5.3 常规书籍推荐模块
5.3.1 热销排行
5.3.2 新书推荐排行
5.4 个性化书籍推荐模块
5.4.1推荐用户
5.4.2 基于用户的书籍推荐
5.4.3 基于物品图书的书籍推荐
5.5 书籍评分收藏模块
5.6 书籍评论点赞模块
5.5 前台个人信息修改模块
5.7 管理书籍信息模块
5.8 管理用户信息模块
5.9 管理书籍评分模块
5.10 管理书籍评论模块
5.11 权限管理模块
5.12 本章小结
6系统测试
6.1 测试目的
6.2 功能测试
6.2.1 注册功能测试
6.2.2 登录功能测试
6.2.3 搜索查询测试
6.2.4 常规书籍推荐功能测试
6.2.5 个性化书籍推荐功能测试
6.2.6 书籍评分功能测试
6.2.7 书籍评论功能测试
6.2.8 前台个人信息修改功能测试
6.2.9 管理书籍信息功能测试
6.2.10 管理用户信息功能测试
6.2.11 管理评分信息功能测试
6.2.12 管理评论信息功能测试
6.2.13 管理权限功能测试
6.3 性能测试
6.4 本章小结
7总结与展望
参考文献
致谢
1绪论
1.1 研究背景与意义
1.1.1 研究背景
互联网的出现和普及给用户带来了大量的信息,满足了用户在信息时代对信息的需求,但随着网络的迅速发展而带来的网上信息量的大幅增长,使得用户在面对大量信息时无法从中获得对自己真正有用的那部分信息,对信息的使用效率反而降低了,这就是所谓的信息超载(informationoverload)问题。
解决信息超载问题一个非常有潜力的办法是推荐系统,它是根据用户的信息需求、兴趣等,将用户感兴趣的信息、产品等推荐给用户的个性化信息推荐系统。和搜索引擎相比推荐系统通过研究用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点,从而引导用户发现自己的信息需求。一个好的推荐系统不仅能为用户提供个性化的服务,还能和用户之间建立密切关系,让用户对推荐产生依赖。因此,越来越多的物品提供者开始关注推荐系统,通过分析用户的历史行为信息发现用户的兴趣偏好,主动给用户推荐能够满足他们需求的物品。我们已经感受到推荐系统在我们生活方方面面广泛的应用,如京东、淘宝对商品的推荐,网易、酷我对音乐的推荐,豆瓣、优酷对电影的推荐。
目前的线上书籍系统绝大多数与传统线下书店相似,第一是将书籍分门别类,按种类划分书籍,用户根据自己喜欢的类型去寻找书籍;第二是根据用户阅读数量类似于线下书店设立畅销书专栏,线上书籍系统设立最热书籍模块,让用户从群众的眼光选择他们所都爱看的书籍;第三是线上书籍推荐系统采用评分制,例如豆瓣书籍评分等,根据评分判断书籍品质是否好的标准。虽然现今的线上书籍推荐系统已较传统书店更加方便了用户对书籍的选择,但还是存在着一些问题。首先,将书籍分门别类,用户并不一定知道自己喜欢看哪个类型的书籍,或者用户很多类型的书籍都看,那么用户还是不能去快速的选择想要的类型并找到需要的书籍;其次根据用户阅读数来选择书籍,并非每个用户都喜欢大众的眼光,部分用户偏爱小众文学或专业性的书籍,这些书籍用户喜欢但并不是群众都喜欢去阅读;最后通过查看线上书籍的评分来判断书籍的质量并非是一定准确的,在书籍评分数量少阅读人数不多时,书籍的评分并不能让用户对书籍的质量做出合理的判断。故目前的线上书籍推荐系统并不能满足用户个性化的书籍推荐。
针对目前现有的线上书籍系统,我将采用基于Python的协同过滤推荐算法设计线上书籍推荐系统,为用户个性化的推荐书籍。推荐系统在我们的生活中扮演着不可或缺的作用,推荐算法作为推荐系统的核心,一直备受关注。在过去的时间里,推荐算法的研究已经取得了很大成果,到今天推荐算法的发展仍然持续火热,因为其有着丰富的研究内容广泛的应用场景。ACM推荐系统会议RecSys作为信息推荐系统最重要的会议之一,从2007年开始,与NIPS、ICM等会议提供了一个展现推荐系统最新研究成果的平台。Netflix公司公布了的电影打分数据集,为推荐系统在影视推荐研究上提供了基础。推荐系统的发展从简单的相似度计算到今天的矩阵分解方法,基于Python的线上书籍推荐系统运用协同过滤算法建立更先进的推荐模型、采用更好地方式提取用户行为特征等方式提高书籍推荐系统的精度及广域性。运用协同过滤推荐算法的个性化推荐系统给用户带来了私人定制般的服务体验,能有效地增强用户粘度,避免用户流失。
1.1.2 研究意义
基于Python的线上书籍推荐系统的设计与实现,主要有以下几个方面的研究意义:(1) 线上书籍推荐系统给用户一个在线选择书籍的平台,通过查看书籍详情选择合适的书籍。(2)线上书籍推荐系统将书籍分为不同类型,以及根据用户的阅读数和用户的评分,对用户采用不同的书籍展示,方便用户根据类型、评分以及阅读人数选择感兴趣且质量更高的书籍。(3)充分关注用户的个性化需求,根据用户以往的书籍阅读偏好,在此基础上进行了个性化计算,将符合用户喜好的书籍呈现给用户;线上书籍推荐系统给用户个性化的推荐用户最想要的书籍,给用户最高效最贴心最合适的服务,大大提高了用户的体验。
1.2 国内外研究现状
1.2.1 国外研究现状
国外最成熟的在线书籍系统是亚马逊,亚马逊上使用逐项协同过滤的方法向客户推荐书籍。他们讨论了基于用户项目的协同过滤方法的局限性,这可能是棘手的,并受制于冷启动问题。一个好的书籍推荐系统,一定是基于个性化推荐的。
所谓“无数据,不个性”,个性化推荐系统强度依赖用户行为数据,通过分析大量用户行为日志的方式,达到给不同用户提供不同个性化信息的目的。无论是电子商务、电影、社交 网络、阅读、基于位置的服务,还是广告领域,都无一例外地包含着“展示页面”、“后台日志系统”、“推荐算法系统”三个构成部分。
亚马逊的个性化推荐主要通过“个性化推荐列表”得以实现。它由“推荐结果”“结果评分”“推荐理由”三个模块组成。其中,“推荐结果”,由标题、图片、相关内容属性组成,用以概述产品的基本情况;“结果评分”,基于大部分用户对该图书的打分,用以评估该图书的总体质量;“推荐理由”,浓缩了用户正向的历史行为与该图书千丝万缕的联系,很可能过去的你,对相似图书或同类图书曾表示过喜欢的倾向,为得到用户确切的偏好数据,亚马逊还在图书后面专门设置了“Fix this recommendation(修正这一推荐)”按钮,并附带了包括Add to Cart(加入到购物车)、Add to Wish List(加入到心愿单)、Rate this item(给书打分)、I own it(我已经有这本书了)和Not interested(对这本书没兴趣)等在内的五种修正方式。甚至在“推荐理由”最下端的“推荐原因”设置也是非常人性化的,借以让读者进一步看清其推荐的确切由来。
亚马逊的书籍推荐系统,一方面采用了“基于物品”的推荐算法,即为用户推荐那些相似于他们过去所喜欢过的书籍;另一方面采用了“基于好友”的推荐算法,即为用户推荐其Facebook好友所喜欢过的东西和书籍。
最后,一个好的推荐系统,也是一个相关推荐系统。这得益于亚马逊的“相关推荐列表”功能。在用户购买书籍的时候,通过告诉用户其他用户在购买该书籍时也会购买的其他几个书籍的方式,以达到打包营销目的。亚马逊的这一“打包销售”手段,堪称推荐算法的最重要应用,并被推而广之地内化为电子商务网站的标准应用。“购买了这本书籍的用户也经常购买的其他书籍”和“含浏览过这个书籍的用户经常购买的其他书籍”构成了“相关推荐列表”的两种方式。
亚马逊通过其成熟的推荐系统,给予每个进入网站的浏览者以不同的个性化体验,从而把一个庞大的图书帝国,拆分成一个个“精而美”的个人书店。
1.2.2 国内研究现状
目前国内书籍推荐系统渐渐运用了推荐算法,各大高校对于推荐算法在学生课程属性与兴趣偏好中的相关问题进行了较为深入的研究。王仲钰利用多维属性间关联规则数据挖掘技术,采用协同过滤算法、关联算法对不同用户群体书籍购买或阅读进行分析,探索具有针对性的书籍推荐服务策略,提升在线书籍服务能力。王刚计算用户之间的相似性并与传统的协同过滤推荐方法相结合,提出了基于用户兴趣序列的改进协同过滤书籍推荐方法。李萍通过实验测试,采用数据挖掘技术的书籍推荐系统推荐的书目与实际阅读或购买的书目基本吻合,判断准确性对比传统方式大幅提高。张紫嫣也提出一种结合类别偏好的协同过滤推荐算法。在原算法计算用户相似度的基础上,结合用户类别偏好的相似度来计算近邻,从而得到推荐结果。现有的国内研究中重点考虑在对协同过滤数据的关联规则研究上,而对挖掘学生的兴趣倾向值矩阵建立研究较少。个性化书籍推荐系统在20世纪90年代推出后,各界学者对其进行了系统、深入的研究,取得了丰硕的成果。它有效地解决了用户在海量书籍中,难以高效地找到自己需要的书籍的问题。如今,常见的书籍推荐系统由三种方式为用户推荐书籍,分别为基于用户的协同过滤书籍推荐、基于内容的书籍推荐和书籍混合推荐。
由于单一的推荐方式存在一些固有缺陷,因此,可以通过一定的方式将协同过滤和基于内容的推荐技术结合起来,优势互补,实现更加精准的书籍推荐效果。通过LDA算法根据书籍主题进行聚类,将用户更感兴趣的书籍主题挑选出来,综合使用协同过滤和基于内容的推荐算法,推荐精确度更高。随着个性化推荐系统的不断完善和发展,各大厂商纷纷将其应用到社交、购物、电子商务等领域,取得了良好的效益。
国内较早接入个性化推荐系统的书籍在线网站,可以向用户推荐用户可能喜欢的书籍,提高了用户粘性。它在用户浏览过相关内容后,会让其进行评价,从而获取到评分信息并进行针对性的推荐。这种方式需要用户的主动参与,体验较差。豆瓣网的豆瓣读书在呈现书籍信息时同样采用了个性化推荐算法。它通过个性化书籍定制的设置界面,根据用户以往浏览的记录、操作点击记录、收藏或关注列表等个人上网记录信息,以向你推荐、展示或推送你可能更感兴趣的书籍。
1.2.3 研究现状评述
在线书籍推荐系统的发展初期,对用户分析,是基于书籍的流行度对用户进行推荐。流行度的衡量是依靠书籍的购买或阅读次数、或者点击率。但是简单的将最流行的书籍推荐给用户,每位用户收到的都是相同的推荐。这样的算法并没有针对不一样的用户进行个性化推荐,而且推荐书籍的多样性差。在上个世纪 90 年代,协同过滤算法被提出,其核心是基于用户的历史行为数据进行推荐。该算法可以分为两类,一类是基于用户的协同过滤,即通过计算用户相似度,为用户推荐有相同兴趣的用户购买过或阅读过的书籍,本质是寻找用户得最近邻,该算法适用于用户较少的场合。另一类是基于物品的协同过滤,即通过计算物品的相似度,为用户推荐有过历史阅读行为的同类书籍,本质是寻找书籍的最近邻。协同过滤算法[3]不可避免的会出现两个问题:评分矩阵稀疏导致的推荐性能不佳及冷启动问题。为了解决这两个问题人们将物品或用户的信息纳入推荐算法中。
1.3 主要研究内容
本课题研究大学课程过程考核系统,实现大学课程过程性考核管理。在现有课程过程考核体系的基础上,完善了课程过程考核体系的基本功能。同时结合智慧教学软件的平时课堂表现数据,对学生的课程表现进行统计分析,主要研究内容如下:
- 研究分析了现有课程过程性考核系统的优缺点,确定本系统要解决的问题,对信息化平台中的过程性考核提出一个具体的解决思路。
- 研究分析系统实现过程中会遇到的问题,从系统需求分析中找到解决方案,通过功能需求分析设计系统功能模块,并设计系统功能模块的详细流程图。
- 研究分析系统总体功能,根据模块之间的功能,拆分出一个个实体,绘制E-R图,建立数据库的这题架构。
- 研究分析系统的基本功能功能,设计出关键功能流程图,对系统各功能模块进行设计和实现,对主要功能进行系统测试,并记录和解决测试过程中的问题,从而确保系统的最终完成。