linux 服务器下搭建 Kubernetes(公网环境)
文章目录
- 前言
- 一、环境准备
-
- 1.1、服务器准备
- 1.2、服务器hostname设置
- 1.3、添加hosts 网络主机配置,三台服务器都要设置
- 1.4、关闭防火墙,设置开机禁用防火墙,三台服务器都要设置
- 1.5、关闭selinux,关闭swap,三台服务器都要设置
- 1.6、同步时间,三台服务器都要设置
- 二、安装docker
-
- 2.1.配置docker repo文件
- 2.2.选择你需要的版本进行安装
- 2.3.已安装docker下可直接修改版本
- 2.4.开机自启动docker及运行docker服务
- 三、安装k8s工具(所有节点全部执行)
-
- 3.1.添加kubernetes yum源
- 3.2.查看kubeadm版本
- 3.3.安装 kubeadm, kubelet 和 kubectl
- 四.启动k8s(master节点执行)
-
- 4.1.初始化master节点(注意:192.168.0.01修改为自己的master节点ip,kubernetes版本改成自己的,其他忽动)
- 4.2.使用 kubectl 工具
- 4.3.检查master节点
- 4.4.安装pod网络插件
- 4.5.如果token过期重新获取token
- 五.集群配置
-
- 5.1.子节点加入集群(子节点执行)
- 5.2.检查节点是否加入集群 (master节点执行)
- 5.3.创建pod (master节点执行)
- 六.安装k8s的控制面板(master节点)
-
- 6.1.安装dashboard
- 6.2.配置外网访问,官网提供代理proxy、port-forward、NodePort三种方法。这里使用NodePort方式(默认Dashboard只能集群内部访问)
- 6.3.查看安装节点
- 6.3.查看web页面
- 6.4.登陆dashboard(master节点)
- 6.5.dashboard安装错误删除(部分命令-可参考)
- 七.延长证书过期时间【master节点执行】
-
- 7.1Kubeadm生成的k8s证书内容说明
- 7.2.延长k8s证书时间
- 总结
前言
1、Kubernetes 是什么
Kubernetes 是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制
2、服务器信息
本次搭建使用了三台不同厂商的服务器,两台阿里云,一台腾讯云
3、前置信息
公网IP下部署
docker:20.10.10
k8s:v1.21.0-beta.0
一、环境准备
1.1、服务器准备
因为服务器都是公网IP, 以下使用其他IP代指
master主机:192.168.0.01
node1服务器:192.168.0.02
node2服务器:192.168.0.03
1.2、服务器hostname设置
hostnamectl set-hostname master #01执行
hostnamectl set-hostname node1 #02执行
hostnamectl set-hostname node2 #03执行
1.3、添加hosts 网络主机配置,三台服务器都要设置
vim /etc/hosts
#主从节点服务器主机名和上面设置的主机名要一致,
192.168.0.01 master
192.168.0.02 node1
192.168.0.03 node2
1.4、关闭防火墙,设置开机禁用防火墙,三台服务器都要设置
systemctl stop firewalld.service
systemctl disable firewalld.service
1.5、关闭selinux,关闭swap,三台服务器都要设置
#关闭selinux,selinux的主要作用就是最大限度地减小系统中服务进程可访问的资源(最小权限原则)
sed -i 's/enforcing/disabled/' /etc/selinux/config
#关闭swap,Swap会导致docker的运行不正常,性能下降,是个bug,但是后来关闭swap就解决了,就变成了通用方案
echo "vm.swappiness = 0">> /etc/sysctl.conf
swapoff -a && swapon -a
sysctl -p
1.6、同步时间,三台服务器都要设置
timedatectl set-timezone Asia/Shanghai #设置时区-服务器都要执行
yum install ntpdate -y
ntpdate time.windows.com
问题1:因为我的服务器有一台是CentOS(8.2)版本,所以执行yum报错
CentOS Linux 8 - AppStream 131 B/s | 38 B 00:00
Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
这是因为Centos8于2021年年底停止了服务,使用yum源安装时候,就会报错,这时我们需要修改yum源
解决方案:
cd /etc/yum.repos.d/
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
# 如果已经安装了wget就不需要这一步
yum install wget –y
# 更新yum源为阿里源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
yum clean all
yum makecache
# 验证
yum install -y vim
问题2:CentOS(8.2)继续同步时间报错
Repository extras is listed more than once in the configuration
Last metadata expiration check: 0:06:58 ago on Thu 30 Mar 2023 04:21:45 PM CST.
No match for argument: ntpdate
Error: Unable to find a match: ntpdate
原因:在CentOS8中默认不再支持ntp软件包,时间同步将由chrony来实现
解决方案:通过wlnmp方式
添加wlnmp的yum源
rpm -ivh http://mirrors.wlnmp.com/centos/wlnmp-release-centos.noarch.rpm
安装ntp服务
yum -y install wntp
时间同步
ntpdate ntp1.aliyun.com
二、安装docker
2.1.配置docker repo文件
yum -y install wget && wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum clean all && yum makecache fast
yum whatprovides docker-ce
...
3:docker-ce-20.10.9-3.el7.x86_64 : The open-source application container engine
Repo : docker-ce-stable
3:docker-ce-20.10.10-3.el7.x86_64 : The open-source application container engine
Repo : docker-ce-stable
3:docker-ce-20.10.11-3.el7.x86_64 : The open-source application container engine
Repo : docker-ce-stable
3:docker-ce-20.10.12-3.el7.x86_64 : The open-source application container engine
Repo : docker-ce-stable
...
2.2.选择你需要的版本进行安装
yum -y install docker-ce-20.10.12-3.el7.x86_64
2.3.已安装docker下可直接修改版本
yum downgrade --setopt=obsoletes=0 -y docker-ce-3:20.10.12-3.el8.x86_64 docker-ce-selinux-20.10.12-3.el7.x86_64
2.4.开机自启动docker及运行docker服务
#设置开机启动
systemctl enable docker
#启动docker
systemctl start docker
#查看docke
systemctl status docker
docker version
三、安装k8s工具(所有节点全部执行)
3.1.添加kubernetes yum源
CentOS 7
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
CentOS 8
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.2.查看kubeadm版本
yum list kubeadm --showduplicates
...
kubeadm.x86_64 1.15.6-0
...
3.3.安装 kubeadm, kubelet 和 kubectl
#指定兼容的版本---依据你的docker版本来配置,若安装Rancher,则依据Rancher版本来配置
yum install -y kubectl-1.21.0 kubelet-1.21.0 kubeadm-1.21.0
#设置kebelet的开机启动
systemctl enable kubelet
#systemctl start kubelet
四.启动k8s(master节点执行)
4.1.初始化master节点(注意:192.168.0.01修改为自己的master节点ip,kubernetes版本改成自己的,其他忽动)
kubeadm init \
--apiserver-advertise-address=192.168.0.01 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.21.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
问题1:初始化过程中需要拉取镜像,如果初始化失败,提示拉取某个镜像失败,如下所示
preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0: output: Error response from daemon: pull access denied for registry.aliyuncs.com/google_containers/coredns/coredns, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决方案:
查看需要依赖哪些镜像
kubeadm config images list
...
I0401 23:57:06.786891 14994 version.go:254] remote version is much newer: v1.26.3; falling back to: stable-1.21
k8s.gcr.io/kube-apiserver:v1.21.14
k8s.gcr.io/kube-controller-manager:v1.21.14
k8s.gcr.io/kube-scheduler:v1.21.14
k8s.gcr.io/kube-proxy:v1.21.14
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
...
使用 docker images 命令查询镜像
docker images
...
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.aliyuncs.com/google_containers/kube-apiserver v1.21.0 4d217480042e 24 months ago 126MB
registry.aliyuncs.com/google_containers/kube-proxy v1.21.0 38ddd85fe90e 24 months ago 122MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.21.0 09708983cc37 24 months ago 120MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.21.0 62ad3129eca8 24 months ago 50.6MB
registry.aliyuncs.com/google_containers/pause 3.4.1 0f8457a4c2ec 2 years ago 683kB
registry.aliyuncs.com/google_containers/etcd 3.4.13-0 0369cf4303ff 2 years ago 253MB
...
发现已下载的镜像里面没有 /coredns/coredns:v1.8.0 这个镜像
使用 docker 命令拉取镜像
docker pull registry.aliyuncs.com/google_containers/coredns:1.8.0
Kubernetes 需要的是 /coredns/coredns:v1.8.0 这个镜像,使用 docker tag 命令重命名
# 重命名
docker tag registry.aliyuncs.com/google_containers/coredns:1.8.0 registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0
# 删除原有镜像
docker rmi registry.aliyuncs.com/google_containers/coredns:1.8.0
解决完成,再次运行初始化命令
问题2:init集群初始化时遇到:detected “cgroupfs” as the Docker cgroup driver
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
[root@master /]# --pod-network-cidr=10.244.0.0/16
-bash: --pod-network-cidr=10.244.0.0/16: No such file or directory
检测到"cgroupfs"作为Docker的cgroup驱动程序。 推荐使用systemd驱动
需要更换驱动 修改docker Drive
解决方案:
vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
#重启docker
systemctl daemon-reload
systemctl restart docker
#重置配置环境
kubeadm reset
#查询docker Drive
docker info | grep Cgrou
解决完成,再次运行初始化命令
问题3:公网ip初始化master节点报错
k8s是让kubelet直接与apiserver通过内网通信的,使用kubectl log等命令时还是用的内网IP,所以会提示timeout
解决方案:
准备
该实现需要在kubeadm初始化过程中对etcd进行修改,而kubeadm初始化是阻塞的,因此,需要建立两个ssh对话,即用ssh工具新建两个标签,一个用来初始化节点,另一个在初始化过程中修改配置文件。注意是初始化过程中,每次运行kubeadm init,kubeadm都会生成etcd的配置文件,如果提前修改了配置文件,在运行kubeadm init时会把修改的结果覆盖,那么也就没有作用了。
#重置所有配置
kubectl reset
再次运行初始化命令
kubeadm init ...
此时会卡在
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
修改etcd.yaml
在输入上述命令后,kubeadm即开始了master节点的初始化,但是由于etcd配置文件不正确,所以etcd无法启动,要对该文件进行修改。
文件路径"/etc/kubernetes/manifests/etcd.yaml"
要关注的是"–listen-client-urls"和"–listen-peer-urls"。需要把–listen-client-urls 和 --listen-peer-urls 都改成0.0.0.0:xxx
修改后示例:
- --listen-client-urls=https://0.0.0.0:2379
- --listen-peer-urls=https://0.0.0.0:2380
稍等片刻之后,master节点就初始化好了
参考:解决阿里云ECS下kubeadm部署k8s无法指定公网IP
问题处理完成!
初始化完成后会生成一段代码,这段代码在子节点加入的时候需要执行,如下图
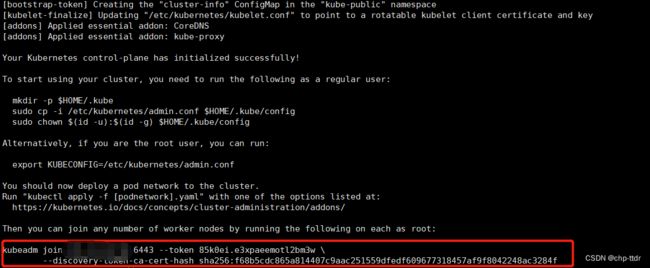
4.2.使用 kubectl 工具
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
相关信息:
#以下文件中是集群本身的信息以及安全授权的信息
/etc/kubernetes/admin.conf
#k8s默认读取的配置文件夹
$HOME/.kube/config
4.3.检查master节点
kubectl get nodes
#如果报The connection to the server localhost:8080 was refused - did you specify the right host or port?
#则配置环境变量
export KUBECONFIG=/etc/kubernetes/kubelet.conf
如下图则代表master节点已启动

4.4.安装pod网络插件
pod和pod之间的通信协议组件
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#或者
kubectl apply -f https://warehouse-lxf.gitee.io/develop/config/kube-flannel.yml
#如果上述命令不行不行,就
wget kube-flannel.yml
kubectl apply -f kube-flannel.yml
可以查看pod是否正常运行,Running表示正常运行
kubectl get pod -o wide -n kube-system
#查看所有名称空间下的pod容器,包含k8s自己内部的
kubectl get pod --all-namespaces
4.5.如果token过期重新获取token
kubeadm token generate
根据token输出添加命令,create后面带刚才生成的token文件
kubeadm token create ins9ct.n3vpfy86dsjglmxy --print-join-command --ttl=0
如此便获得新的加入命令了,拿去子节点执行
![]()
五.集群配置
5.1.子节点加入集群(子节点执行)
这时候就用到4.1单元中生成的那段代码了,哪个子节点需要加入集群就在哪个子节点执行,然后等待完成,完成后如下图

如果token过期了,按照4.5单元的操作重新获取token然后执行加入命令即可
如果重新生成token还不可以就检查是部署防火墙和开放端口的问题,检查master节点是否开启了6443
如果报错,报错信息为
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition
解决方案同4.1-问题2
5.2.检查节点是否加入集群 (master节点执行)
kubectl get nodes
如下图,两个node节点都加入了集群即为成功

5.3.创建pod (master节点执行)
查询现有的pod
kubectl get pod,svc

创建一个新的nginx的pod
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
如下图所示:创建成功

相关命令
#查看部署
kubectl get deployment
#获取详细信息的pod
kubectl get pod -o wide
#查看某一个pod的详细信息:kubectl describe pod pod名称
kubectl describe pod nginx-6799fc88d8-ff769
#查看pod内部的日志:kubectl logs pod名称
kubectl logs nginx-6799fc88d8-ff769
部署成功,我们需要测试访问一下我们的nginx,80对外映射的端口为30491,根据ip再找到节点,外部访问就是节点ip+32617端口,如果是云服务器一定要设置防火墙端口的开放

六.安装k8s的控制面板(master节点)
查看k8s对应的dashboard版本
本次安装k8s1.21,对应v2.3.0、v2.3.1、v2.4.0
本次安装dashboardv2.4.0
6.1.安装dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
6.2.配置外网访问,官网提供代理proxy、port-forward、NodePort三种方法。这里使用NodePort方式(默认Dashboard只能集群内部访问)
#编辑配置文件
kubectl -n kubernetes-dashboard edit service kubernetes-dashboard
#找到里面的type: ClusterIP 改成 type: NodePort
#找到里面的nodePort:改成 31080 对外的端口为:31080,也可不改
6.3.查看安装节点
执行命令,查看dashboard在哪个节点上
kubectl get pods -n kubernetes-dashboard -o wide
# 查询pods, 查询pod详情查看dashboard在哪个节点上
kubectl get pods --all-namespaces -o wide
# 查询服务, 查询端口
kubectl get svc --all-namespaces
#查看暴露的端口
kubectl -n kubernetes-dashboard get service kubernetes-dashboard
根据结果可以看到dashboard在node1的节点上,对外的端口为:31080


6.3.查看web页面
https://节点ip:31080/
如果出现访问异常:您目前无法访问 yourname.com,因为此网站发送了 Google Chrome
无法处理的杂乱凭据。网络错误和攻击通常是暂时的,因此,此网页稍后可能会恢复正常
解决方案:
在当前页,直接键盘敲入 thisisunsafe(鼠标点击当前页面任意位置,让页面处于最上层即可输入,输入时是不显示任何字符的,直接输入即可!)
进入页面后,显示如下
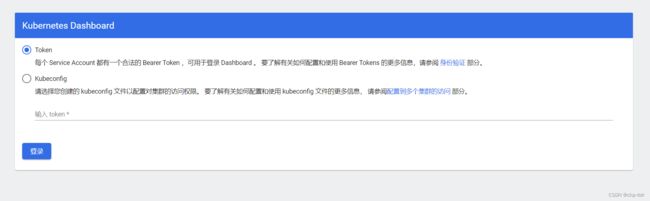
6.4.登陆dashboard(master节点)
登陆的话是选择令牌的方式,我们接下来先获取令牌
执行命令:
kubectl get secret -n kubernetes-dashboard|grep kubernetes-dashboard-token
得到如下图token文件
![]()
获取token:
根据上面生成的token文件,获取token,将上面获取的token文件替换命令
kubectl describe secret token文件名 -n kubernetes-dashboard
如下图得到token

登录:
粘贴token 到登录页的第一项令牌处
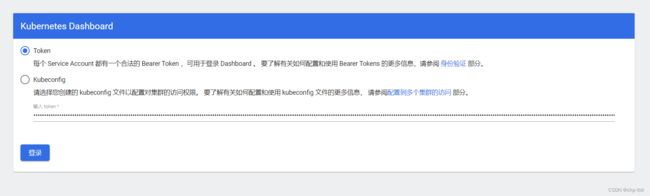
点击登录,就进入管理页面了
登录完成后:此时我们看不到任何数据,点击右上角的小铃铛,发现异常信息:
serviceaccounts is forbidden: User “system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard” cannot list resource “serviceaccounts” in API group “” in the namespace “default”,说明为权限不足,下面我们配置权限。
配置权限:
k8s采用的是基于角色的访问控制策略,Role-Based Access Control, 即”RBAC”,使用”rbac.authorization.k8s.io” API Group实现授权决策,涉及到ServiceAccount,Role,ClusterRole,RoleBinding,ClusterRoleBinding,Secret等概念
解决方案:执行以下命令
kubectl create clusterrolebinding serviceaccount-cluster-admin --clusterrole=cluster-admin --user=system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard
然后我们再看刚才访问的界面,已经刷新出数据

此时,我们已经可以正常访问k8s dashboard
6.5.dashboard安装错误删除(部分命令-可参考)
查看现有的所有服务
kubectl get svc --all-namespaces
删除现有的dashboard服务
kubectl delete service kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete service dashboard-metrics-scraper --namespace=kubernetes-dashboard
删除现有的dashboard pod
kubectl delete deployment kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete deployment dashboard-metrics-scraper --namespace=kubernetes-dashboard
七.延长证书过期时间【master节点执行】
7.1Kubeadm生成的k8s证书内容说明
1、证书分组
Kubernetes把证书放在了两个文件夹中
/etc/kubernetes/pki
/etc/kubernetes/pki/etcd
2、Kubernetes 集群根证书
Kubernetes 集群根证书CA(Kubernetes集群组件的证书签发机构)
/etc/kubernetes/pki/ca.crt
/etc/kubernetes/pki/ca.key
以上这组证书为签发其他Kubernetes组件证书使用的根证书, 可以认为是Kubernetes集群中证书签发机构之一
由此根证书签发的证书有:
—kube-apiserver apiserver证书
/etc/kubernetes/pki/apiserver.crt
/etc/kubernetes/pki/apiserver.key
—kubelet客户端证书, 用作 kube-apiserver 主动向 kubelet 发起请求时的客户端认证
/etc/kubernetes/pki/apiserver-kubelet-client.crt
/etc/kubernetes/pki/apiserver-kubelet-client.key
3、kube-apiserver 代理根证书(客户端证书)
用在requestheader-client-ca-file配置选项中, kube-apiserver 使用该证书来验证客户端证书是否为自己所签发
/etc/kubernetes/pki/front-proxy-ca.crt
/etc/kubernetes/pki/front-proxy-ca.key
由此根证书签发的证书只有一组:
代理层(如汇聚层aggregator)使用此套代理证书来向 kube-apiserver 请求认证
代理端使用的客户端证书, 用作代用户与 kube-apiserver 认证
/etc/kubernetes/pki/front-proxy-client.crt
/etc/kubernetes/pki/front-proxy-client.key
4、etcd 集群根证书
etcd集群所用到的证书都保存在/etc/kubernetes/pki/etcd这路径下, 很明显, 这一套证书是用来专门给etcd集群服务使用的, 设计以下证书文件
etcd 集群根证书CA(etcd 所用到的所有证书的签发机构)
/etc/kubernetes/pki/etcd/ca.crt
/etc/kubernetes/pki/etcd/ca.key
由此根证书签发机构签发的证书有:
—etcd server 持有的服务端证书
/etc/kubernetes/pki/etcd/server.crt
/etc/kubernetes/pki/etcd/server.key
—peer 集群中节点互相通信使用的客户端证书
/etc/kubernetes/pki/etcd/peer.crt
/etc/kubernetes/pki/etcd/peer.key
注: Peer:对同一个etcd集群中另外一个Member的称呼
—pod 中定义 Liveness 探针使用的客户端证书
kubeadm 部署的 Kubernetes 集群是以 pod 的方式运行 etcd 服务的, 在该 pod 的定义中, 配置了 Liveness 探活探针
/etc/kubernetes/pki/etcd/healthcheck-client.crt
/etc/kubernetes/pki/etcd/healthcheck-client.key
当你 describe etcd 的 pod 时, 会看到如下一行配置:
Liveness: exec [/bin/sh -ec ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key get foo] delay=15s timeout=15s period=10s #success=1 #failure=8
—配置在 kube-apiserver 中用来与 etcd server 做双向认证的客户端证书
/etc/kubernetes/pki/apiserver-etcd-client.crt
/etc/kubernetes/pki/apiserver-etcd-client.key
7.2.延长k8s证书时间
查看ca证书有效时间:
openssl x509 -in /etc/kubernetes/pki/ca.crt -noout -text |grep Not
查看apiserver证书有效时间:
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text |grep Not
如下图,可见ca证书有效期是10年,apiserver证书有效期是1年

k8s默认安装授权书期限为一年,对于生产环境比较不适用,需要延长期限
编写延长期限10年的脚本:
vim update-kubeadm-cert.sh
#!/bin/bash
#脚本转载自https://github.com/yuyicai/update-kube-cert
set -o errexit
set -o pipefail
# set -o xtrace
log::err() {
printf "[$(date +'%Y-%m-%dT%H:%M:%S.%N%z')]: \033[31mERROR: \033[0m$@\n"
}
log::info() {
printf "[$(date +'%Y-%m-%dT%H:%M:%S.%N%z')]: \033[32mINFO: \033[0m$@\n"
}
log::warning() {
printf "[$(date +'%Y-%m-%dT%H:%M:%S.%N%z')]: \033[33mWARNING: \033[0m$@\n"
}
check_file() {
if [[ ! -r ${1} ]]; then
log::err "can not find ${1}"
exit 1
fi
}
# get x509v3 subject alternative name from the old certificate
cert::get_subject_alt_name() {
local cert=${1}.crt
check_file "${cert}"
local alt_name=$(openssl x509 -text -noout -in ${cert} | grep -A1 'Alternative' | tail -n1 | sed 's/[[:space:]]*Address//g')
printf "${alt_name}\n"
}
# get subject from the old certificate
cert::get_subj() {
local cert=${1}.crt
check_file "${cert}"
local subj=$(openssl x509 -text -noout -in ${cert} | grep "Subject:" | sed 's/Subject:/\//g;s/\,/\//;s/[[:space:]]//g')
printf "${subj}\n"
}
cert::backup_file() {
local file=${1}
if [[ ! -e ${file}.old-$(date +%Y%m%d) ]]; then
cp -rp ${file} ${file}.old-$(date +%Y%m%d)
log::info "backup ${file} to ${file}.old-$(date +%Y%m%d)"
else
log::warning "does not backup, ${file}.old-$(date +%Y%m%d) already exists"
fi
}
# generate certificate whit client, server or peer
# Args:
# $1 (the name of certificate)
# $2 (the type of certificate, must be one of client, server, peer)
# $3 (the subject of certificates)
# $4 (the validity of certificates) (days)
# $5 (the x509v3 subject alternative name of certificate when the type of certificate is server or peer)
cert::gen_cert() {
local cert_name=${1}
local cert_type=${2}
local subj=${3}
local cert_days=${4}
local alt_name=${5}
local cert=${cert_name}.crt
local key=${cert_name}.key
local csr=${cert_name}.csr
local csr_conf="distinguished_name = dn\n[dn]\n[v3_ext]\nkeyUsage = critical, digitalSignature, keyEncipherment\n"
check_file "${key}"
check_file "${cert}"
# backup certificate when certificate not in ${kubeconf_arr[@]}
# kubeconf_arr=("controller-manager.crt" "scheduler.crt" "admin.crt" "kubelet.crt")
# if [[ ! "${kubeconf_arr[@]}" =~ "${cert##*/}" ]]; then
# cert::backup_file "${cert}"
# fi
case "${cert_type}" in
client)
openssl req -new -key ${key} -subj "${subj}" -reqexts v3_ext \
-config <(printf "${csr_conf} extendedKeyUsage = clientAuth\n") -out ${csr}
openssl x509 -in ${csr} -req -CA ${CA_CERT} -CAkey ${CA_KEY} -CAcreateserial -extensions v3_ext \
-extfile <(printf "${csr_conf} extendedKeyUsage = clientAuth\n") -days ${cert_days} -out ${cert}
log::info "generated ${cert}"
;;
server)
openssl req -new -key ${key} -subj "${subj}" -reqexts v3_ext \
-config <(printf "${csr_conf} extendedKeyUsage = serverAuth\nsubjectAltName = ${alt_name}\n") -out ${csr}
openssl x509 -in ${csr} -req -CA ${CA_CERT} -CAkey ${CA_KEY} -CAcreateserial -extensions v3_ext \
-extfile <(printf "${csr_conf} extendedKeyUsage = serverAuth\nsubjectAltName = ${alt_name}\n") -days ${cert_days} -out ${cert}
log::info "generated ${cert}"
;;
peer)
openssl req -new -key ${key} -subj "${subj}" -reqexts v3_ext \
-config <(printf "${csr_conf} extendedKeyUsage = serverAuth, clientAuth\nsubjectAltName = ${alt_name}\n") -out ${csr}
openssl x509 -in ${csr} -req -CA ${CA_CERT} -CAkey ${CA_KEY} -CAcreateserial -extensions v3_ext \
-extfile <(printf "${csr_conf} extendedKeyUsage = serverAuth, clientAuth\nsubjectAltName = ${alt_name}\n") -days ${cert_days} -out ${cert}
log::info "generated ${cert}"
;;
*)
log::err "unknow, unsupported etcd certs type: ${cert_type}, supported type: client, server, peer"
exit 1
esac
rm -f ${csr}
}
cert::update_kubeconf() {
local cert_name=${1}
local kubeconf_file=${cert_name}.conf
local cert=${cert_name}.crt
local key=${cert_name}.key
# generate certificate
check_file ${kubeconf_file}
# get the key from the old kubeconf
grep "client-key-data" ${kubeconf_file} | awk {'print$2'} | base64 -d > ${key}
# get the old certificate from the old kubeconf
grep "client-certificate-data" ${kubeconf_file} | awk {'print$2'} | base64 -d > ${cert}
# get subject from the old certificate
local subj=$(cert::get_subj ${cert_name})
cert::gen_cert "${cert_name}" "client" "${subj}" "${CAER_DAYS}"
# get certificate base64 code
local cert_base64=$(base64 -w 0 ${cert})
# backup kubeconf
# cert::backup_file "${kubeconf_file}"
# set certificate base64 code to kubeconf
sed -i 's/client-certificate-data:.*/client-certificate-data: '${cert_base64}'/g' ${kubeconf_file}
log::info "generated new ${kubeconf_file}"
rm -f ${cert}
rm -f ${key}
# set config for kubectl
if [[ ${cert_name##*/} == "admin" ]]; then
mkdir -p ~/.kube
cp -fp ${kubeconf_file} ~/.kube/config
log::info "copy the admin.conf to ~/.kube/config for kubectl"
fi
}
cert::update_etcd_cert() {
PKI_PATH=${KUBE_PATH}/pki/etcd
CA_CERT=${PKI_PATH}/ca.crt
CA_KEY=${PKI_PATH}/ca.key
check_file "${CA_CERT}"
check_file "${CA_KEY}"
# generate etcd server certificate
# /etc/kubernetes/pki/etcd/server
CART_NAME=${PKI_PATH}/server
subject_alt_name=$(cert::get_subject_alt_name ${CART_NAME})
cert::gen_cert "${CART_NAME}" "peer" "/CN=etcd-server" "${CAER_DAYS}" "${subject_alt_name}"
# generate etcd peer certificate
# /etc/kubernetes/pki/etcd/peer
CART_NAME=${PKI_PATH}/peer
subject_alt_name=$(cert::get_subject_alt_name ${CART_NAME})
cert::gen_cert "${CART_NAME}" "peer" "/CN=etcd-peer" "${CAER_DAYS}" "${subject_alt_name}"
# generate etcd healthcheck-client certificate
# /etc/kubernetes/pki/etcd/healthcheck-client
CART_NAME=${PKI_PATH}/healthcheck-client
cert::gen_cert "${CART_NAME}" "client" "/O=system:masters/CN=kube-etcd-healthcheck-client" "${CAER_DAYS}"
# generate apiserver-etcd-client certificate
# /etc/kubernetes/pki/apiserver-etcd-client
check_file "${CA_CERT}"
check_file "${CA_KEY}"
PKI_PATH=${KUBE_PATH}/pki
CART_NAME=${PKI_PATH}/apiserver-etcd-client
cert::gen_cert "${CART_NAME}" "client" "/O=system:masters/CN=kube-apiserver-etcd-client" "${CAER_DAYS}"
# restart etcd
docker ps | awk '/k8s_etcd/{print$1}' | xargs -r -I '{}' docker restart {} || true
log::info "restarted etcd"
}
cert::update_master_cert() {
PKI_PATH=${KUBE_PATH}/pki
CA_CERT=${PKI_PATH}/ca.crt
CA_KEY=${PKI_PATH}/ca.key
check_file "${CA_CERT}"
check_file "${CA_KEY}"
# generate apiserver server certificate
# /etc/kubernetes/pki/apiserver
CART_NAME=${PKI_PATH}/apiserver
subject_alt_name=$(cert::get_subject_alt_name ${CART_NAME})
cert::gen_cert "${CART_NAME}" "server" "/CN=kube-apiserver" "${CAER_DAYS}" "${subject_alt_name}"
# generate apiserver-kubelet-client certificate
# /etc/kubernetes/pki/apiserver-kubelet-client
CART_NAME=${PKI_PATH}/apiserver-kubelet-client
cert::gen_cert "${CART_NAME}" "client" "/O=system:masters/CN=kube-apiserver-kubelet-client" "${CAER_DAYS}"
# generate kubeconf for controller-manager,scheduler,kubectl and kubelet
# /etc/kubernetes/controller-manager,scheduler,admin,kubelet.conf
cert::update_kubeconf "${KUBE_PATH}/controller-manager"
cert::update_kubeconf "${KUBE_PATH}/scheduler"
cert::update_kubeconf "${KUBE_PATH}/admin"
# check kubelet.conf
# https://github.com/kubernetes/kubeadm/issues/1753
set +e
grep kubelet-client-current.pem /etc/kubernetes/kubelet.conf > /dev/null 2>&1
kubelet_cert_auto_update=$?
set -e
if [[ "$kubelet_cert_auto_update" == "0" ]]; then
log::warning "does not need to update kubelet.conf"
else
cert::update_kubeconf "${KUBE_PATH}/kubelet"
fi
# generate front-proxy-client certificate
# use front-proxy-client ca
CA_CERT=${PKI_PATH}/front-proxy-ca.crt
CA_KEY=${PKI_PATH}/front-proxy-ca.key
check_file "${CA_CERT}"
check_file "${CA_KEY}"
CART_NAME=${PKI_PATH}/front-proxy-client
cert::gen_cert "${CART_NAME}" "client" "/CN=front-proxy-client" "${CAER_DAYS}"
# restart apiserve, controller-manager, scheduler and kubelet
docker ps | awk '/k8s_kube-apiserver/{print$1}' | xargs -r -I '{}' docker restart {} || true
log::info "restarted kube-apiserver"
docker ps | awk '/k8s_kube-controller-manager/{print$1}' | xargs -r -I '{}' docker restart {} || true
log::info "restarted kube-controller-manager"
docker ps | awk '/k8s_kube-scheduler/{print$1}' | xargs -r -I '{}' docker restart {} || true
log::info "restarted kube-scheduler"
systemctl restart kubelet
log::info "restarted kubelet"
}
main() {
local node_tpye=$1
KUBE_PATH=/etc/kubernetes
CAER_DAYS=3650
# backup $KUBE_PATH to $KUBE_PATH.old-$(date +%Y%m%d)
cert::backup_file "${KUBE_PATH}"
case ${node_tpye} in
etcd)
# update etcd certificates
cert::update_etcd_cert
;;
master)
# update master certificates and kubeconf
cert::update_master_cert
;;
all)
# update etcd certificates
cert::update_etcd_cert
# update master certificates and kubeconf
cert::update_master_cert
;;
*)
log::err "unknow, unsupported certs type: ${cert_type}, supported type: all, etcd, master"
printf "Documentation: https://github.com/yuyicai/update-kube-cert
example:
'\033[32m./update-kubeadm-cert.sh all\033[0m' update all etcd certificates, master certificates and kubeconf
/etc/kubernetes
├── admin.conf
├── controller-manager.conf
├── scheduler.conf
├── kubelet.conf
└── pki
├── apiserver.crt
├── apiserver-etcd-client.crt
├── apiserver-kubelet-client.crt
├── front-proxy-client.crt
└── etcd
├── healthcheck-client.crt
├── peer.crt
└── server.crt
'\033[32m./update-kubeadm-cert.sh etcd\033[0m' update only etcd certificates
/etc/kubernetes
└── pki
├── apiserver-etcd-client.crt
└── etcd
├── healthcheck-client.crt
├── peer.crt
└── server.crt
'\033[32m./update-kubeadm-cert.sh master\033[0m' update only master certificates and kubeconf
/etc/kubernetes
├── admin.conf
├── controller-manager.conf
├── scheduler.conf
├── kubelet.conf
└── pki
├── apiserver.crt
├── apiserver-kubelet-client.crt
└── front-proxy-client.crt
"
exit 1
esac
}
main "$@"
赋权与执行:
chmod +x update-kubeadm-cert.sh
./update-kubeadm-cert.sh all
查看证书签发是否正常:
kubectl get pods -n kube-system
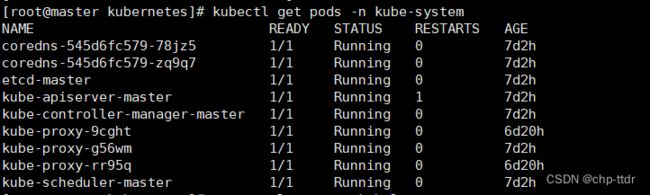
重启kubelet:
systemctl restart kubelet
验证证书有效时间是否延长到10年:

总结
本文仅仅简单介绍了Kubernetes的简单搭建,其他的可以自行探索 。