分布式数据库原理及技术实验及个人思考
Hive的数据库及表的存储结构体系讨论:
1.显示hive所在数据库的位置
方法一:一次性临时存储
>hive set hive.cli.print.current.db=true
方法二:永久存储
在conf文件夹下修改hive-site.xml配置文件,添加
实现永久显现
问题1、HIVE创建的默认数据库以及在默认数据库下面创建的表存储位置在哪里?
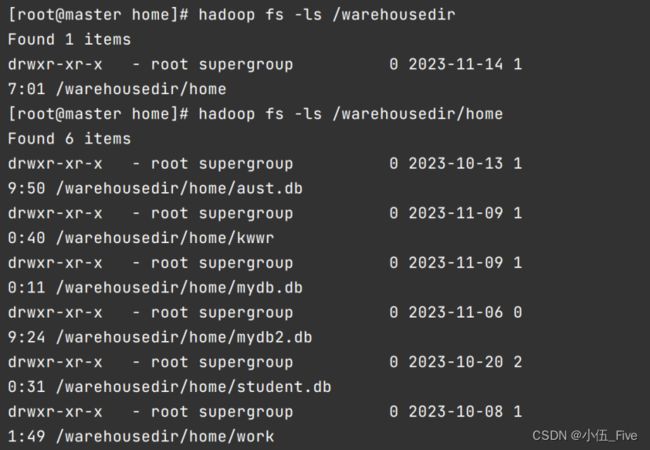
为查看hive创建的默认数据库及默认数据库下所创表的存储位置,在dafault数据库下创建一个表 kwwr,通过hdfs命令查找到kwwr表所在位置
首先
desc extended kwwr;
或者
desc formatted kwwr;
查看状况

hdfs fs -ls 查看文件所在位置

可知:
HIVE创建的默认数据库所在位置:/warehousedir/home
在默认数据库下面创建的表存储位置:/warehousedir/home/kwwr
问题2、HIVE创建自定义数据库mydb,并在mydb下面创建自定义表student,则mydb和student的存储位置在哪里?
同样,查看自定义数据库mydb以及自定义表student的存储位置

可知:
HIVE创建的自定义数据库mydb数据库所在位置:/warehousedir/home/mydb.db
在mydb数据库下面创建的表student存储位置:/warehousedir/home/mydb.db/student
讨论:分析默认数据库中表的存储位置和自定义数据库中的表的存储位置是否一样?
不一样,
默认数据库中的表存储在特定的数据文件中,这些文件通常位于数据库服务器上的特定目录下,即/warehousedir/home/(表名)。对于自定义数据库,它的存储位置通常是在数据库服务器的相应数据目录下,即/warehousedir/home/(所创建的数据库名).db/(表名)。
HDFS指令操作
hdfs shell 使用
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html

hadoop fs -mkdir /usr;
-touchz 在hdfs上创建空白文件
hadoop fs -touchz /emptyfile
hadoop fs -ls /
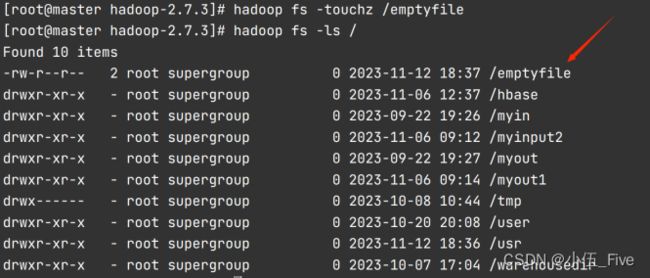

1. -ls 显示当前目录结构
hadoop fs -ls /
后面如果没有目录就是访问/user/<当前用户>目录,即/user/root。
如果没有这个目录/user/root,会提示文件不存在的错误。
2. -lsr 递归显示目录结构
该命令选项表示递归显示当前路径的目录结构,后面跟hdfs路径。
hadoop fs -ls -R /usr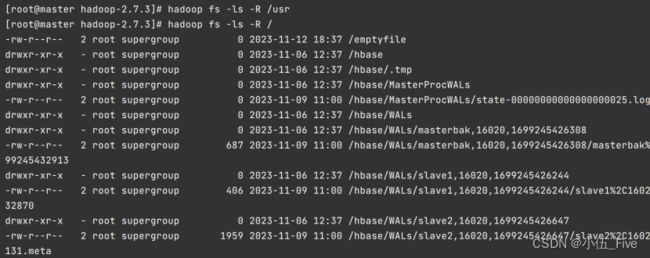
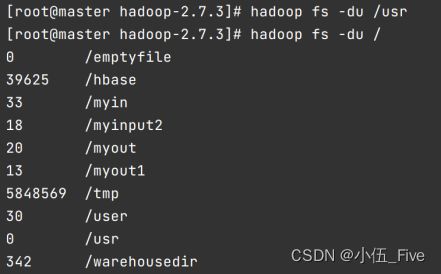
3. -du 统计目录下各文件大小
该命令选项显示指定路径下的文件大小,单位是字节
hadoop fs -du /usr
4. -dus 汇总统计目录下文件大小
该命令选项显示指定路径的文件大小,单位是字节
hadoop fs -du -s /usr

5. -count 统计文件(夹)数量
hdfs fs -count /usr

6. -mv 移动
该命令选项表示移动hdfs的文件到指定的hdfs目录中。
后面跟两个路径,第一个表示源文件,第二个表示目的目录.
hadoop fs -mv /usr/opt/data/student.txt /usr

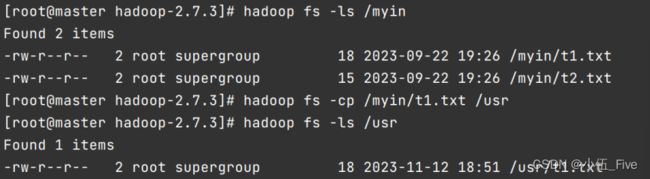
7. -cp 复制
该命令选项表示复制hdfs指定的文件到指定的hdfs目录中。
后面跟两个路径,第一个是被复制的文件,第二个是目的地.
hadoop fs -cp /usr/opt/data/student.txt /usr
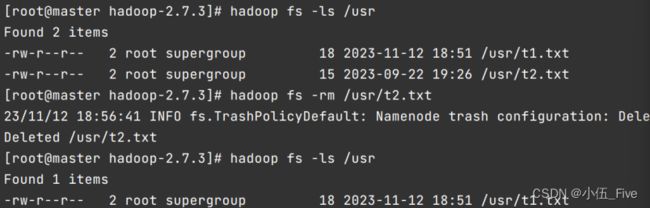
8.-rm 删除文件/空白文件夹
该命令选项表示删除指定的文件或者空目录
hadoop fs -rm /usr
-rmr 递归删除
9.-put 上传文件
该命令选项表示把linux上的文件复制到hdfs中
hadoop fs -put /usr/opt/data/student.txt /usr/data

??思考问题 -put后本地文件是否还有student.txt?-mv呢?-cp呢?
答:
-put后本地文件还存在原文件
-mv后本地文件不存在

-cp后本地文件还存在

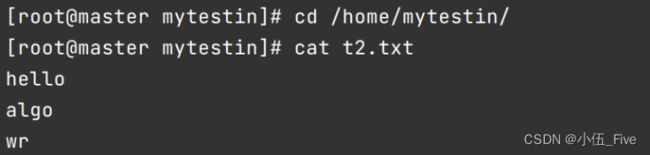
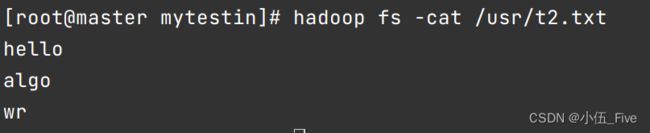
10. -cat查看文件内容; -text
hadoop fs -cat /student.txt
11. -chmod 修改文件权限
hadoop fs -chmod 777 /emptyfile 777最高权限读写方式

12. get(从hdfs拷贝文件到本地)
hdfs fs -get /usr/student.txt /usr/opt/data

Hive下命令:
Create database location ‘/testdata’;
指定所存到的位置
hive 删除数据库报库内已存在表
Drop database if exists 数据库名 cascade;
思考:hadoop fs -mkdir /testdata
hive>create database fh1 location '/testdata/fh1.db';
hive>create table student(sid int, sname string);
如果使用drop database fh1;是否可以删除数据库fh1?
不可以

如果使用hive>drop database if exists fh1 cascade; 那么/testdata文件夹还是否存在?
可以删除掉数据库,但/testdata文件夹不存在了
但是如果默认数据库创建的位置,删去数据库后,默认存储文件夹/warehousedir/home不会消失
删去数据库mydb1后,显示结果:
实操实验:
1.将ah16表中满足条件:年龄在19到22岁之间且血型为A的学生名单查询输出到/exampleout目录下;
Hdfs创建文件系统:
![]()
将数据写入文件系统:
insert overwrite directory 'lexampleout'
row format delimited
fields terminated by','
select * from blood
where age>19 and age<=22 and blood='A';

查看:
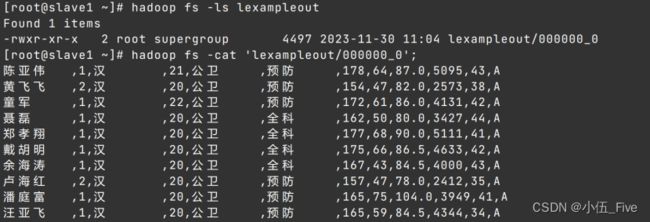
2、通过insert into ...values指令同时插入三条数据,是否需要启动mapreduce?

需要启动MR
3、update ... set...[where]指令需不需要启动Mapreduce? where 语句存在性是否会影响MR的启动?

update ... set...[where]指令需要启动MR;

where 语句存在性不影响MR的启动
- delete from与drop table的区别,两者是否需要启动mapreduce?
delete from需要启动MR

Drop table则不需要

直接删除表
- rename一个已有表的表名,如何实现,是否需要启动mapreduce?
不需要启动MR

只是修改元数据,而不是实际的数据。