代码随想录算法训练营第一天|704. 二分查找、27. 移除元素
LeetCode.704 二分查找
题目链接:704. 二分查找 - 力扣(LeetCode)
视频链接:二分查找法
文章链接:我写了首诗,让你闭着眼睛也能写对二分搜索 | labuladong 的算法笔记
代码随想录 (programmercarl.com)
相关练习:35. 搜索插入位置 - 力扣(LeetCode)
34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode)
69. x 的平方根 - 力扣(LeetCode)
367. 有效的完全平方数 - 力扣(LeetCode)

思路: 首先看到这个题目,会重点关注的是有序整型数组和所有元素是不重复的字眼。那我们就很容易想到寻找一个数的基本二分查找,了解过的都知道逻辑很简单,就是有点细节把控不好.以至于出错。例如到底是 while(left < right) 还是 while(left <= right),到底是right = middle呢,还是要right = middle - 1呢?上面的问题就是区间定义没有分清楚,写二分法一般就是左闭右闭[left,right]和左闭右开[left,right)两种,接下来和大家一起讨论,用这两种方法如何解题。
整数二分法
指定的数字(binary_search)
第一种:左闭右闭[left,right]

class Solution {
public:
int search(vector& nums, int target) {
int left=0,right=nums.size()-1;
while(left<=right)
{
int mid=left+((right-left)>>1);//避免溢出
if(nums[mid]==target) return mid;//找到target,返回mid
else if(nums[mid]>target) right=mid-1;//往左区间[left,mid-1]查找
else left=mid+1; //往右区间[mid+1,right]查找
}
return -1;//查找失败返回-1
}
}; 时间复杂度:O(logn)
空间复杂度:O(1)
为了更好理解上面的代码,举个例子简单理解一下:
现在我们需要从序列A={1,5,6,8,9,11,15,16,20}中查找数字11的位置,其中序列是0下标是0到8(下标1到9也是没问题的大家下去可以模拟一下)
1.[left,right]=[0,8],因此下标中点是mid=(left+right)/2=4;A[mid]=A[4]=9;9<11;说明需要在 [mid+1,right]范围内继续找,因此left=mid+1=5;
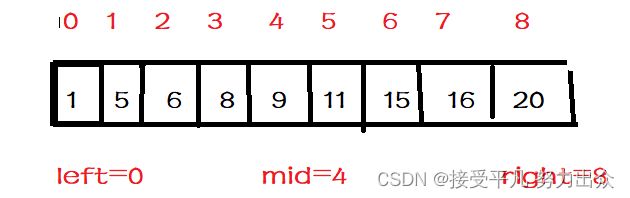
2.[left,right]=[5,8],因此下标中点是mid=(left+right)/2=6;A[mid]=A[6]=15;15>11;说明需要在[left,mid-1]范围内继续查找,因此right=mid-1=5;
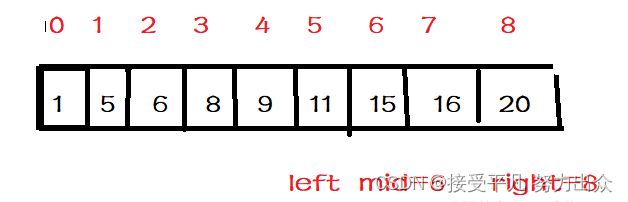
3.[left,right]=[5,5],因此下标中点mid=(left+right)/2=5;A[mid]=A[5]=11;11=11;说明找到了需要查找的数X,返回下标5

1.为什么while循环的条件中是<=,而不是
答:因为初始化right的赋值是nums.length-1,即最后一个元素的索引,而不是nums.length.这两者可能出现在不同功能的二分查找中,区别是;前者是相当于两端都闭区间[left,right],后者相当于左闭右开区间[left,right)。因为索引大小nums.length是越界的,所以我们把right这一边视为开区间。我们这个算法使用的是前者[left,right]两端都闭区间。这个区间其实就是每次进行搜索的区间。while(left<=right)的终止条件是left=right+1;while(left
2.为什么left=mid+1,right=mid-1?为什么有的代码写的是right=mid或left=mid?
答:刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即
[left, right]。那么当我们发现索引mid不是要找的target时,当然是去搜索区间[left, mid-1]或者区间[mid+1, right]对不对?因为mid已经搜索过,应该从搜索区间中去除。
第二种:左闭右开[left,right)
class Solution {
public:
int search(vector& nums, int target) {
int left=0,right=nums.size();
while(left>1);
if(nums[mid]>target)
{
right=mid;//target 在左区间,在[left, middle)中
}
else if(nums[mid]
时间复杂度:O(logn);
空间复杂度:O(1)
当然,二分查找也可以使用递归形式:
//二分区间为左闭右闭的[left,right],传入的初值为[0,n-1]
int binarySearch(int* a, int left, int right, int key)
{
while (left < right)
{
int mid = left + ((right - left) >> 1);
int number = a[mid];
if (number < key)
{
return binarySearch(a, mid + 1, right, key);
}
else if (number > key)
{
return binarySearch(a, left, mid - 1, key);
}
else
return mid;
}
}
第一个大于等于X的位置(lower_bound/upper_bound)
例如对下标0开始,有5个元素的序列为{1,3,3,3,6}来说,如果要查询3,则应当得到L=1,R=4;如果要查询5,则应当得到L=R=4;如果要查询6.应该得到L=4,R=5;而查询如果是8,则应该得到L=R=5.显然如果序列中没有X,那么L和R也可以理解为假设序列中存在X,则X应当在的位置.
做法其实和前面的很类似,下面我们来分析一下,假设当前的二分区间为左闭右闭区间[left,right],那么可以根据mid位置处的元素与欲查询元素x的大小来判断应当往哪个区间查找:
1.如果A[mid]>=x,说明第一个大于等于x的位置一定在mid处或者在mid的左侧,应该往左子区间[left,mid]继续查找,即令right=mid;

2.如果A[mid]在mid的右侧 ,应往右区间[mid+1,right]继续查找,即令left=mid+1;

代码:
//A[]为递增,x为查询数字;
//二分上下界为左闭右闭的[left,right],传入的初值为[0,n]
int low_bound(int A[],int left,int right,int x)
{
int mid;
while(left=x) right=mid;//中间的数大于等于x,往左边区间找[left,mid]
else left=mid+1;//中间的数小于x,往右边区间找[mid+1,right]
}
return left;
}
注意:1.循环条件为什么是leftright是[left,right]就不再是闭区间,可以作为元素不存在的判定原则,因此left<=right满足时循环应当一直执行。但是如果要是区间返回第一个大于等于x的元素,就不需要判断元素本身是不是存在,因为他就算不存在返回的也是"假设他存在,他应该的位置",于是当left==right时, 刚好能夹出唯一的位置,就是需要的结果.
2.由于left==right时while停止,因此最后返回left,right都可以.
3.二分的初始区间应该能覆盖到所有可能返回的结果.下界为0肯定的,那上界为什么是n,不是n-1,考虑到欲查询元素有可能比序列中任何数字都要大,此时应该返回n(即假设它存在,它应该在的位置).故初始化区间为[0,n];当然也有的题目要求不在则返回-1,这时候就不需要取到n,具体问题具体分析.
拓展: 其实这就是C++中lower_bound()函数的用法,返回第一个大于等于x数的位置,不存在则返回最后一个数的下一个位置;对应的也有个upper_bound()函数的用法,它是返回第一个大于x数的位置;这个大家可以去实现下,其实就是A[mid]>=x换成A[mid]>x就可以了.这两个函数大家可以去了解下,具体实现上面其实已经介绍了.

不大于X的最后一个位置
34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode)

简述下题意就是:就是查询一个数的起始位置和终止位置,不存在这个数就返回-1,所以这里取值范围不需要向上面一样取到n(这里不需要输出最后一个数的下一个位置);
需要写两个二分,一个需要找到>=x的第一个数,另一个需要找到<=x的最后一个数。查找不小于x的第一个位置,较为简单(上面已经讲过了):直接放代码
int l = 0, r = n - 1;
while (l < r) {
int mid = l + r >> 1;
if (a[mid] < x) l = mid + 1;
else r = mid;
}
查找不大于x的最后一个位置,便不容易了:
int l1 = l, r1 = n;
while (l1 + 1 < r1) {
int mid = l1 + r1 >> 1;
if (a[mid] <= x) l1 = mid;
else r1 = mid;
}
为什么不令r = mid - 1呢?因为如果按照上一个二分的写法,循环判断条件还是l < r,当只有两个元素比如2 2时,l指向第一个元素,r指向第二个元素,mid指向第一个元素,a[mid] <= x,l = mid还是指向第一个元素,指针不移动了,陷入死循环了,此刻l + 1 == r,未能退出循环。
那么直接把循环判断条件改成l + 1 < r呢?此时一旦只有两个元素,l和r差1,循环便不再执行,查找错误。
所以这里出现了二分的典型错误,l == r作为循环终止条件,会出现死循环,l + 1 == r作为循环终止条件,会出现查找错误
问题如何解决,一种方法就是将查找的区间设置为左闭右开,比如待查找元素在[0,n - 1]范围内,可以写成[0,n),令r = n,这时候只有两个元素时,r是取最右边元素的后一个位置的,l和r相差2,还会执行循环。
现在再来理解上一段的r1 = mid,说明a[mid] > x时,r = mid就表示待查找元素会是在r的左边,因为r是开区间。上面这种写法修改了循环条件使得二分不会死循环,修改了区间的开闭性使得不会查找错误。另一种解决办法就是:
int l = 0, r = n - 1;
while (l < r)
{
int mid = l + r + 1 >> 1;
if (a[mid] <= x) l = mid;
else r = mid - 1;
}
整数二分模板
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
浮点数二分法
首先介绍如何计算根号2的近似值。
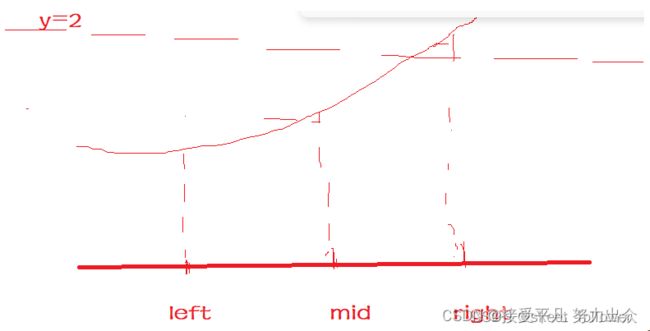
对于f(x)=x^2来说,在x属于[1,2]范围内,f(x)是随着x的增大而增大的,这就给使用二分法创造了条件,即可以用如下策略来逼近根号二的值。(这里不妨以精确到10^-5为例)
令浮点数left和right的初值分别是1和2,然后根据left和right的中点mid处f(x)的值与2的大小来选择子区间进行逼近.
如果f(mid)>2,说明mid>根号2,应当在[left,mid]的范围内继续逼近,故令right=mid;

如果f(mid)<2,说明mid<根号2,应该在[mid,right]的范围内继续逼近,故令left=mid.
代码:
const double eps=1e-5;
double f(double x)
{
return x*x;
}
double calsqrt()
{
double left=1,right=2,mid;
while(right-left>eps)
{
mid=(left+right)/2;
if(f(mid)>2) right=mid;
else left=mid;
}
return mid;
}
浮点数二分法模板
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-6; // eps 表示精度,取决于题目对精度的要求
while (r - l > eps)
{
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
return l;
}
LeetCode.27 移除元素
题目链接:27. 移除元素 - 力扣(LeetCode)
视频链接:数组中移除元素并不容易! | LeetCode:27. 移除元素_哔哩哔哩_bilibili
文章链接:双指针技巧秒杀七道数组题目 | labuladong 的算法笔记
代码随想录 (programmercarl.com)
相关练习:26. 删除有序数组中的重复项 - 力扣(LeetCode)
283. 移动零 - 力扣(LeetCode)
844. 比较含退格的字符串 - 力扣(LeetCode)
977. 有序数组的平方 - 力扣(LeetCode)
 思路: 本题for循环暴力解法也是可以通过的,我刚开始也是使用这个方法,时间复杂度是o(n^2),效率不高,我们先来实行一下代码。
思路: 本题for循环暴力解法也是可以通过的,我刚开始也是使用这个方法,时间复杂度是o(n^2),效率不高,我们先来实行一下代码。
class Solution {
public:
int removeElement(vector& nums, int val) {
int size=nums.size();
for(int i=0;i
时间复杂度:O(n^2)
空间复杂度:O(1)
那还有其他高效的方法去解题嘛?题目要求我们把nums中所有值为val的元素原地删除,需要使用快慢指针技巧:如果fast遇到值为val的元素,则直接跳过,否则就赋值给slow指针,并让slow前进一步。
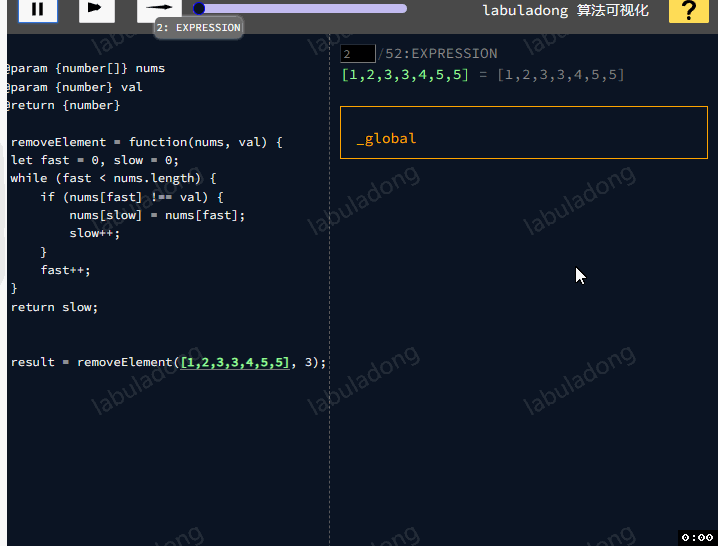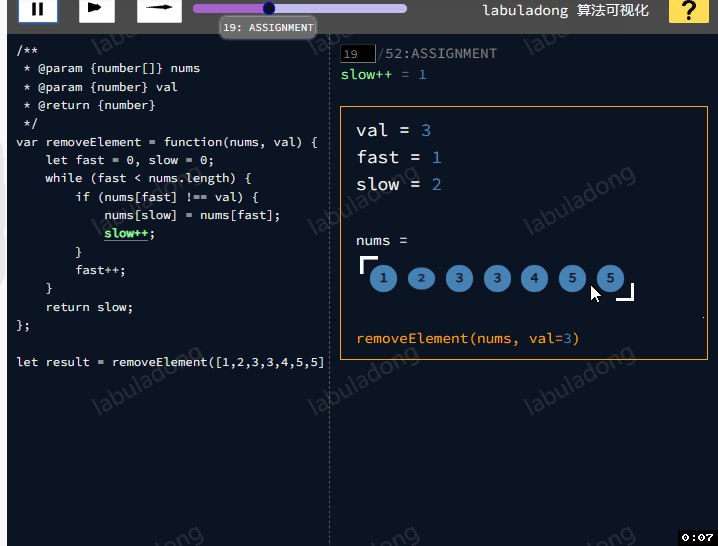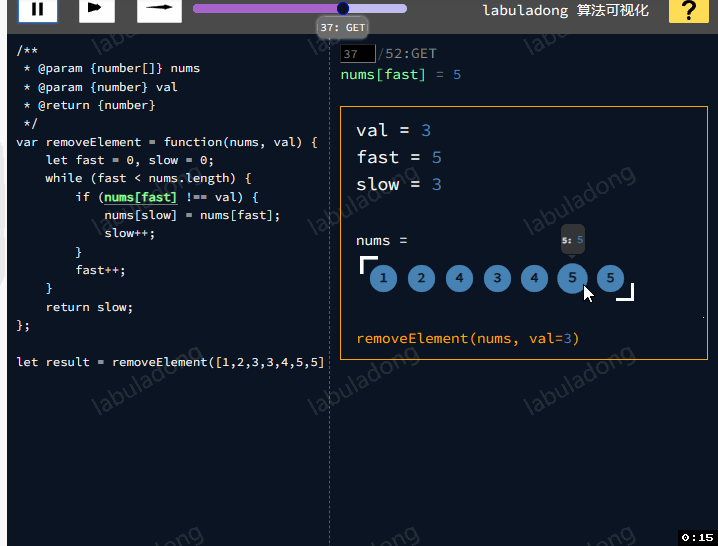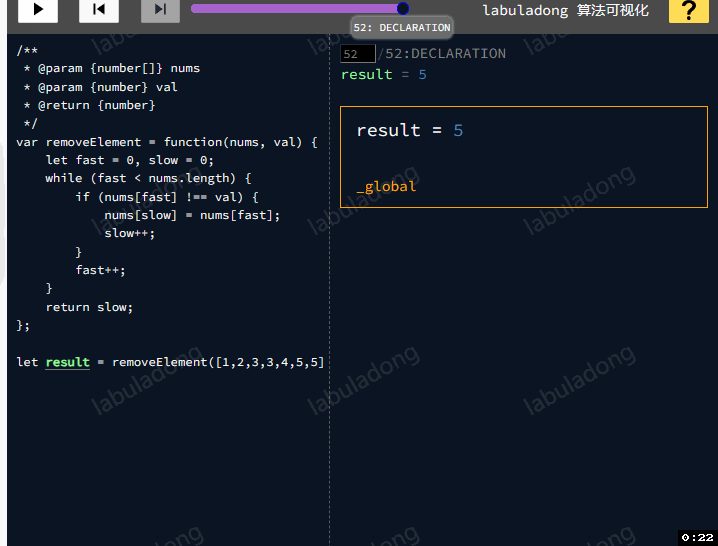
class Solution {
public:
int removeElement(vector& nums, int val) {
int fast = 0, slow = 0;
while (fast < nums.size()) {
if (nums[fast] != val) {
nums[slow] = nums[fast];
slow++;
}
fast++;
}
return slow;
}
};
时间复杂度:O(n)
空间复杂度:O(1)
总结
由于好久没有碰编程,这两题加上总结大概花费了3h左右,好在于学到了东西,让我对二分查找有了更好的认识,对开区间和闭区间,对是否需要加上等于号有了更清晰地定义和区分,第二题刚开始并没有想到快慢指针,而是用双层for循环,这样做在力扣上也是可以做的,为了提高算法效率,学习到了快慢指针并连同看了左右指针,有些细节已经忘了,重温了一遍,效果自我感觉不错,明天继续加油!!!
二分查找,也称为折半查找,是一种在有序数组中查找特定元素的高效算法。以下是二分查找的基本思想和一些细节:
基本思想:
- 数组需有序: 二分查找要求数组是有序的,通常是升序排列。
- 找中间值: 确定数组的中间元素,将其与目标值进行比较。
- 缩小搜索范围:
- 如果中间元素等于目标值,搜索结束。
- 如果中间元素大于目标值,说明目标值在左半部分,舍弃右半部分。
- 如果中间元素小于目标值,说明目标值在右半部分,舍弃左半部分。
- 重复操作: 在缩小的范围内重复上述过程,直到找到目标值或搜索范围为空。
-
注意事项和细节:
- 边界条件: 注意循环终止条件是
left <= right。
- 中间值的计算: 采用
(left + right) / 2 的方式可能导致整数溢出,建议使用 left + (right - left) / 2。
- 返回值: 返回查找到的元素的索引,如果未找到,通常返回 -1。
- 适用场景: 二分查找适用于有序数组,对于链表等数据结构不太适用。
- 变种: 有时候可能需要查找第一个等于目标值的元素、最后一个等于目标值的元素,或者第一个大于等于目标值的元素等,这需要根据具体问题进行变种。
-
复杂度:
- 时间复杂度:O(log n)。因为每次都将搜索范围缩小一半。
- 空间复杂度:O(1)。只需要常数级别的额外空间。
-
二分查找是一种高效的查找算法,但要求数据结构有序。在合适的场景下,它比线性查找等其他方法更加快速。
快慢指针细节和应用场景:
-
判断链表是否有环:
- 快指针每次移动两步,慢指针每次移动一步。
- 如果链表中有环,快指针最终会追上慢指针。
- 这个方法的时间复杂度是 O(n)。
-
找到链表的中间节点:
- 快指针每次移动两步,慢指针每次移动一步。
- 当快指针到达链表尾部时,慢指针刚好在链表的中间。
- 这个方法同样具有 O(n) 的时间复杂度。
-
其他应用场景:
- 在一些问题中,快慢指针可以用于同时遍历链表,实现一些巧妙的算法。
- 例如,找到倒数第 k 个节点,判断是否为回文链表等。
-
注意事项:
- 在使用快慢指针时,要注意边界条件,防止空指针异常。
- 确保在移动指针之前检查指针及其下一个节点是否为空。
这种算法在链表相关的问题中应用广泛,它的巧妙之处在于通过两个不同速度的指针来实现一些高效的操作。