CMU 15-213 CSAPP (Ch1~Ch3)
视频链接
课件链接
该视频课程使用 64位 编译器!
本文使用编译器从Ch.3.6开始换到64位,因此3.6之前 地址 为4字节,之后为8字节!
Ch1.计算机系统漫游
C编译(ccl)与链接(ld)
Switch是否总时比if-else高效?
while循环总比for循环高效么?
指针引用比数组高效么?
函数的本地临时变量为什么比入参的引用更高效?
算数表达式的括号也能影响运算速度?
Ch2.信息的表示和处理
Integer – 补码与符号位
负数“补码”可视化
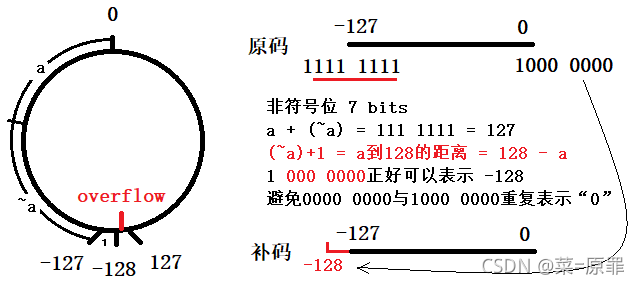
事实上,有符号数(two’s complement,补码)的符号位,是具有权重的,只不过需要取反,如-2表示为 1111 , 1110 = − 2 7 + ∑ w = 1 w = 6 2 w + 0 ∗ 2 w = 0 = − 2 1111,1110=\red {-2^7}+\sum_{\red {w=1}}^{w=6}2^w+0*2^{\red {w=0}}=-2 1111,1110=−27+∑w=1w=62w+0∗2w=0=−2
“unsigned and singed numbers have same bit pattern,just a bunch of bits to computer itself.”
//sizeof return unsigned int, cast a into unsigned, you got stuck forever
for(int a=1;a-sizeof(a)>=0;a--)
//so be care of unsigned "i" used for array in case a[i]
//i=0; i--=UMAX; a[i] may cause out of bounds
int main()
{
unsigned int a=numeric_limits<unsigned int>::max();
int b=-1;
unsigned int c=-3;
cout<<(int)a<<" "<<a<<endl; //-1 4294967295
cout<<(b==a?"True":"Flase")<<endl; //True
cout<<(b>a?"True":"Flase")<<endl; //Flase
cout<<std::hex<<c<<" "<<-c<<" "<<c+(-c)<<endl; //fffffffd 3 0
cout<<std::hex<<b<<"\n"<<numeric_limits<int>::max()<<endl; //ffffffff 7fffffff
cout<<b+numeric_limits<int>::max()<<endl; //7ffffffe
return 0;
}
符号位扩展/截断
0110 = − 0 × 2 3 + 1 × 2 2 + 1 × 2 1 + 0 × 2 0 = 6 0110 = -0\times2^{3}+1\times2^{2}+1\times2^{1}+0\times2^{0}=6 0110=−0×23+1×22+1×21+0×20=6
1110 = − 1 × 2 3 + 1 × 2 2 + 1 × 2 1 + 0 × 2 0 = − 2 1110 = -1\times2^{3}+1\times2^{2}+1\times2^{1}+0\times2^{0}=-2 1110=−1×23+1×22+1×21+0×20=−2
11110 = − 1 × 2 4 + 1 × 2 3 + 1 × 2 2 + 1 × 2 1 + 0 × 2 0 = − 2 11110 = \red{-1\times2^{4}+1\times2^{3}}+1\times2^{2}+1\times2^{1}+0\times2^{0}=-2 11110=−1×24+1×23+1×22+1×21+0×20=−2
符号位左移填充, − 1 × 2 n + 1 + 1 × 2 n = − 1 × 2 n \red{-1\times2^{n+1}+1\times2^{n}}=-1\times2^{n} −1×2n+1+1×2n=−1×2n“负权重”不变
Floating point – IEEE 754
Numerical Form
( − 1 ) s M × 2 E (-1)^{s}M\times2^{E} (−1)sM×2E
| precision | sign field | exp field | frac field |
|---|---|---|---|
| value | s | exp | frac |
| single | 1 bit | k = 8 bit | 23 bit |
| double | 1bit | k = 11 bit | 52 bit |
Extended precision 英特尔特用 | 1 bit |15 bit | 64 bit
共10字节,对齐16字节,因此后6字节为空
Normalized Values
e x p ≠ 000...0 exp \neq 000...0 exp=000...0 or 111...1 111...1 111...1
- E = e x p − b i a s = e x p − ( 2 k − 1 − 1 ) E = exp - bias =exp - (2^{k-1}-1) E=exp−bias=exp−(2k−1−1)
- M = 1. x x . . . x 2 M = 1.xx...x_2 M=1.xx...x2
- Why bias = 2 k − 1 − 1 = 2^{k-1}-1 =2k−1−1, not 2 k − 1 2^{k-1} 2k−1?
Denormalized Values
e x p = 000...0 exp = 000...0 exp=000...0
- E = 1 − b i a s E = 1 - bias E=1−bias
- M = 0. x x . . . x 2 M = 0.xx...x_2 M=0.xx...x2
| s | exp | frac | represent | |
|---|---|---|---|---|
| denorms | 0 | 0000,0000 | 11…1 | 2 − 126 × ( 2 − 1 + . . . + 2 − 23 ) = 2 − 126 × ( 1 − 2 − 23 ) 2^{-126}\times(2^{-1}+...+2^{-23})=2^{-126}\times(1-2^{-23}) 2−126×(2−1+...+2−23)=2−126×(1−2−23) |
| norms | 0 | 0000,0001 | 00…0 | 1.0 × 2 − 126 1.0\times2^{-126} 1.0×2−126 |
| 将"1.00…0"移位成 0.1 × 2 1 0.1\times2^{1} 0.1×21,并将 2 1 2^1 21"隐藏"至E中,因此 E = 1 − b i a s ≠ 0 − b i a s E=1-bias\red\neq 0-bias E=1−bias=0−bias | ||||
| 从而实现了从 2 − 126 2^{-126} 2−126到 2 − 127 2^{-127} 2−127,从 D E N O R M m a x DENORM_{max} DENORMmax到 N O R M m i n NORM_{min} NORMmin的平滑过渡,使浮点数如无符号整型+1进位! | ||||
| 非标准化值最高精度 = 0 , 00000000 , 000...01 = 1 × 2 − 126 − 23 = 2 − 149 =0,00000000,000...01=1\times2^{\red{-126-23}}=2^{-149} =0,00000000,000...01=1×2−126−23=2−149 |

使用非标准化浮点可以表示更接近“0”的小数,越靠近0,E越小分辨率越高,数与数间距越小
Special Values
| exp | frac | meaning | |
|---|---|---|---|
| + ∞ +\infin +∞ | 111…1 | 000…0 | overflows |
| NaN | 111…1 | ≠ \red\neq = 000…0 | no feasible answer |
1.0 / − 0.0 = − ∞ 1.0/-0.0=-\infin 1.0/−0.0=−∞
− 1 = ∞ − ∞ = ∞ × 0 = N a N \sqrt{-1}=\infin - \infin =\infin \times 0 =NaN −1=∞−∞=∞×0=NaN
Special Properties of IEEE Encoding
- Using unsigned Integer Comparison,Except NaN
- Round to fit limited “frac field”.( especially addition and multiplication), IEEE use Nearest Even. 二进制中,末尾0为偶,1为奇
Round to nearest 2 − 2 2^{-2} 2−2,watch out nearsest right bit( 2 − 3 2^{-3} 2−3 in this case)
value binary Note Rounded Rounded Value 2 3 32 2 \frac{3}{32} 2323 10.00 0 1 1 2 10.00\red{0}11_{2} 10.000112 0.00011 < 2 − 3 0.00011<2^{-3} 0.00011<2−3 10.0 0 2 10.00_{2} 10.002 2 2 3 16 2\frac{3}{16} 2163 10.00 1 1 0 2 10.00\red{1}10_{2} 10.001102 0.00110 > 2 − 3 0.00110>2^{-3} 0.00110>2−3 10.0 1 2 10.01_{2} 10.012 2 1 4 2\frac{1}{4} 241 2 7 8 2\frac{7}{8} 287 10.11 1 0 0 2 10.11\red{1}00_{2} 10.111002 0.00100 = 2 − 3 0.00100=2^{-3} 0.00100=2−3
got odd (10.11) if drop >it10.11 1 2 + 0.00 1 2 = 11.0 0 2 10.111_{2}+0.001_{2}=11.00_{2} 10.1112+0.0012=11.002 3 3 3 2 5 8 2\frac{5}{8} 285 10.10 1 0 0 2 10.10\red{1}00_{2} 10.101002 0.00100 = 2 − 3 0.00100=2^{-3} 0.00100=2−3
got even (10.10) if drop >it10.10 1 2 − 0.00 1 2 = 10.1 0 2 10.101_{2}-0.001_{2}=10.10_{2} 10.1012−0.0012=10.102 2 1 2 2\frac{1}{2} 221
- Addition is Commutative but not associative(可交换,无结合)
( 3.14 + 1 e 10 ) − 1 e 10 = 1 e 10 − 1 e 10 = 0 (3.14+1e10)-1e10=1e10-1e10=0 (3.14+1e10)−1e10=1e10−1e10=0
3.14 + ( 1 e 10 − 1 e 10 ) = 3.14 + 0 = 3.14 3.14+(1e10-1e10)=3.14+0=3.14 3.14+(1e10−1e10)=3.14+0=3.14
- Additive inverse (存在相反数,带符号位相加和为0)except for infinities and NaN
- Multiplication Commutative but not Associative
( 1 e 20 ∗ 1 e 20 ) ∗ 1 e − 20 = ∞ ∗ 1 e − 20 = ∞ (1e20*1e20)*1e-20=\infin * 1e-20=\infin (1e20∗1e20)∗1e−20=∞∗1e−20=∞
1 e 20 ∗ ( 1 e 20 ∗ 1 e − 20 ) = 1 e 20 ∗ 1 = 1 e 20 1e20*(1e20*1e-20)=1e20*1=1e20 1e20∗(1e20∗1e−20)=1e20∗1=1e20
d m i n < 0 d_{min}<0 dmin<0, d m i n ∗ 2 = o v e r f l o w < 0 d_{min}*2 =overflow < 0 dmin∗2=overflow<0 #负数溢出也小于0
- [Key] keep dynamic range in your mind while adding or multiplying floating point.
- 类型转换改变位(值),如浮点转整型,直接Truncates fractional part(round toward zero).
#include Data Lab
Ch3.Machine Level Programming
3.1 x86
Intell x86(字母“x”86,不念“叉86”)
date Transistors MHz feature 8086 1978 29K 5-10 First 16-bit microprocessor,1MB addr space
Slight vatiation was a basis for IBM pc8286 8386 1985 275K 16-33 32bit + “flat addressing”=> Unix capable
IA32(Intell Architecture 32)Pentium 4E 2004 125M 2800-3800 First x86-64
power consumption 100W
power budget problemCore 2 2006 291M 1060-3500 First multi-core Inter processor Core i7 2008 731M 1700-3900 4 cores — shark machine 1980s,RISC vs. CISC.(Reduced instruction set computer)
| Desktop Mode | Server Model |
|---|---|
| 4 cores | 8 cores |
| Integrated graphics | Integrated I/O |
| 3.3-3.8 GHz | 2~2.6 GHz |
| 65W | 45W |
Advanced Micro Devices
| years | Intell | AMD |
|---|---|---|
| 2001 | A little bit slower for a lot cheaper | Itanium /aɪˈteɪniəm/ 安腾Arch = IA64 too ideally, disappointing |
| 2003 | Come up with x86-64, or called “AMD64” | Insisting focus on IA64 |
| 2004 | EM64T(almost identical to x86-64) lots of code still run in 32 bit mode. |
|
| Cross license allows AMD to produce x86 processors. |
Acorn Risc Machine
Sufficiently simple and could be customized(个性化).
Lower power requirement than x86 machine.
Sell companies the rights (Intellectual property) to use their designs,not chips.
Definitions
| terminology | definitions | Examples |
|---|---|---|
| Architechture or ISA | Instruction Set Architecture The parts of a processor design that one needs to understand or write machine code. |
Instruction Set Specification,Registers. |
| Microarchitecture | Implementation of the architecture ISA is the abstraction helps hardware people design |
Cache sizes and core frequency. |
| Machine Code | Byte-level programs that processor executes | |
| Assembly Code | Text version of machine code |
3.2 Machine Code View
There is no way (or instructions) you can directly access or manipulate cache.
-
PC:Program counter
Address of next instruction
Called “RIP”(x86-64) -
Register file
Heavily used program data -
Condition codes
Store status information about most recent arithmetic or logical operation
Used for conditional branching -
Memory
Byte addressable array
Code and user data
Stack to support procedures
以之前的浮点实验为例
调用gcc 实际间接调用了一系列(a sequency of program)进程
Options starting with -g, -f, -m, -O, -W, or --param are automatically
【-O】Do optimization
【-Og】Use debug level optimizations to makethe code readable
【-O2】The most common optimization level
| Instruction | Function | output |
|---|---|---|
| g++ -E *.cpp | Preprocess only | *.i |
| g++ -Og -S *.cpp | “Stop” after compile | *.s |
| g++ -c *.s | Compile to get assemblely code | *.o |
| g++ *.o | Link and get excutable program | *.exe、a.out |
| objdump -d *.exe | disassemble binary excutable program | *.s |
Period indicates “not instructions” but information needs by debuger、linker and so on.
3.3 Machine-Level Programming I:Basics
Disasemble by gdb
#include >gdb .\*.exe
>(gdb) disassemble main
Dump of assembler code for function main:
0x00401460 <+0>: push %ebp
0x00401461 <+1>: mov %esp,%ebp
0x00401463 <+3>: and $0xfffffff0,%esp
0x00401466 <+6>: sub $0x10,%esp
0x00401469 <+9>: call 0x401a30 <__main>
0x0040146e <+14>: movl $0x405065,0x4(%esp)
0x00401476 <+22>: movl $0x408254,(%esp)
End of assembler dump.
>(gdb) x/3xb 0x00401466
0x401466 <main+6>: 0x83 0xec 0x10
x86-64 Integer Registers
%r* means 64bits
%e*x = %r*L (%r*x的low-order 32 bits)
why “ax,bx,ex …”? 历史沿用
| Registers | Purposes |
|---|---|
| EAX | Accumulator for operands and results data |
| EBX | Pointer to data in the DS segment |
| ECX | Counter for string and loop operations |
| EDX | I/O pointer |
| ESI | Pointer to data in the segment pointed to by the DS register; source pointer for string operations |
| EDI | Pointer to data in the segment pointed to by the ES register; destination pointer for string operations |
| ESP | Stack pointer (in the SS segment) |
| EBP | Pointer to data on the stack (in the SS segment),or called base pointer |
 |
详见 Intel SDM 下载地址
movq Src, Dest
“q” for “quad word” (64bits,Intell terminology)
“l” for “long word” (32bits)
“word” for 16 bits (8086)
| Src Types | Example | Dest | C analog(treat reg as var) |
|---|---|---|---|
| Immediate | $0x400 | Reg,Mem | temp = 0x4; *p=0x4; |
| Register | %rax,%r13 | Reg,Mem | temp2 = temp1;*p=temp; |
| Memory | (%rax) | Reg | temp = *p; |
| Memory Dereference |
- Normal Form
movq (Reg),[Reg/Mem]
location in Memory,Address = register value
| C type | Machine Level |
|---|
void swap(long *xp,long *yp)
{
long t0 = *xp;
long t1=*yp;
*xp=t1;
*yp=t0;
}|
swap:
movq (%rdi), %rax
movq (%rsi), %rdx
movq %rdx, (%rdi)
movq %rax, (%rsi)
ret >* [Arguments always come in (at most 6) specific registers in orders]():rdi,rsi,... >* [Register Allocation algorithm?]()
- Displacement
movq Disp(Reg),[Reg/Mem]
location in memory,Address = value in Reg + const Disp
- Most General/Elaborate Form
movq Disp(Rb,Ri,Scale),Reg/Mem
location in memory,Address = Rb + Scale*Ri + Disp
leaq Src,Dst
Load Effective Address = ampersand(&) operation in C
Preety handy way to do arithmetic and C compiler likes to use it.
Src would be memory refrence.
Dest has to be register,store the address computed from Src, not value.
long m12(long x)
{
return 12*x;
}
//g++ -S *.cpp
__Z3m12l:
movl %edx, %eax
addl %eax, %eax
addl %edx, %eax
sall $2, %eax
popl %ebp
ret
//g++ -Og -S *.cpp
__Z3m12l:
movl 4(%esp), %eax
leal (%eax,%eax,2), %edx //x+x*2 ==> dx
leal 0(,%edx,4), %eax //(x+x*2)*4 ==> ax
ret
//lecture
leal (%eax,%eax,2), %edx //x+x*2 ==> dx
sall $2, %edx //(x+x*2)<<2 ==> ax
ret
Other Instructions
- Two Operand
| Format | Computation in C form |
|---|---|
| addq Src, Dest | Dest = Dest + Src |
| subq Src, Dest | Dest = Dest - Src |
| imulq Src, Dest | Dest = Dest * Src |
| salq Src, Dest | Dest = Dest << Src (=shlq) |
| sarq Src, Dest | Dest = Dest >> Src (Arithmetic) |
| shrq Src, Dest | Dest = Dest >> Src (Logical) |
| xorq Src, Dest | Dest = Dest ^ Src |
| andq Src, Dest | Dest = Dest & Src |
| orq Src, Dest | Dest = Dest | Src |
- One Operand
| Format | Computation in C form |
|---|---|
| incq Dest | Dest = Dest + 1 |
| decq Dest | Dest = Dest - 1 |
| negq Dest | Dest = -1 * Dest (negate 取反) |
| notq Dest | Dest = ~ Dest (tilde “~” not exclamation “!”) |
| sarq Src, Dest | Dest = Dest >> Src (Arithmetic) |
| shrq Src, Dest | Dest = Dest >> Src (Logical) |
| xorq Src, Dest | Dest = Dest ^ Src |
| andq Src, Dest | Dest = Dest & Src |
| orq Src, Dest | Dest = Dest | Src |
3.4 Machine-Level Programming II:Control
So far the registers we should know
- Temporary data :%rax…%rdx,%rsi,%rdi,%r8~%r15…
- Location of runtime stack:
%rsp(stack pointer)%rbp(base pointer)…
- Location of current control :%rip(instruction pointer)…
- Status of recent tests:CF,ZF,SF,OF…Total 8 of them
Condition codes
All of them is one bit flag, get or set not directly but as a side effect of other operation.
| Registers | name to memorize | set if |
|---|---|---|
| CF | Carry Flag | carry out from most significant bit (unsigned overflow) |
| ZF | Zero Flag | Dest == 0 |
| SF | Sign Flag | Dest<0(as signed) |
| OF | Overflow Flag | two’s-complement(signed)overflow a>0,b>0,a+b<0 a<0,b<0,a+b>0 a*b<0,can’t overflow |
| Attention! Lea 不影响标志位! |
各指令对标志位的影响
cmpq Src2,Src1
Do substraction (Src1 - Src2) ,and set 4 flags above,but do nothing(like store in Dest)with the result
| Src1-Src2 | CF | ZF | SF | OF |
|---|
0|0|0|0|0
=0|0|1|0|0
(unsigned) cmpq 2,1|1|0|1|0
(signed) cmpq 2,1|1|0|1|0
(signed) cmpq INT_MAX,INT_MIN|0|0|0|1
小实验
//test.cpp #includeusing namespace std; int main() { unsigned int ua=1; unsigned int ub=2; unsigned int uc=0; uc=ua-ub; return 0; } g++ -g -DEBUG test.cpp #-g 保留行号 gdb a.exe (gdb) list #打印行号 (gdb) break 9 #在return前设置断点 (gdb) run #运行并停在第一个断点 (gdb) info registers eflags eflags 0x297 [ CF PF AF SF IF ] #中括号内Condition Code被置1
个人理解,只要符号位进位,CF便会 set
Src1+Src2|binary form|result|flags
-|-|-|-|-
I N T _ M I N 2 + I N T _ M I N 2 \frac {INT\_MIN}{2} + \frac {INT\_MIN}{2} 2INT_MIN+2INT_MIN|1100…00
+1100…00|(1)10…00|CF=1,SF=1,OF=0
I N T _ M I N 2 + I N T _ M I N 2 − 1 \frac {INT\_MIN}{2} + \frac {INT\_MIN}{2} - 1 2INT_MIN+2INT_MIN−1|1100…00
+1100…00
+1111…11|(1)011…1|CF=1,SF=0,OF=1
负+负=正 overflow
testq Src2,Src1
Like computing a & b without setting destination.
testq Src1, Src2 = Computing(Src1 & Src2) set eflags
SetX Instructions
Set low-order byte of destination to 0 or 1 based on combinations of condition codes,without changing remaining 7 bytes.
| Setx | Condition | set True if last result |
|---|---|---|
| sete | ZF | =0 |
| setne | ~ ZF | ≠ 0 \neq 0 =0 |
| sets | SF | <0 |
| setns | ~ SF | >=0 |
| setg | ~ (SF ^ OF)& (~ ZF) | > (signed) |
| setge | ~ (SF ^ OF) | >= (signed) |
| setl | (SF ^ OF) | < (signed) |
| setle | (SF ^ OF)| ZF | <= (signed) |
| seta | ~CF & ~ZF | Above (unsiged) |
| setb | CF | Below (unsigned) |
举例:
bool mycmp(long a,long b)
{
return a>b;
}
mycmp:
movl 8(%esp), %eax
cmpl %eax, 4(%esp)
setg %al
#movzbq %al, %eax #move with zero extension byte to quad
ret
x86-64’s(AMD)weird quirks
If result is 32 bits,remaining 32 bits will be zeroed,but other-length data type instruction won’t.
Jumping
jmp、je、jne、js、jns、jg、jge、jl、jle、ja、jb, same as setX.
举例:
long abs(long x,long y)
{
long result;
if(x>y)
result = x-y;
else
result = y-x;
return result;
}
>gcc -Og -S -fno-if-conversion test.cpp
abs: # only exist in assembly code,changing into address in object code
movl 4(%esp), %edx #x
movl 8(%esp), %eax #y
cmpl %eax, %edx # y, x
jg L14
subl %edx, %eax # y-x
ret
L14:
subl %eax, %edx # x-y
movl %edx, %eax
ret
Conditional Moves
指令重排:if-else两个分支结果都计算,最后再选择结果返回.
- 形如 if(test) Dest = Src,straightly simple computations.
- 95后 x86 processors支持.
- safe and no side effects.
>gcc -Og -S test.cpp #去掉-fno-if-conversion,gcc 默认允许指令重排
abs:
movq %rdi, %rax #x
subq %rsi, %rax #x=x-y
movq %rsi, %rdx #y
subq %rdi, %rdx #y=y-x
cmpq %rsi, %rdi #x-y
cmovle %rdx, %rax #if(x<=y)ret(y-x)
ret #result in %rax
Why:Branches are very disruptive to instruction flow through pipelines,Wasteful but more efficient.
See:pipelining、branch prediction.
只要branch prediction足够准确(98%),“管线“执行效率就会很高(提前20条指令)。
预测错误,回头重算,最多花费40时钟周期。
(gcc主动)避免进行指令重排的情况
- Expensive Computations in either branch.(如 找质因数)
- Risky Computations.(value = p ? (*p) : 0 ; //如 判断合法性)
- Computations with side effects. (value = x>0 ? x*=7 : x+=3; //如 都会改变X本身的值)
Loops
“Do-While” Loop
long popcount(unsigned long x)
{
long res=0;
do
{
res += x & 0x1;
x >>= 1;
}while(x);
return res;
}
popcount:
movl 4(%esp), %edx
movl $0, %eax
L12:
movl %edx, %ecx
andl $1, %ecx
addl %ecx, %eax
shrl %edx
jne L12
ret
“While” Loop
Test at the very beginning and skip the loop if condition doesn’t hold.
long popcount(unsigned long x)
{ ... while(x){...} ... }
popcount:
movl 4(%esp), %edx # x
movl $0, %eax
L13:
testl %edx, %edx
je L11
movl %edx, %ecx
andl $1, %ecx
addl %ecx, %eax
shrl %edx
jmp L13
L11:
ret
“For” Loop
for( Init; Test; Update)
body;
Semantics =
Init;
while(Test)
{ Body; Update; }
long popcount(unsigned long x)
{
size_t i=0;
long res=0;
for(i=0;i<32;i++)
{
res += x & 0x1;
x >>= 1;
}
return res;
}
>g++ -Og -S test.cpp
popcount:
pushl %ebx
movl 8(%esp), %ecx # x
movl $0, %eax # res=0
movl $0, %edx # i=0
L13:
cmpl $31, %edx # i>31
ja L11 # return
movl %ecx, %ebx
andl $1, %ebx # x & 1
addl %ebx, %eax # res += i
shrl %ecx # x >>= 1
addl $1, %edx # i += 1
jmp L13
L11:
popl %ebx
ret
提升编译优化等级-O1,无需initial test,转换为"do-while"循环。
>g++ -O1 -S test.cpp
popcount:
...
movl $32, %edx
movl $0, %eax
L4:
movl %ecx, %ebx
...
shrl %ecx
subl $1, %edx
jne L4
...
首次test非真,无循环。
popcount:
movl $0, %eax
ret
Switch Statements
- 条件变量必须是“整型“.
- 通过“Jump Table”的形式,将分支入口地址,按Case-Value大小排序,记录成表.
- 较紧凑 随机访问,时间复杂度O(1).
long switch_try(unsigned long x)
{
long res=0;
switch (x)
{
case 1:
res += 1;
break;
case 2:
res += 2;
case 3:
res *= 3;
break;
case 5:
case 4:
res -=1;
break;
case -1:
res *= -1;
break;
default:
res = 100;
}
return res;
}
switch_try:
movl 4(%esp), %eax # x
leal 1(%eax), %edx # case -1负数的情况,通过+偏置1转化为无符号数
cmpl $6, %edx # case 中最大值5,偏置后为6
ja L12 # 小技巧
# 用ja比较,小于-1的负数,偏置后仍为负数
# 在无符号数格式下,大于有符号数的正数范围,从而归属 defult
jmp *L14(,%edx,4) # Indirect jump,L14+4*(x+偏置) 的单元存储的值,作为jump地址
.section .rdata,"dr"
.align 4
L14: # Jump Table,compiler给结构,assembler(汇编器)填地址
.long L13 # need a long type value as address x=-1
.long L12 # x=0
.long L11 # x=1
.long L16 # x=2
.long L17 # x=3
.long L18 # x=4
.long L18 # x=5
.text
L17:
movl $0, %eax # x=3,res=0*3=0
L16: # x=2,res+=2,res==x,因此res用%eax表示 有优化
leal (%eax,%eax,2), %eax # res=2*3=6
ret
L13: # x=-1
movl $0, %eax # res=0*(-1)=0,compiler直接优化赋值0
ret
L18: # x=4
movl $-1, %eax
ret
L12: # default case
movl $100, %eax
L11: # x=1
rep ret # ja前已偏置+1,故直接返回%eax
- 稀疏(如 case [0、100])退化为if-else形式,时间复杂度O(n).
long switch_try(long x)
{
long res=0;
switch (x)
{
case 1:
res=0;
break;
case 100:
res=99;
break;
default:
res = -1;
}
return res;
}
switch_try:
movl 4(%esp), %eax
cmpl $1, %eax
je L13
cmpl $100, %eax
je L15
movl $-1, %eax
ret
L13:
movl $0, %eax
ret
L15:
movl $99, %eax
ret
- 较稀疏 使用二叉树,时间复杂度O( l o g 2 n log_2^{n} log2n).
Switch是否总时比if-else高效?根据以上分析,答案是否定的We are never happy with a simple explanation. We want to understand how we could actually implement it as a program if we ever had to do so.
3.5 Machine-Level Programming II:Procedures
ABI,Application Binary Interface,一种机器码层面的二进制程序接口协定。
- Passing control
- Beginning of procedure code
- Back to return point
- Passing data
- Procedure arguments
- Return value
- Memory management
- Allocate during procedure
- Deallocate upon return
One of main targets is doing whatever is omly absolutely needed.
Stack Structure
| Adress | Values Meaning |
|---|---|
| High Adress | (%rbp)Stack Bottom |
| … | |
| Low Adress | ( %rsp )Stack Top |
pushq Src
step 1:Fetch operand at Src(imediate or registers).
step 2:Decrement %rsp by 8.
step 3:Write operand at address given by %rsp.
popq Dest
step 1:Read value at address given by %rsp.
step 2:Increament %rsp by 8.
step 3:Store value at Dest(must be register).
Data at top of stack is stll there in the memory,but is no longer part of stack.
passing control
call label
step1:Push return address on stack,sp=sp-sizeof(address)
step2:Jump to label //%rip是不允许被显式操作的
ret
step1:Pop address(of next instruction right after call)from stack,sp=sp+sizeof(address)
step2:Jump to address
long sub_try(long x)
{
return x+1;
}
long call_try(long x)
{
return sub_try(x+1);
}
sub_try:
movl 4(%esp), %eax
addl $1, %eax
ret
call_try:
subl $4, %esp
movl 8(%esp), %eax
addl $1, %eax
movl %eax, (%esp)
call sub_try # sp=sp-4; *sp=addr after call
addl $4, %esp
ret
passing data
ABI规定
前6个整型入参用寄存器{ %rdi、%rsi、%rdx、%rcx、%r8、%r9 },6个之后的参数适用栈,返回值用 %rax。
long incr(long *p,long val)
{
long x=*p;
long y=x+val;
*p=y;
return x;
}
long call_incr()
{
long v1=15213;
long v2=incr(&v1,3000);
return v1+v2;
}
incr:
movl 4(%esp), %edx # dx=*(-28+4)=-4
movl (%edx), %eax # ax=*(-4)=15213
movl %eax, %ecx # cx=ax
addl 8(%esp), %ecx # cx=cx+*(-20)=15213+3000
movl %ecx, (%edx) # *(-4)=18213
ret # sp=sp+4=-24
call_incr: # 设sp=0 <--- start
subl $24, %esp # sp=-24 分配24字节空间
movl $15213, 20(%esp)# *(-4)=15213
movl $3000, 4(%esp) # *(-20)=3000
leal 20(%esp), %eax # ax=-4
movl %eax, (%esp) # *(-24)=-4
call incr # sp=sp-4=-28,4字节返回地址入栈
addl 20(%esp), %eax # ax=15213+*(-4)=15213+18213
addl $24, %esp # sp=0 清空栈
ret
浮点型入参使用一组特殊的寄存器。
函数的本地临时变量为什么比入参的引用更高效?因为临时变量用寄存器,而引用需要解引用,或间接寻址,相对低效
- 必须给 Local Data 分配内存的几种情况:
- 寄存器不够用
- 对Local Variable 应用了 ‘&’(address operator),寄存器没有地址,只能用内存表示
- Local variable 是数组或结构体
Memory management
- Code must be “Reentrant”
- Multiple simultaneous instantiations of single procedure
- Need place to store state of each instantiation
- Arguments
- Local variables
- Return pointer
stack fame :Each block we use for particular call。
发生调用时:
- [Caller 栈帧 call 指令] sp = sp - sizeof( Addr )
- [Caller 栈帧 call 指令] 将Return Addr 写入 sp 指向的栈帧尾部
- [Callee 栈帧] sp = sp - frame size,分配 Calle 栈帧
- [Callee 栈帧] 基于sp寻址,由高到低地址先后保存 Registers(即 Callee Save),局部变量等
- [Callee 栈帧] sp = sp + frame size,准备返回 Caller
- [Caller 栈帧 ret 指令] 将 sp 指向的 Return Addr 返回给 ip
- [Caller 栈帧 ret 指令] sp = sp + sizeof( Addr )
- [Caller 栈帧] ret 执行完毕,开始执行 Caller 返回点命令
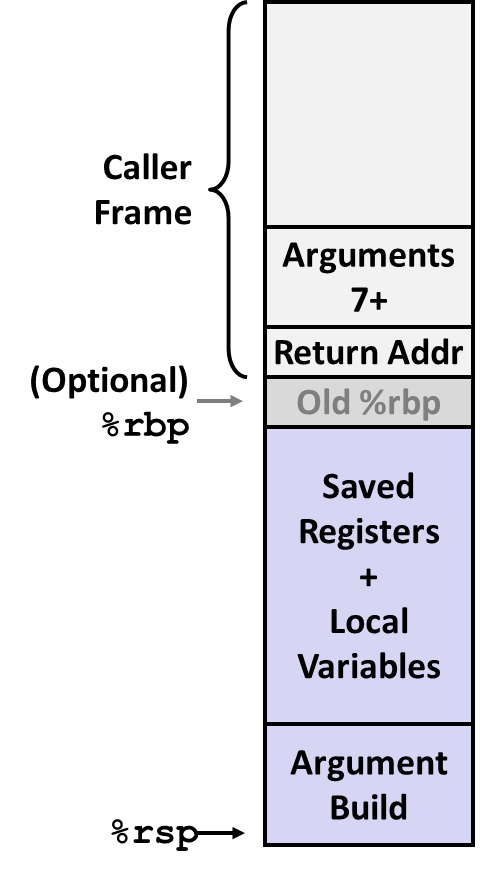
P calls Q,Arguments > No.6存在P帧中。
大多数系统限制了栈的最大深度。
%rbp 作为 frame pointer。
某些情况下%rbp会用于记录 caller的栈帧底。
《CS:APP(Third.Ed)》英文版 P.286
void proc(long a1, long *a1p, int a2, int *a2p, short a3, short *a3p, char a4, char *a4p)
{
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}
long call_proc()
{
long x1 = 1;
int x2 = 2;
short x3 = 3;
char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, &x4);
return (x1+x2)*(x3-x4);
}
call_proc: # callee save
subq $32, %rsp # Allocate 32-byte stack frame
movq $1, 24(%rsp) # Store 1 in &x1
movl $2, 20(%rsp) # Store 2 in &x2
movw $3, 18(%rsp) # Store 3 in &x3
movb $4, 17(%rsp) # Store 4 in &x4
leaq 17(%rsp), %rax # Create &x4
movq %rax, 8(%rsp) # Store &x4 as argument 8
movl $4, (%rsp) # Store 4 as argument 7
leaq 18(%rsp), %r9 # Pass &x3 as argument 6
movl $3, %r8d # Pass 3 as argument 5
leaq 20(%rsp), %rcx # Pass &x2 as argument 4
movl $2, %edx # Pass 2 as argument 3
leaq 24(%rsp), %rsi # Pass &x1 as argument 2
movl $1, %edi # Pass 1 as argument 1
call proc
movslq 20(%rsp), %rdx # Get x2 and convert to long
addq 24(%rsp), %rdx # Compute x1+x2
movswl 18(%rsp), %eax # Get x3 and convert to int
movsbl 17(%rsp), %ecx # Get x4 and convert to int
subl %ecx, %eax # Compute x3-x4
cltq # Convert to long
imulq %rdx, %rax # Compute (x1+x2) * (x3-x4)
addq $32, %rsp # Deallocate stack frame
ret # Return
proc:
movq 16(%rsp), %rax
addq %rdi, (%rsi)
addl %edx, (%rcx)
addw %r8w, (%r9)
movl 8(%rsp), %edx
addb %dl, (%rax)
ret
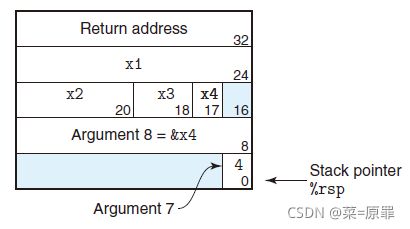
- [ABI Conventions] 程序都约定俗成的遵守:
- “Caller Saved” 假设使用到的寄存器的值会被Callee覆写,Caller先保存
%rax、%rdi、%rsi、%rdx、%rcx、%r8、%r9、%r10、%r11等 - “Callee Saved” 想用寄存器?先入栈保存,ret前先出栈,“物归原主”,Caller畅用寄存器
%rbx、%12、%13、%14、special { %rbp、%rsp }
- “Caller Saved” 假设使用到的寄存器的值会被Callee覆写,Caller先保存
“Callee Saved” 的情况较多
《CS:APP(Third.Ed)》英文 P.288
long P(long x, long y)
{
long u = Q(y);
long v = Q(x);
return u + v;
}
P:
pushq %rbp # Save %rbp | Callee-Saved
pushq %rbx # Save %rbx
subq $8, %rsp # Align stack frame
movq %rdi, %rbp # Save x | Caller-Saved
movq %rsi, %rdi # Move y to first argument
call Q # Call Q(y)
movq %rax, %rbx # Save result
movq %rbp, %rdi # Move x to first argument
call Q # Call Q(x)
addq %rbx, %rax # Add Q(y) to Q(x), believe rbp not changed before & after Q
addq $8, %rsp # Deallocate last part of stack
popq %rbx # Restore %rbx 注意先进后出,变量出栈反入栈顺序
popq %rbp # Restore %rbp
ret
Illustration of Recursion
视频例题
unsigned long pcount_r(unsigned long x)
{
if (x==0)
return 0;
else
return (x & 1) + pcount_r(x >> 1);
}
pcount_r:
pushl %ebx # *sp = ebx; sp = sp-4;
subl $24, %esp # sp = sp-24;
movl 32(%esp), %eax # eax = *(sp+32) = x;
testl %eax, %eax #
jne L14 # if(eax != 0) goto L14;
L12:
addl $24, %esp # sp = sp+24;
popl %ebx # sp = sp+4; ebx = *sp;
ret
L14:
movl %eax, %ebx # ebx = eax;
andl $1, %ebx # ebx = ebx & 1;
shrl %eax # eax >> 1;
movl %eax, (%esp) # *sp = eax;
call pcount_r #
addl %ebx, %eax # eax = eax + { ebx = (x & 1)}
# eax 并没有被push,最后一层callee返回时eax = 0
jmp L12
echo "eax即作为输入参数,最in的一层callee中变0后又作为输出暂存,实在是妙啊!!!"
- 栈帧 让每次函数调用 能够存储临时变量,寄存器,和返回地址;
- 栈的先进后出,call / return的变量保护原则,保证层层调用中的数据安全性,除非overflow;
- 相互递归(mutual recursion,P calls Q,Q calls P)同样适用;
3.6 Machine-Level Programming IV:Data
3.6.1 Array
对于复杂的数据结构,建议拆分用typedef多次嵌套定义,明晰结构
//声明大小为5的数组,元素是函数指针,函数入参为(int),返回值为int指针
int *(*a[5])(int);
//使用typedef简化声明
typedef int *(*pFun)(int);
pFun a[5];
//声明大小为5的数组,元素是A类函数指针,A类函数入参为B类函数指针,B类函数无入参,无返回值
int *(*b[5])(void(*)(void));
//使用typedef分两步简化声明
typedef void(*pVoidFunc)(void); //定义函数类型B
typedef int *(*pFunc)(pVoidFunc);
pFunc b[5];
注意typedef是存储类关键字(如 static、auto、mutable、register等)
typedef static int STCINT;
>> 编译报错"一个以上的存储类"
汇编程序员期望一种看似高级语言,但又留有汇编层面灵活性、可玩性(技巧层面),C语言诞生。
之前操作系统都是用汇编写的(=͟͟͞͞=͟͟͞͞(●⁰ꈊ⁰● |||)),Kernighan、Dennis Ritchie等人为实现灵活性,在创造C时引入了指针操作。
在继续探讨指针前需要注意:
int main()
{
int *p=NULL;
cout << sizeof(p)<<endl; // = 4
return 0;
}
int类型的指针大小为4,说明并不是64位地址。使用 gcc -v 查看后醒悟使用的是32位编译器,赶紧切换64位
>> gcc -v
...
Target: x86_64-w64-mingw32
...
int main()
{
int *p=NULL;
cout << sizeof(p)<<endl;
int a[8]={0};
cout<<"\nsizeof(a)"<<sizeof(a)<<"\n" // = 32
<<"\nsizeof(a[0])"<<sizeof(a[0])<<"\n" // = 4 a[0]=*(a+0)
<<"\nsizeof(*a)"<<sizeof(*a)<<"\n"<<endl; // = 4
int b[2][3]={0};
cout<<"\nsizeof(b)"<<sizeof(b)<<"\n" // = 24
<<"\nsizeof(b[0])"<<sizeof(b[0])<<"\n" // = 12 b[0]=*(b+0)
<<"\nsizeof(*b)"<<sizeof(*b)<<"\n" // = 12
<<"\nsizeof(b[1][1])"<<sizeof(b[1][1])<<"\n" // = 4 b[1][1]=*(b[1]+1)
<<"\nsizeof(*b[1])"<<sizeof(*b[1])<<"\n"<<endl; // = 4
cout <<a<<"=?="<<&a<<endl; // 0x61fdf0=?=0x61fdf0
cout <<b[1]<<"=?="<<b[0]<<":"<<b[1]-b[0]<<endl; // 0x61fddc=?=0x61fdd0:3
b[0][1]=1;
b[1][0]=2;
cout <<*b[1]<<endl; // *b[1] = 2 = *(*(b+1)),说明 '[]' 优先级> '*'
return 0;
}
二维数组的结构 = 数组{数组指针1、数组指针2、…},而数组指针1指向数组{元素1、元素2、…},且二维数组是一段地址连续的空间,视频里将这种数组称作 Nested array。

以下举例说明,非直接声明的二维数组,分配的空间地址并不连续,视频里将这种数组称作 Multi-level array。
int get_ele(int arr[3][3],size_t r,size_t c)
{
return arr[r][c];
}
int main()
{
int a1[3]={1,2,3},a2[3]={4,5,6},a3[3]={7,8,9};
int *(arr[3])={a1,a2,a3};
cout<<arr[2]<<"\n" // 0x61fdfc
<<arr[1]<<"\n" // 0x61fe08
<<arr[2]-arr[1]<<"\n" // -3
<<(char*)(arr[2])-(char*)(arr[1])<<endl; // -12
int arr2[3][3]={0};
cout<<arr2[2]<<"\n" // 0x61fdc8
<<arr2[1]<<"\n" // 0x61fdbc
<<arr2[2]-arr2[1]<<"\n" // 3
<<(char*)(arr2[2])-(char*)(arr2[1])<<endl; // 12
get_ele(arr2,1,2);
return 0;
}
get_ele:
leaq (%rdx,%rdx,2), %rdx # rdx = rdx + 2*rdx = 3*rdx
leaq 0(,%rdx,4), %rax # rax = 4 * rdx
addq %rax, %rcx # rcx = rcx + 12 * r
movl (%rcx,%r8,4), %eax # eax = *(rcx + j * 4)
ret
Nested Array 和 Multi-Level Array 在汇编层面完全不同:
Nested Array 因为空间连续,只需要一次Memory Reference就能拿到元素:
N A [ i n d e x ] [ d i g i t ] = ∗ ( N A + i n d e x ⋅ c o l ⋅ s i z e o f ( e l e m ) + d i g i t ⋅ s i z e o f ( e l e m ) ) NA[index][digit]=*(NA+index \cdot col \cdot sizeof(elem) + digit \cdot sizeof(elem)) NA[index][digit]=∗(NA+index⋅col⋅sizeof(elem)+digit⋅sizeof(elem))
Multi-Level Array 需要两次Memory Reference,第一次拿数组指针,第二次拿元素:
M A [ i n d e x ] [ d i g i t ] = ∗ ( ∗ ( M A + i n d e x ⋅ s i z e o f ( p o i n t e r ) ) + d i g i t ⋅ s i z e o f ( e l e m ) ) MA[index][digit]=*(*(MA+index \cdot sizeof(pointer)) + digit \cdot sizeof(elem)) MA[index][digit]=∗(∗(MA+index⋅sizeof(pointer))+digit⋅sizeof(elem))
3.6.2 Structure
- 编译器构建空间,处理(一段连续)地址,汇编代码不会体现;
- 定义决定"域"的先后顺序,不会因为对齐或紧凑而调换位置。
struct A
{
int a[4];
int i;
struct A *next;
};
void set_val(struct A* pA, int val)
{
while(pA)
{
pA->a[pA->i]=val;
pA=pA->next;
}
}
set_val: # rcx := pA, rax := i, edx := val
L7:
testq %rcx, %rcx
je L5
movslq 16(%rcx), %rax # 4 byte value and do sign extension
movl %edx, (%rcx,%rax,4)
movq 24(%rcx), %rcx # 注意这里next相对A的起始地址偏移24
jmp L7
L5:
ret
注意这里 next 相对 A的起始地址偏移24,是因为数据对齐,i 之后留4空字节(padding bytes),对齐8字节。现代计算机内存通常一次取64个字节,如果存储对象因为地址没有对齐,横跨两个64字节块,将导致系统花费很多额外的步骤来"拼数据"。x86系统下没有对齐只会导致运行速度变慢,其他系统可能直接就内存错误。
- 结构体成员大小为 k Bytes,则该成员的起始地址应为 k 的整数倍
- 结构体“最大”成员 K Bytes,结构体总大小为 K 的整数倍(末尾补空字节)字段
与其声明__attribute__((packed))强制编译器不对齐,不如定义结构体"大"Field在前,"小"Field在后,来减少浪费的 Padding Bytes。
对齐只针对原始数据类型(char、short、int…),汇编层面不存在“聚合类数据”(数组、结构体…)。
3.6.3 Floating Point
- 8087 – masterpiece of engineering,单个芯片,具备了实现IEEE浮点数所需的全部硬件,co-developed with IEEE浮点标准x87 FP,但编程模型实在糟糕因此被踢出了教材
- SSE FP,special case use of vector instructions
- AVX FP,Newest version,similar to SSE
- XMM Register
{XXM0、…XXM15}共16个,每个16字节,按需可作为16个char,8个short,4个int,4个float,2个double,1个double long。虽然数据种类不同,但可以将作用这些数据的操作方法合并为一种高级的抽象实现。这些寄存器都是caller-saved。
Scalar Operation
addss = add for scalar single precision
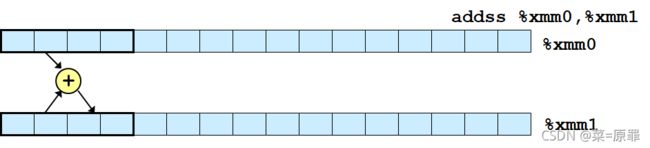 SIMD(single instruction multiple data)Operation
SIMD(single instruction multiple data)Operation
addps = add for pack single precision

整型使用regular registers,浮点型使用XXM registers,当然也可以都使用XXM提高运算速度就是有点浪费 。传参时整型与浮点型交错按规矩依次入座
double double_test(float *pd, float Val)
{
float x=*(pd);
if(Val>x)
*pd=x+Val;
return x;
}
double_test:
movss (%rcx), %xmm0
comiss %xmm0, %xmm1
jbe .L6
addss %xmm0, %xmm1
movss %xmm1, (%rcx)
.L6:
cvtss2sd %xmm0, %xmm0
ret
3.6 Machine-Level Programming V:Advanced Topics
miscellaneous topics
3.6.1 Memory Layout
目前64位系统只使用了47位地址,约 256 × 1 0 12 256 \times 10^{12} 256×1012字节约256 Terabytes。
Terabytes << Petabytes << Exabytes(Google累计信息总量) << Zettabyte(全人类信息总量)
| HEX Address | Content | note |
|---|---|---|
| 00007FFFFFFFFFFF | Stack | 0x7FFFFFFFFFFF -0x7FFFFF7FFFFF = 2 23 2^{23} 223 = 8M |
| 00007FFFFF7FFFFF | ||
| Shared Libraries | Executable machine instructions,read only | |
| Heap | Dynamically allocated as needed when malloc()、calloc()、new() Address moving up |
|
| Data | Statically allocated data global vars、static vars、const string |
|
| Text | Executable machine instructions,read only | |
| 400000 |
表格自2015年Slider,2020年Slider中,Shared Libraries 处于最高地址,高于Stack。
Cent OS 环境下可使用 ulimit -a 查看全部系统限制:
[root@VM-4-10-centos]# ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14819
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 100001
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 14819
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
观察分配地址:
#include Cent OS 结果
[root@VM-4-10-centos]# ./a.out
stack_local_arr: 0x7ffe44a783d0
stack_local_arr_last: 0x7ffe44a78420 // 栈地址始终高于堆地址
stack_pc: 0x8abf10 // 地址高于pc,堆按需分配,地址递增
stack_pc_last: 0x8abf60
local_val: 0x7ffe44a7849c
local_arr: 0x7ffe44a78440 // 地址高于stack_local_arr,栈帧地址递减
local_arr_last: 0x7ffe44a78490
pc: 0x8abeb0 // 堆内、栈帧内数组元素地址递增
pc_last: 0x8abf00 // < stack_pc= 0x8abf10
global_var: 0x6021d0
global_arr: 0x602180
global_arr_last: 0x6021d0
Main: 0x400bde
Memory_obs: 0x4009f1 //text 可执行指令始终处于最低地址
Win64 环境下堆地址居然高于栈地址?Whatever
>>PS C:Users> .\a.exe
stack_local_arr: 0x61fcb0
stack_local_arr_last: 0x61fd00
stack_pc: 0xec1680
stack_pc_last: 0xec16d0
local_val: 0x61fdac
local_arr: 0x61fd50
local_arr_last: 0x61fda0
pc: 0xec1620
pc_last: 0xec1670
global_var: 0x408090
global_arr: 0x408040
global_arr_last: 0x408090
Main: 0x40182f
Memory_obs: 0x401656
3.6.2 Buffer Overflow
Exceeding the memory size allocated for an array,potentially that risk of being a vulnerability.
Most come from (culprit)
- Unchecked lengths on string inputs,worst one ⇒ gets()
- Particularly for bounded character arrays on stack
gets()编写于1970s,UNIX刚发行,那时人们还不怎么考虑安全问题。
// kind of implementation of Unix function gets()
char *gets(char *dest)
{
int c = getchar(); //EOF 应该是整型,char可能不够大
char *p = dest;
while(c! = EOF && c !='\n')
{
*p++ = c;
c = getchar();
}
*p='\0';
return dest;
}
Others like strcpy、strcat、scanf(%s)、sscanf、fscanf,they all have no idea what limit is on number of characters to read. Typically,return address should be overwrite first.
- Input sting contains byte representation of executable code
- Overwrite return address A with address of buffer B
- When callee return,exploit code injected within gets() will be executed.
二进制层面的注入,与SQL数据库注入不同。
- Original “Morris worm” (1988)
finger user@host
finger 命令使用 gets() 接收信息
finger “exploit-code padding new-return-address”,exploit-code = excuted root shell on victim machine with a direct TCP connection to the attacker.
CERT computer emergency response team 就此成立并安家CMU
- “IM wars” (1999)
AOL 聊天软件客户端存在注入漏洞,AOL注入测试PC是不是Microsoft平台,达到 Block MS 的目的,More than 10 skirmishes between MS and AOL
- Twilight hack on wii (2000s)
- …
Worms and Viruses
- Worm
- Run by itself
- Propagate a fully working version of itself to other computers
- Virus
- Adds itself to other programs
- Does not run independently,work as changing behavior of program
Protection
- Avoid overflow vulnerabilities
- fgets() instead of gets()
- strncpy() instead of strcpy()
- scanf(“%ns”) instead of scanf(“%s”)
- Employ system-level protections
- ASLR,Address Space Layout Randomization,随机分配栈大小
- Nonexecutable code segments,硬件工程师配合实现, 显式指定内存段可执行权限(AMD 先行,Intell跟上)
- Stack Canaries (使用这种策略都可以叫 “xx金丝雀”,名字来源美国早期煤矿工人带雀下矿)
- 栈上缓冲区(Buffer)尾部接常量,ret前检查这个常量是否被改动
- GCC implementation,-fstack-protector(default,但gcc 8.4.1实验中没有发现Canary保护)
假设 ret_orit 是一个库函数
int ret_orit(int a,int b)
{
return a+b;
}
0000000000401596 <ret_orit>:
401596: 8d 04 11 lea (%rcx,%rdx,1),%eax
401599: c3 retq
Gadget address = 0x401596,完成了 %eax = %rcx + %rdx 动作。
有趣的是,在X86架构中,ret指令以 0xc3 结尾,那就很容找到这些片段的位置了。
假设我们始终取 0xc3 的 前三个字节 凑指令:
void ret_orit(int *p)
{
*p=0x11048d22;
return;
}
0000000000401596 <ret_orit>:
401596: c7 01 22 8d 04 11 movl $0x11048d22,(%rcx)
40159c: c3 retq
Gadget address = 0x401599,三个字节0x8d、0x04、0x11同样完成了 %eax = %rcx + %rdx 。
“Just match the byte patterm of some existing code.”
- 有了前两种方法,剩下只需要组合这些 Gadget:
| Address | Content |
|---|---|
| stack | address of Gadget n code |
| … | … |
| %rsp | address of Gadget 1 code (used to be callee return address) |
| 通过缓冲区溢出,将callee return address 及 其后的所有地址,依次替换为 Gadget 的地址,则跳转执行 Gadget 命令后,Gadget 最后的 ret 指令又使得 %rip 从 %rsp - 8 取下一条 Gadget 的地址,再 ret,再跳转 … 直到完成攻击。 |
3.6.3 Unions
A way to ceate an alias that will let you refrence memory in different ways.
联合体并不改变实际位,只改变解读位的方式。
#include 通过 Union 很容易了解到机器的 Byte Ordering
Big Endian 最大的在尾端(地址最低)
Little Endian 最小的在尾端(地址最低)x86、ARM、IOS
Bi Endian 大小端都行