内存模型与无锁编程
目录
- 概念理解
-
- happens-before
- synchronizes-with
- 内存模型
-
- 顺序一致排序
- 自由序列
- 获取-释放序列
- lock-free数据结构
本文主要介绍C++新标准中的内存模型和无锁编程的原理和实现
概念理解
happens-before
在并发编程中,"happens-before"是一个非常重要的概念,它描述了内存操作之间的偏序关系。
"happens-before"关系定义了两个操作之间的可能的交错情况。如果操作A happens-before操作B,那么在所有的可观察行为中,操作A的结果都将对操作B可见,换句话说,操作B可以看到操作A的结果。
这个概念对于理解和设计多线程程序的正确性是非常关键的,因为它能够帮助我们理解在没有适当同步的情况下,哪些操作序列可能会导致不确定的行为。
例如,如果一个线程在没有同步的情况下写入一个变量,然后另一个线程读取这个变量,那么读操作可能看不到写操作的结果,因为写操作并没有happens-before读操作。
为了建立"happens-before"关系,通常可以使用一些同步机制,如锁、volatile变量或者原子操作等。
synchronizes-with
"synchronizes-with"是一个特殊的"happens-before关系,它描述了不同线程间的操作如何通过同步来建立偏序关系。
具体来说,当一个线程释放一个锁,然后另一个线程获得了这个锁,我们就说第一个线程的锁释放操作"synchronizes-with"第二个线程的锁获取操作。
这意味着第一个线程在释放锁之前的所有操作,在第二个线程看来,都发生在它获得锁之前。这就建立了一个跨线程的happens-before关系,确保了在没有适当同步的情况下,不会出现不确定的行为。
"synchronizes-with"关系是建立并发程序正确性的一个重要工具,它能够帮助我们理解和设计正确的多线程程序。
内存模型
通常是一个硬件上的概念,表示的是机器指令是以什么样的顺序被处理器执行的
共有六种内存顺序:memory_order_relaxed, memory_order_consume, memory_order_acquire,
memory_order_release, memory_order_acq_rel, memory_order_seq_cst.,默认为memory_order_seq_cst。分为三种模型
顺序一致排序
内存模型:memory_order_seq_cst
完全顺序一致性(Sequential Consistency)是一种最强的内存模型,要求所有操作都必须按照它们在程序中出现的顺序来执行,它符合我们日常的思维习惯,是最直观和易于理解的。然而,这种严格的顺序要求也带来了显著的性能开销。在多处理器系统中,为了维持顺序一致性,所有的处理器需要进行全局同步。也就是说,一个处理器上的操作必须在其他处理器上被“看到”之后,才能执行下一个操作。这可能需要处理器之间进行大量的、耗时的通信。因此,尽管顺序一致性易于理解,但在实际应用中,由于性能开销大,往往不会被首选。
自由序列
内存模型:memory_order_relaxed
在单一线程内仍然遵从happens-before关系。在一个线程对某一个原子变量的访问不能重排序。
void write_x_then_y() {
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_relaxed);
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed));
if (x.load(std::memory_order_relaxed))
++z;
}
void memory_relexed_test() {
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); // 很有可能z.load() == 0
}
在单个线程中,std::memory_order_relaxed不会改变数据依赖关系的顺序。也就是说,如果一个操作的结果依赖于另一个操作,那么这两个操作的顺序是不能改变的。然而,对于没有数据依赖关系的操作,编译器和处理器仍然可以对其进行重新排序。
对不同变量的 relaxed 操作可以被自由地重排,只要他们遵守任何他们被约束的“happens-before”(先行发生)关系。例如,同一线程内的操作必须遵守它们发生的先后顺序。然而,这些“松散”操作并不引入“synchronizes-with”(同步于)关系,这意味着它们不会强制要求其他线程看到的操作顺序与它们的执行顺序一致。所以,它的操作可能是以下这样的:
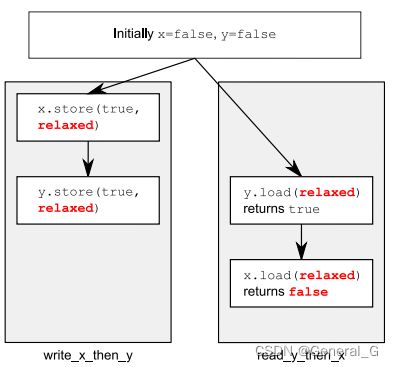
一个形象比喻:
原子变量就是一个小房间中的人,他会记录一系列值,线程就要求这个人修改值或者向他询问这个值是多少的电话。write_x_then_y就是打电话分别告诉x和y这两个人将值修改为true,然后另外一个电话(另一个线程)read_y_then_x首先询问y的值,一直到y告诉他为true,这时他再询问x的值,但x完全可以不告诉他前面的人更新后的值(这就是relaxed的特点),而是告诉他之前的值false。这样z就完全有可能是0。
所以,如果想要在不引入完全顺序一致性的开销的情况下实现额外的同步,可以使用获取-释放(acquire-release)排序。
获取-释放序列
内存模型:memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel
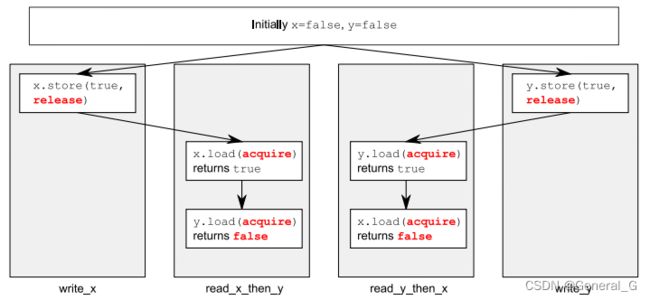
相比较完全顺序一致性(Sequential Consistency),获取-释放排序是一种更为轻量级的内存模型,只要求某些特定的操作(例如锁的获取和释放)必须按照顺序来执行,而其他操作则可以被自由地重排。这种模型可以在保证足够的同步性的同时,减少性能开销。相比较 relaxed 顺序,又是一种进步。
在这种顺序模型下,原子加载是获取操作(memory_order_acquire), 原子存储是释放操作 (memory_order_release),read-modify-write操作时acquire,release或者两者都有(memory_order_acq_rel)。同步是在线程之间release和acquire成对出现的。一个release的写操作会同步给acquire的读操作。这意味着不同的线程仍然可以看到不同的顺序,但这个顺序是被限制的。简单来说,就是在并发编程中,获取-释放操作是成对出现的,一个线程释放(写入)一个值,另一个线程获取(读取)这个值,这两个操作之间存在“同步-发生”关系。虽然不同线程可以看到操作的不同顺序,但这些顺序是受获取-释放规则限制的,不能随意改变。这样可以在一定程度上保证程序的正确性,同时避免了完全顺序一致性带来的性能开销。
示例代码1:
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_release);
}
void write_y() {
y.store(true, std::memory_order_release);
}
void read_x_then_y() {
while (!x.load(std::memory_order_acquire));
if (y.load(std::memory_order_acquire)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire));
if (x.load(std::memory_order_acquire)) {
++z;
}
}
void main() {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0);
}
这段代码有可能z.load() != 0,因为x和y之间没有happens-before的关系。(x86 linux和win自验证上自验证ok,有可能arm可能会有问题)
需要在一个线程中设置x和y的值,如下:
void write_x_then_y() {
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_release);
}
void read_y_then_x() {
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_relaxed))
++z;
}
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0);
}
lock-free数据结构
volatile:用来提供过度优化,既不保证不可切割,也不保证次序
terminate函数在默认情况下是去调用abort函数的,不过用户可以通过set_terminate函数来改变默认行为
abort函数更加底层,abort不会调用任何析构
exit属于正常退出,会调用自动变量的析构函数,并且还会调用atexit注册的函数,这和main函数结束时的清理工作是一样的
C++11标准引入快速退出:quick_exit,at_quick_exit