实现线程同步的几种方式
线程同步
1. 线程同步概念
线程同步是指多个线程协调它们的执行顺序,以确保它们正确、安全地访问共享资源。在并发编程中,当多个线程同时访问共享数据或资源时,可能会导致竞争条件(Race Condition)和其他并发问题
所谓的同步并不是多个线程同时对内存进行访问,而是按照先后顺序依次进行的。
1.1 为什么要同步
在研究线程同步之前,先来看一个两个线程交替数数(每个线程数50个数,交替数到100)的例子:
#include 运行程序的结果为:
Thread B, id = 2, number = 1
Thread A, id = 1, number = 1
Thread B, id = 2, number = 2
Thread A, id = 1, number = 3
Thread B, id = 2, number = 4
Thread B, id = 2, number = 5
Thread A, id = 1, number = 5
Thread A, id = 1, number = 6
Thread B, id = 2, number = 7
Thread A, id = 1, number = 8
Thread B, id = 2, number = 9
Thread A, id = 1, number = 10
Thread B, id = 2, number = 11
Thread B, id = 2, number = 12
Thread A, id = 1, number = 12
Thread B, id = 2, number = 13
Thread A, id = 1, number = 13
Thread A, id = 1, number = 14
Thread B, id = 2, number = 15
Thread B, id = 2, number = 16
Thread A, id = 1, number = 16
Thread A, id = 1, number = 17
Thread B, id = 2, number = 18
Thread B, id = 2, number = 19
Thread A, id = 1, number = 19
Thread B, id = 2, number = 20
Thread A, id = 1, number = 20
Thread A, id = 1, number = 21
Thread B, id = 2, number = 22
Thread A, id = 1, number = 23
Thread B, id = 2, number = 23
Thread B, id = 2, number = 24
Thread A, id = 1, number = 24
Thread A, id = 1, number = 25
Thread B, id = 2, number = 26
Thread A, id = 1, number = 27
Thread B, id = 2, number = 28
Thread A, id = 1, number = 29
Thread B, id = 2, number = 30
Thread A, id = 1, number = 31
可以看出每个线程各数20个数, 最后到31就结束了(每次运行结果也不一样), 其原因就是没有对线程进行同步处理,造成了数据的混乱。就是说一个线程对数据做++操作后, 还没等把数据写入到内存之后, 另一个线程就开始工作了, 拿到的数字还是做加法操作之前的数字, 就会造成数据混乱
1.2 同步方式
常用的线程同步方式有四种:**互斥锁、读写锁、条件变量、信号量。**所谓的共享资源就是多个线程共同访问的变量,这些变量通常为全局数据区变量或者堆区变量,这些变量对应的共享资源也被称之为临界资源。
2. 互斥锁
互斥锁是线程同步最常用的一种方式,通过互斥锁可以锁定一个代码块, 被锁定的这个代码块, 所有的线程只能顺序执行(不能并行处理),这样多线程访问共享资源数据混乱的问题就可以被解决了,需要付出的代价就是执行效率的降低,因为默认临界区多个线程是可以并行处理的,现在只能串行处理。
2.1 相关函数
在Linux中互斥锁的类型为pthread_mutex_t,创建一个这种类型的变量就得到了一把互斥锁:
pthread_mutex_t mutex;
一般情况下,每一个共享资源对应一个把互斥锁,锁的个数和线程的个数无关。
锁的初始化和销毁:
// 初始化互斥锁
// restrict: 是一个关键字, 用来修饰指针, 只有这个关键字修饰的指针可以访问指向的内存地址, 其他指针是不行的
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
// 释放互斥锁资源
int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数:
- mutex: 互斥锁变量的地址
- attr: 互斥锁的属性, 一般使用默认属性即可, 这个参数指定为NULL
互斥锁的锁定和解锁
// 修改互斥锁的状态, 将其设定为锁定状态, 这个状态被写入到参数 mutex 中
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 对互斥锁解锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);
对于加锁函数pthread_mutex_lock:
- 没有被锁定, 是打开的, 这个线程可以加锁成功, 这个这个锁中会记录是哪个线程加锁成功了
- 如果被锁定了, 其他线程加锁就失败了, 这些线程都会阻塞在这把锁上
- 当这把锁被解开之后, 这些阻塞在锁上的线程就解除阻塞了,并且这些线程是通过竞争的方式对这把锁加锁,没抢到锁的线程继续阻塞
解锁函数: 不是所有的线程都可以对互斥锁解锁,哪个线程加的锁, 哪个线程才能解锁成功。
尝试加锁函数
// 尝试加锁
int pthread_mutex_trylock(pthread_mutex_t *mutex);
调用这个函数对互斥锁变量加锁还是有两种情况:
- 如果这把锁没有被锁定是打开的,线程加锁成功
- 如果锁变量被锁住了,调用这个函数加锁的线程,不会被阻塞,加锁失败直接返回错误号
2.2 互斥锁的使用
在看上面的例子, 加上互斥锁之后:
//
// Created by kk on 2024/1/11.
//
#include 运行结果为:
Thread A, id = 1, number = 1
Thread B, id = 2, number = 2
Thread A, id = 1, number = 3
Thread B, id = 2, number = 4
Thread A, id = 1, number = 5
Thread B, id = 2, number = 6
Thread A, id = 1, number = 7
Thread B, id = 2, number = 8
Thread A, id = 1, number = 9
Thread B, id = 2, number = 10
Thread A, id = 1, number = 12
Thread B, id = 2, number = 12
Thread B, id = 2, number = 14
Thread A, id = 1, number = 13
Thread A, id = 1, number = 15
Thread B, id = 2, number = 16
Thread A, id = 1, number = 18
Thread B, id = 2, number = 18
Thread A, id = 1, number = 19
Thread B, id = 2, number = 20
Thread B, id = 2, number = 22
Thread A, id = 1, number = 22
Thread A, id = 1, number = 23
Thread B, id = 2, number = 24
Thread A, id = 1, number = 25
Thread B, id = 2, number = 26
Thread A, id = 1, number = 27
Thread B, id = 2, number = 28
Thread B, id = 2, number = 30
Thread A, id = 1, number = 30
Thread A, id = 1, number = 31
Thread B, id = 2, number = 32
Thread A, id = 1, number = 33
Thread B, id = 2, number = 34
Thread A, id = 1, number = 35
Thread B, id = 2, number = 36
Thread A, id = 1, number = 37
Thread B, id = 2, number = 38
Thread A, id = 1, number = 39
Thread B, id = 2, number = 40
3. 死锁
死锁是指两个或多个线程或进程在执行过程中,因争夺资源而造成的一种互相等待的状态,导致程序无法继续执行下去。如果线程死锁造成的后果是:所有的线程都被阻塞,并且线程的阻塞是无法解开的(因为可以解锁的线程也被阻塞了)。
3.1 造成死锁的几种场景
- 加锁后忘记解锁
// 场景1
void func()
{
for(int i=0; i<6; ++i)
{
// 当前线程A加锁成功, 当前循环完毕没有解锁, 在下一轮循环的时候自己被阻塞了
// 其余的线程也被阻塞
pthread_mutex_lock(&mutex);
....
.....
// 忘记解锁
}
}
// 场景2
void func()
{
for(int i=0; i<6; ++i)
{
// 当前线程A加锁成功
// 其余的线程被阻塞
pthread_mutex_lock(&mutex);
....
.....
if(xxx)
{
// 函数退出, 没有解锁(解锁函数无法被执行了)
return ;
}
pthread_mutex_lock(&mutex);
}
}
28行, 会直接return 没有解锁
- 重复加锁, 造成死锁
void func()
{
for(int i=0; i<6; ++i)
{
// 当前线程A加锁成功
// 其余的线程阻塞
pthread_mutex_lock(&mutex);
// 锁被锁住了, A线程阻塞
pthread_mutex_lock(&mutex);
....
.....
pthread_mutex_unlock(&mutex);
}
}
// 隐藏的比较深的情况
void funcA()
{
for(int i=0; i<6; ++i)
{
// 当前线程A加锁成功
// 其余的线程阻塞
pthread_mutex_lock(&mutex);
....
.....
pthread_mutex_unlock(&mutex);
}
}
void funcB()
{
for(int i=0; i<6; ++i)
{
// 当前线程A加锁成功
// 其余的线程阻塞
pthread_mutex_lock(&mutex);
funcA(); // 重复加锁
....
.....
pthread_mutex_unlock(&mutex);
}
}
37行 再次调用funcA()就会重复加锁
- 在程序中有多个共享资源, 因此有很多把锁,随意加锁,导致相互被阻塞
场景描述:
1. 有两个共享资源:X, Y,X对应锁A, Y对应锁B
- 线程A访问资源X, 加锁A
- 线程B访问资源Y, 加锁B
2. 线程A要访问资源Y, 线程B要访问资源X,因为资源X和Y已经被对应的锁锁住了,因此这个两个线程被阻塞
- 线程A被锁B阻塞了, 无法打开A锁
- 线程B被锁A阻塞了, 无法打开B锁
3.2 产生死锁的四个条件
- 互斥条件;
- 持有并等待条件;
- 不可剥夺条件;
- 环路等待条件;
互斥条件
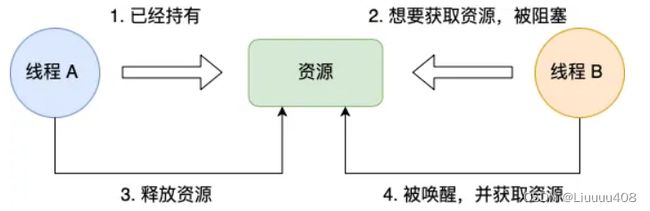
互斥条件是指多个线程不能同时使用同一个资源。
比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。
持有并等待条件
持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。

不可剥夺条件
不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。

环路等待条件
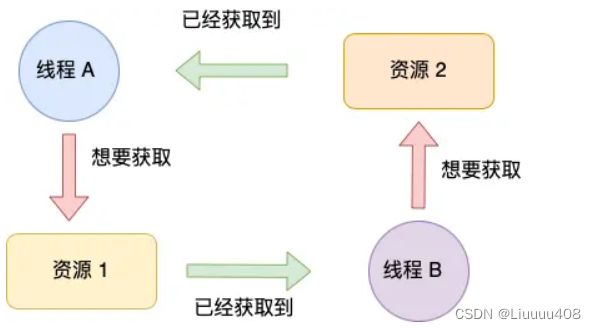
环路等待条件指的是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。
比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图。
3.3 利用工具排查死锁问题
在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题。
pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 pstack 就可以了。
那么,在定位死锁问题时,我们可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。
4. 读写锁
4.1 概念
读写锁(Read-Write Lock)是一种用于支持多线程并发访问的同步机制,它分为读锁和写锁两种类型。在某些场景中,多个线程可能同时读取共享资源,但只有一个线程能够写入共享资源。读写锁通过允许多个线程同时获取读锁,但只允许一个线程获取写锁,来提高并发性能。
读写锁的工作原理是:
- 当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
- 但是,一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
4.2 相关函数
锁的类型为pthread_rwlock_t,有了类型之后就可以创建一把互斥锁了:
pthread_rwlock_t rwlock;
初始化和销毁
#include 参数:
- rwlock: 读写锁的地址,传出参数
- attr: 读写锁属性,一般使用默认属性,指定为NULL
加读锁, 锁定读操作
// 在程序中对读写锁加读锁, 锁定的是读操作
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作,调用这个函数依然可以加锁成功,因为读锁是共享的;如果读写锁已经锁定了写操作,调用这个函数的线程会被阻塞。
// 在程序中对读写锁加写锁, 锁定的是写操作
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作或者锁定了写操作,调用这个函数的线程会被阻塞。
// 解锁, 不管锁定了读还是写都可用解锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
5. 自旋锁
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
- 互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;(一直占用CPU)
互斥锁相比自旋锁会有两次上下文的切换, 这就是多出来的开销成本
- 当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
当被锁住的代码执行时间很短的话, 上下文切换的时间可能比代码执行时间还要久
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
一般加锁的过程,包含两个步骤:
- 第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
- 第二步,将锁设置为当前线程持有;
自旋锁会将检查所的状态和加锁两个步骤合并成一条硬件级指令, 原子指令, 这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。
6. 条件变量
6.1 概述
条件变量(Condition Variable)是一种多线程同步的机制,用于在多个线程之间建立通信。条件变量通常与互斥锁(Mutex)一起使用,以解决线程间的协调和同步问题。
**条件变量用于在某个条件发生或者满足时通知其他线程。**典型的情况是,一个线程等待某个条件变为真,而另一个线程在某些情况下负责将条件设置为真,并通知等待的线程。这样,等待线程可以被唤醒并继续执行。
6.2 相关函数
条件变量类型对应的类型为pthread_cond_t,这样就可以定义一个条件变量类型的变量了:
pthread_cond_t cond;
初始化和销毁
#include 参数:
- cond: 条件变量的地址
- attr: 条件变量属性, 一般使用默认属性, 指定为NULL
// 线程阻塞函数, 哪个线程调用这个函数, 哪个线程就会被阻塞
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
pthread_cond_wait 使线程等待条件变量的信号。当线程调用此函数时,它会原子性地释放与互斥锁关联的锁,并使线程休眠直到收到信号。
// 表示的时间是从1971.1.1到某个时间点的时间, 总长度使用秒/纳秒表示
struct timespec {
time_t tv_sec; /* Seconds */
long tv_nsec; /* Nanoseconds [0 .. 999999999] */
};
// 将线程阻塞一定的时间长度, 时间到达之后, 线程就解除阻塞了
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
这个函数的前两个参数和pthread_cond_wait函数是一样的,第三个参数表示线程阻塞的时长,但是需要额外注意一点:struct timespec这个结构体中记录的时间是从1971.1.1到某个时间点的时间,总长度使用秒/纳秒表示。因此赋值方式相对要麻烦一点:
time_t mytim = time(NULL); // 1970.1.1 0:0:0 到当前的总秒数
struct timespec tmsp;
tmsp.tv_nsec = 0;
tmsp.tv_sec = time(NULL) + 100; // 线程阻塞100s
// 唤醒阻塞在条件变量上的线程, 至少有一个被解除阻塞
int pthread_cond_signal(pthread_cond_t *cond);
// 唤醒阻塞在条件变量上的线程, 被阻塞的线程全部解除阻塞
int pthread_cond_broadcast(pthread_cond_t *cond);
调用上面两个函数中的任意一个,都可以换线被pthread_cond_wait或者pthread_cond_timedwait阻塞的线程,区别就在于pthread_cond_signal是唤醒至少一个被阻塞的线程(总个数不定),pthread_cond_broadcast是唤醒所有被阻塞的线程。
7. 信号量
信号量是一种用于多线程或多进程之间同步和互斥的同步原语。它是一个计数器,用于控制同时访问共享资源的线程或进程的数量。信号量通常被用来解决竞争条件和协调多个线程或进程之间的操作。
信号量表示资源的数量,控制信号量的方式有两种原子操作:
- 一个是 P 操作,这个操作会把信号量减去 1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
- 另一个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
具体的过程如下:
- 进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。
- 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。
- 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
可以发现,信号初始化为 1,就代表着是互斥信号量,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
信号量也可以用于消费者和生产者模型
另一种情况

具体过程:
- 如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待;
- 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B;
- 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
可以发现,信号初始化为 0,就代表着是同步信号量,它可以**保证进程 A 应在进程 B 之前执行**。