轻量检测模型NonoDet-Plus解析
官方解读:超简单辅助模块加速训练收敛,精度大幅提升!移动端实时的NanoDet升级版NanoDet-Plus来了! - 知乎
official implementation:https://github.com/RangiLyu/nanodet
Backbone
backbone部分没有变化,还是和nanodet一样,采用ShuffleNet v2。
Neck
和nanodet相比,neck部分的改进包括三个部分
- 借鉴GhostNet,设计了Ghost-PAN
- 输出增加了一层P6
- 下采样由nanodet中的插值改成5x5的深度可分离卷积
具体来说,nanodet中不同层级的特征通过上、下采样对齐尺度后,通过add的方式进行融合。在nanodet-plus中首先进行concatenate,然后经过一个GhostBlock的处理进行融合。
inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
torch.cat([upsample_feat, feat_low], 1)
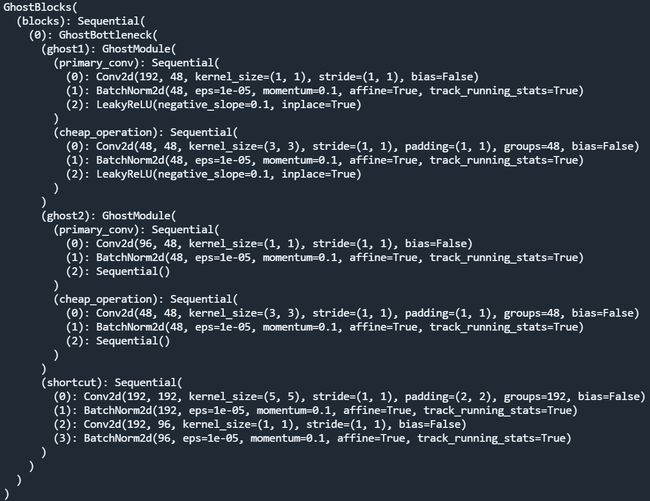
)其中GhostBlock由若干个GhostBottleneck构成,这里为1个。GhostBottleneck又由2个GhostModule构成,关于GhostNet的具体介绍见GhostNet(CVPR 2020) 原理与代码解析。GhostBlock的具体结构如下,其中全是stride=1的bottleneck,没有使用se通道注意力,shortcut中的深度卷积核由3x3改成5x5
PicoDet在nanodet的三层特征上又下采样增加了一层特征,这里也一样neck的输出额外增加了一层P6。
# extra layers
for extra_in_layer, extra_out_layer in zip(
self.extra_lvl_in_conv, self.extra_lvl_out_conv
):
outs.append(extra_in_layer(inputs[-1]) + extra_out_layer(outs[-1]))这里extra_in_layer和extra_out_layer都是5x5的深度可分离卷积,如下

Head
head部分原本的3x3的卷积改成了5x5的深度可分离卷积,其它没有变化。
Label Assignment
在nanodet中采用的是静态标签分配策略ATSS,这里作者想要改成动态分配策略,动态分配策略需要根据模型的输出计算cost matrix,然后再进行正负样本的分配。模型的预测越准,标签分配的结果也会越好,但在nanodet中采用了轻量的检测头,比起FCOS检测头中分类、回归两个分支,每个分支都包含4个256通道的3x3卷积,nanodet检测头中只有2个192通道的3x3卷积同时预测分类和回归,预测的精度可能会下降,这反过来又会影响标签分配的结果。
为了解决这个问题,作者设计了一个训练辅助模块Assign Guidance Module(AGM),这里借鉴了《LAD:Improving Object Detection by Label Assignment Distillation》这篇文章,其中用教师模型的预测去引导学生模型的标签分配,但是蒸馏需要实现训练好一个教师模型比较耗费资源。这里AGM结构就和FCOS的检测头一样,不同尺度特征共享检测头,检测头内分为分类、回归两个分支,每个分支包含4个3x3卷积和一个输出卷积。相比于蒸馏,这里耗费的资源更少,且只在训练时使用,推理时丢弃,不会增加推理时间。
具体实现如下,其中的aux_head就是AGM,这里作者还增加了一个aux_fpn,aux_fpn和原始的neck结构是一样的,原始neck的输出和aux_fpn的输出concat一起作为aux_head的输入。其中detach_epoch=10,即只在前10个epoch中aux_fpn和aux_head的梯度会反向传播,10个epoch后梯度就不回流了。
class NanoDetPlus(OneStageDetector):
def __init__(
self,
backbone,
fpn,
aux_head,
head,
detach_epoch=0,
):
super(NanoDetPlus, self).__init__(
backbone_cfg=backbone, fpn_cfg=fpn, head_cfg=head
)
self.aux_fpn = copy.deepcopy(self.fpn)
self.aux_head = build_head(aux_head)
self.detach_epoch = detach_epoch
def forward_train(self, gt_meta):
img = gt_meta["img"]
feat = self.backbone(img)
fpn_feat = self.fpn(feat)
if self.epoch >= self.detach_epoch:
aux_fpn_feat = self.aux_fpn([f.detach() for f in feat])
dual_fpn_feat = (
torch.cat([f.detach(), aux_f], dim=1)
for f, aux_f in zip(fpn_feat, aux_fpn_feat)
)
else:
aux_fpn_feat = self.aux_fpn(feat)
dual_fpn_feat = (
torch.cat([f, aux_f], dim=1) for f, aux_f in zip(fpn_feat, aux_fpn_feat)
)
head_out = self.head(fpn_feat)
aux_head_out = self.aux_head(dual_fpn_feat)
loss, loss_states = self.head.loss(head_out, gt_meta, aux_preds=aux_head_out)
return head_out, loss, loss_states在训练过程中只用aux_head输出计算cost matrix,在推理时,采用自身的head计算cost matrix。cost由三部分组成,分类cost、回归cost、距离cost

在nanodet中加入动态分配策略Dynamic Soft Label Assign(DSLA)和辅助模块AGM,提升如下

Loss
loss部分和nanodet一样,采用的是GIoU Loss + Generalized Focal Loss。
Training Strategy
改进如下
- 优化器由SGD+momentum改成ADdamW
- 学习率策略由MultiStepLr改成CosineAnnealingLR
- 加入梯度裁剪
- 加入EMA