机器学习-0基础
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 0基础机器学习
-
- 一、什么是机器学习
- 二、学习软件
-
- python
- 三、如何学
- 1.载入数据与理解数据
-
- 1.1导入数据
- 1.2数据查看
- 2.数据准备与特征过程
-
- 1.2数据预处理-缺省值-异常值
- 异常值:
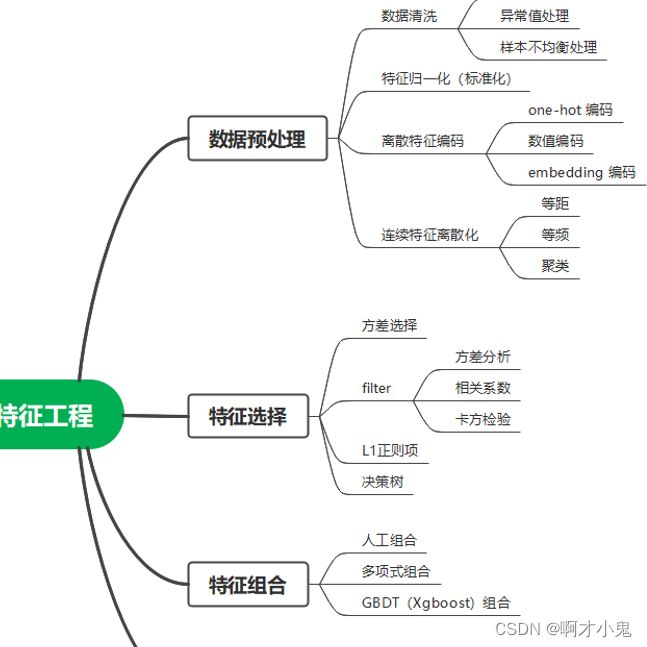
- 3特征工程
- 模型与优化
-
- sklearn中模型的常用方法
- sklearn 中的模型
-
-
- 线性回归
- 逻辑回归
- 朴素贝叶斯算法NB
- 决策树DT
-
- 结果部署
-
-
- 模型持久化
- 模型的序列化
- 模型部署
-
- 总结
0基础机器学习
一、什么是机器学习
机器学习 ( ML )是人工智能的应用程序,计算机程序使用算法来查找数据中的模式。他们可以在没有专门编程的情况下做到这一点,而不需要依赖人类。在当今世界,机器学习算法几乎落后于市场上的所有人工智能 (AI) 技术进步和应用程序。
人工智能系统通常具有计划、学习、推理、解决问题、感知、移动甚至操纵的能力。机器学习是人工智能系统中使用的众多方法之一。其他包括进化计算和专家系统。
二、学习软件
python
介绍:
- Python是一种高级编程语言,具有简单易学、可读性强和灵活性等特点。它于1991年由Guido van Rossum创建,并成为一种广泛使用的编程语言。Python的设计目标是提供一种清晰简洁的语法和强大的功能,使开发者能够更快、更高效地编写代码
2.学习Python基础知识:如果你还不熟悉Python语言,建议首先学习Python的基本语法、数据类型、流程控制等。
- 掌握科学计算库:Python有一些流行的科学计算库,如NumPy、Pandas和Matplotlib等,它们对于机器学习非常有用。学习这些库的基本用法,包括数据处理、数组操作和可视化等。
- 选择机器学习库:Python有多个优秀的机器学习库可以选择,如Scikit-learn、TensorFlow和PyTorch等。这些库提供了丰富的算法和工具,用于构建和训练机器学习模型。选择一个适合你的项目和学习目标的库,并学习其基本概念和用法。
三、如何学
1.载入数据与理解数据
- 明确数据获取和数据理解的工作过程
- 掌握数据加载和读取(从平面文件、数据库……)的方法
- 通过观察数据的概览、数据可视化等工具,对数据进行理解
1.1导入数据
- 常见的csv,txt,excel以及数据库mysql中的文件读取
import pandas as pd
data = pd.read_csv(r'../filename.csv') #读取csv文件
data = pd.read_table(r'../filename.txt') #读取txt文件
data = pd.read_excel(r'../filename.xlsx') #读取excel文件
# 获取数据库中的数据
import pymysql
conn = pymysql.connect(host='localhost',user='root',passwd='12345',db='mydb') #连接数据库,注意修改成要连的数据库信息
cur = conn.cursor() #创建游标
cur.execute("select * from train_data limit 100") #train_data是要读取的数据名
data = cur.fetchall() #获取数据
cols = cur.description #获取列名
conn.commit() #执行
cur.close() #关闭游标
conn.close() #关闭数据库连接
col = []
for i in cols:
col.append(i[0])
data = list(map(list,data))
data = pd.DataFrame(data,columns=col)
1.2数据查看
data.head() #显示前五行数据
data.tail() #显示末尾五行数据
data.info() #查看各字段的信息
data.shape #查看数据集有几行几列,data.shape[0]是行数,data.shape[1]是列数
data.describe() #查看数据的大体情况,均值,最值,分位数值...
data.columns.tolist() #得到列名的list
2.数据准备与特征过程
1.2数据预处理-缺省值-异常值
- 缺失值
现实获取的数据经常存在缺失,不完整的情况(能有数据就不错了,还想完整!!!),为了更好的分析,一般会对这些缺失数据进行识别和处理 - 缺失值查看
print(data.isnull().sum()) #统计每列有几个缺失值
missing_col = data.columns[data.isnull().any()].tolist() #找出存在缺失值的列
import numpy as np
#统计每个变量的缺失值占比
def CountNA(data):
cols = data.columns.tolist() #cols为data的所有列名
n_df = data.shape[0] #n_df为数据的行数
for col in cols:
missing = np.count_nonzero(data[col].isnull().values) #col列中存在的缺失值个数
mis_perc = float(missing) / n_df * 100
print("{col}的缺失比例是{miss}%".format(col=col,miss=mis_perc))
- 缺失值处理
删除:
data.dropna(axis=0,how="any",inplace=True) #axis=0代表'行','any'代表任何空值行,若是'all'则代表所有值都为空时,才删除该行
data.dropna(axis=0,inplace=True) #删除带有空值的行
data.dropna(axis=1,inplace=True) #删除带有空值的列
3.填充:
data = data.fillna(0) #缺失值全部用0插补
data['col_name'] = data['col_name'].fillna('UNKNOWN')
#某列缺失值用固定值插补
3.1出现最频繁值填充:
freq_port = data.col_name.dropna().mode()[0] # mode返回出现最多的数据,col_name为列名
data['col_name'] = data['col_name'].fillna(freq_port) #采用出现最频繁的值插补
3.2中位数/均值插补:
data['col_name'].fillna(data['col_name'].dropna().median(),inplace=True) #中位数插补,适用于偏态分布或者有离群点的分布
data['col_name'].fillna(data['col_name'].dropna().mean(),inplace=True) #均值插补,适用于正态分布
3.3中位数/均值插补:
data['col_name'] = data['col_name'].fillna(method='pad') #用前一个数据填充
data['col_name'] = data['col_name'].fillna(method='bfill') #用后一个数据填充
4.拉格朗日插值法:
一般针对有序的数据,如带有时间列的数据集,且缺失值为连续型数值小批量数据
from scipy.interpolate import lagrange
#自定义列向量插值函数,s为列向量,n为被插值的位置,k为取前后的数据个数,默认5
def ployinterp_columns(s, n, k=5):
y = s[list(range(n-k,n)) + list(range(n+1,n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值
data[i][j] = ployinterp_columns(data[i],j)
5.其它插补方法
最近邻插补、回归方法、牛顿插值法、随机森林填充等。
异常值:
异常值是指样本中的个别值,其数值明显偏离它所属样本的其余观测值。异常值有时是记录错误或者其它情况导致的错误数据,有时是代表少数情况的正常值
- 描述性统计法
neg_list = ['col_name_1','col_name_2','col_name_3']
for item in neg_list:
neg_item = data[item] < 0
print(item + '小于0的有' + str(neg_item.sum())+'个')
#删除小于0的记录
for item in neg_list:
data = data[(data[item]>=0)]
- 三西格玛法
当数据服从正态分布时,99.7%的数值应该位于距离均值3个标准差之内的距离,P(|x−μ|>3σ)≤0.003
#当数值超出这个距离,可以认为它是异常值
for item in neg_list:
data[item + '_zscore'] = (data[item] - data[item].mean()) / data[item].std()
z_abnormal = abs(data[item + '_zscore']) > 3
print(item + '中有' + str(z_abnormal.sum())+'个异常值')
- 箱型图
#IQR(差值) = U(上四分位数) - L(下四分位数)
#上界 = U + 1.5IQR
#下界 = L-1.5IQR
for item in neg_list:
IQR = data[item].quantile(0.75) - data[item].quantile(0.25)
q_abnormal_L = data[item] < data[item].quantile(0.25) - 1.5*IQR
q_abnormal_U = data[item] > data[item].quantile(0.75) + 1.5*IQR
print(item + '中有' + str(q_abnormal_L.sum() + q_abnormal_U.sum())+'个异常值')
- 其它
基于聚类方法检测、基于密度的离群点检测、基于近邻度的离群点检测等。
3特征工程
当你想要你的预测模型性能达到最佳时,你要做的不仅是要选取最好的算法,还要尽可能的从原始数据中获取更多的信息。那么问题来了,应该如何为你的预测模型得到更好的数据呢?
想必到了这里你也应该猜到了,是的,这就是特征工程要做的事,它的目的就是获取更好的训练数据。
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
简而言之,特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。从数学的角度来看,特征工程就是人工地去设计输入变量X。
特征工程更是一门艺术,跟编程一样。导致许多机器学习项目成功和失败的主要因素就是使用了不同的特征。
模型与优化
sklearn中模型的常用方法
- sklearn中所有的模型都有四个固定且常用的方法,分别是model.fit、model.predict、model.get_params、model.score。
# 用于模型训练
model.fit(X_train, y_train)
# 用于模型预测
model.predict(X_test)
# 获得模型参数
model.get_params()
# 进行模型打分
model.score(X_test, y_test)
- 模型的生成和拟合
以 KMeans 模型为例:
clf=KMeans(n_clusters=5) #创建分类器对象
fit_clf=clf.fit(X) #用训练器数据拟合分类器模型
clf.predict(X) #也可以给新数据数据对其预测
print(clf.cluster_centers_) #输出5个类的聚类中心
y_pred = clf.fit_predict(X) #用训练器数据X拟合分类器模型并对训练器数据X进行预测
print(y_pred) #输出预测结果
sklearn 中的模型
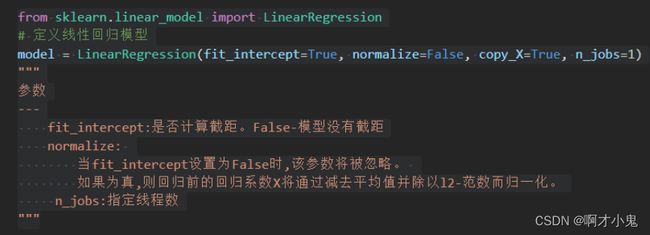
线性回归
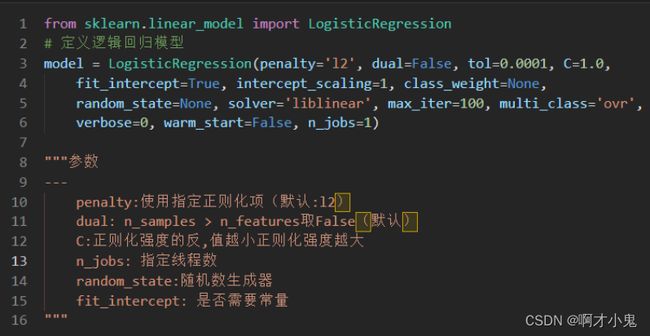
逻辑回归
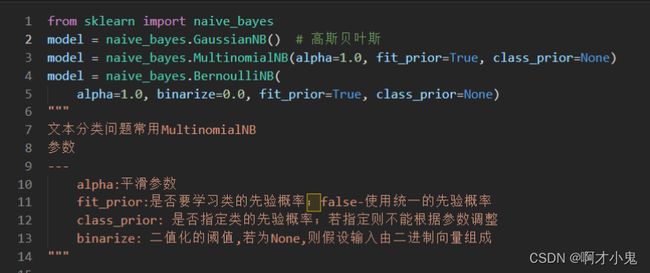
朴素贝叶斯算法NB
决策树DT
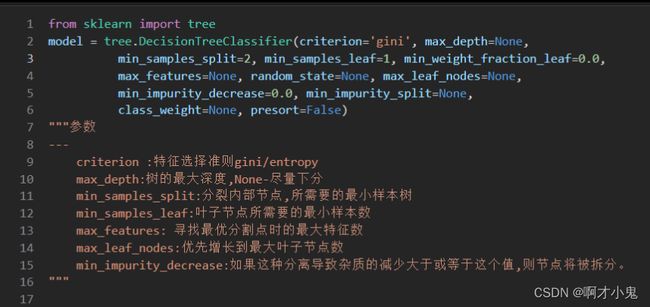
结果部署
模型持久化
**模型持久化的意思是当我们训练完一个模型以后,用一种特定的方式将模型训练结果保存下来,以便在应用中直接调用,模型持久化的格式基本分为以下几种:
python专有格式pickle
通用交换格式(如PMML/ONNX)
第三方机器学习流程框架(如MLflow)**
通用交换格式:
常见的两种格式是Open Neural Network Exchange(ONNX)和Predictive Model Markup Language(PMML)。
模型的序列化
-
使用 Pickle
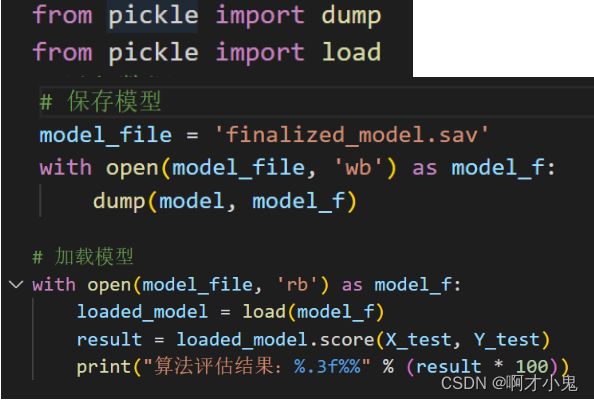
-
使用sklearn 中的externals
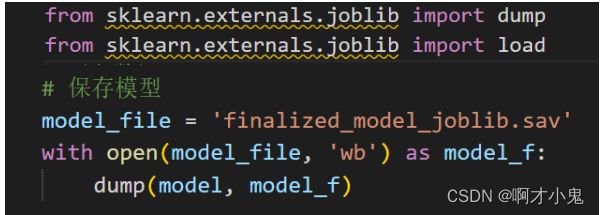
模型部署
模型部署方案的选择是便捷性和灵活性之间的权衡。按照从简单到复杂,有四种通用的部署方式。
离线预测
模型内嵌于应用
以API方式发布
实时推送模型数据
第一种方式最简单,也是唯一一种离线部署的方式,有点像通常的ETL流程,设置定时任务每天定期收集完新数据并进行预测,之后写入数据库中供查询使用。这种方式适用于对实时性要求不高的场景。
第二种方式是模型内嵌于应用,例如你已经有了一个完整的应用,此时模型时作为应用的一个部分(或功能)发布,这种方式虽然可以做到实时预测,但是模型的更新较为麻烦,涉及到整个应用的部署,以及不同部分之间的兼容性。
第三种方式是以API的形式发布,通过这种方式部署最大的好处是将模型侧和应用侧分离开了,扩展性和维护性都得到了提升,缺点是结构更复杂了,需要专门维护API接口和其通信过程。
第四种方式最为复杂,将模型以类似数据的方式发布到流平台(如kafka),应用侧以消费模型的方式进行模型的调用和预测,这种方式几乎可以做到模型的无缝升级和切换,但代价是需要额外维护一个流平台架构。
总结
这只是部分机器学习的一下方法和理解,要多次手动尝试去学习才能够进阶的了解机器学习内容。
今天就分享到这里,谢谢大家的参考!