mysql
一、InnoDB引擎
InnoDB引擎支持事务,通过MVCC和锁实现的。MyISAM引擎不支持事务。
行式数据库,每一行的数据是在一起的;列式数据库,每一列的数据是在一起的。
行格式:compact等。
compact行格式有两个部分:
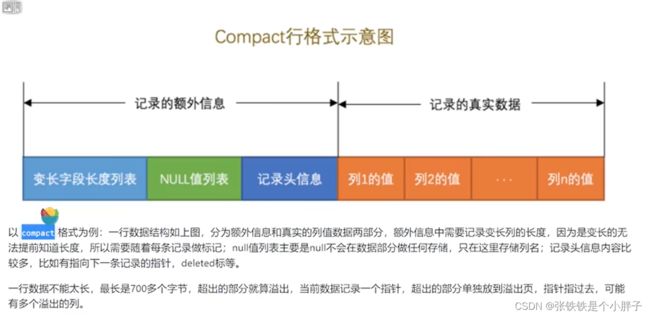
每行数据是一个record,record通过页的方式管理起来,一个页是16k,一个页中存放多条数据。页与页之间通过双向链表连接在一起,每一页的数据通过单向指针连接在一起。

页结构:

PageDirectory是比较重要的数据,首先将Inf作为一个分组,sup和往前最多8条数据为一个分组,中间的数据4条为一个分组,通过此方式将页内的数据进行分组,每一组最后一条数据的记录头中n_owned字段记录了该组一共多少条数据,并且PageDirectory存储每个分组最后一条数据的地址。通过这个目录,在查询当前分页的数据时就可以实现二分查找。
区与段
一页是16k,64个连续的页成为一个区,也就是1M一个区。内存读取的最小单位是页,磁盘分配的最小单位是区。
段是纯逻辑的概念,例如叶子结点段、非叶子节点段。
数据更改时页的变化
页里面的数据是有序的,是通过指针连接的。这些记录逻辑上是连续的,物理上可以不连续。
insert:例如想在记录2和记录3之间插入一条数据,步骤是,1、向free space申请空间,申请的空间会标记成User Record。2、记录2的指针会指向这块空间,这块空间指向记录3。
update:1、修改前后长度没有变化,例如将int 10改成int 11,直接就地更新就可以了。
2、修改前后长度有变化,例如text类型的字段,修改前长度是10,修改后长度是11,这种是先删除再创建。
页分裂:如果当前页的剩余空间不够分配给新插入的数据,就会页分裂。
聚簇索引(主键索引)、二级索引

上图每一页第一行的2、1、3代表记录的类型。
2:Infimum首节点。
3:supremum尾结点。
1:中间的普通记录。
聚簇索引比较的是主键列的值。二级索引比较的是索引列的值。联合索引先比较第一个索引列,然后再依次比较剩余的索引列的值(这就是多个字段联合索引最左匹配的原因)。
聚簇索引的叶子结点记录了主键和其他所有字段的信息。二级索引和联合索引只记录了索引列和主键列的信息。如果查询的列不仅是主键列和索引列,那二级索引就需要回表,回表就是拿着主键值再到聚簇索引里走一遍,拿到所需要的所有列的信息。
例如:字段a、字段b是联合索引。select * from t where a > 1 and a < 10 and b = 1;
首先先找到a属于(1,10)这个连续的范围,然后再循环去比较b是否等于1。如果还需要其他字段的值,就拿到id去回表,得到其他字段的值。这就是联合索引的索引下推。
例如:a是二级索引,id是主键列。select a, id from t where a > 10;
a>10命中了二级索引,就会在二级索引B+树中进行搜索,二级索引B+树已经有a和id列的值,这个sql也只查询a和id列的值,不需要去聚簇索引回表了,这就是覆盖索引。
BufferPool
读数据的最小单位是16k的页。例如我们查询35页的一条数据,也会把35页的所有数据都加载到内存,减少IO,基于此就有了BufferPool这个内存额定大小的空间。
free链表:空闲的、可用的,可以存储从磁盘读取的数据页。
flush链表:如果对某个数据页做了修改,需要刷新到磁盘的脏页。
LRU链表:从磁盘读取到内存的页,都会放到LRU链表中,也就是说LRU链表中的节点是由flush链表的所有节点和另一部分只读没写的节点组成。只读没写是读取到了内存,但是没有做修改,不需要刷新到磁盘的。
脏页的落盘,是一个后台线程定期执行的。
二、binlog、redolog、undolog
如果将数据页读取到了内存并做了修改且还没有刷新到磁盘,如果此时系统崩溃了,就会有问题。
1、binlob
记录执行的写操作,会把执行过的sql记录到文件里。只记录写的sql,不会记录select、show这类操作。文件记录模式有statement、row、mixed。statement是记录执行的语句。row是记录行的数据。mixed是两者的结合。
statement的缺点:如果执行一个insert语句,时间字段值使用了now()函数。如果之后出现问题需要恢复数据,那日期就是恢复的日期而不是实际执行insert的日期。
解决方案:先set时间,再执行insert。
例如现在是1点5分,想要把数据恢复到1点1分。

binlog的生成时机,是在事务提交的时候写binlog。
2.redolog
redolog也是记录数据的变动的。是存储引擎级别的日志,记录的是数据页的变动,并且是顺序写的,性能更好。
redolog和binlog相比较:
1、binlog是逻辑日志,记录的是sql。
2、redolog记录的是数据页的变动,例如某一个的第100个字节的值从a变成了b,记录了物理磁盘某一个字节的变动,是二进制数据。
3、binlog会不断累积,redolog是循环的,例如从0到3开始写,3写满了,再下一个循环接着写0,会覆盖。
4、binlog的目的是记录所有的写sql,用于归档,可以恢复到任意时间,redolog的目的是故障恢复,所以只需要保证记录了所有的脏页即可。
但凡是产生脏页的就一定要写入redolog,在事务提交的时候redolog必须刷盘。
binlog为什么不能做故障恢复?
因为如果机器1点5分挂掉了,将stoptime设置为1点5分使用binlog来做故障恢复,要先删整个库,然后再执行binlog记录的sql,显然是不可取的。
redolog来做故障恢复,只需要恢复脏页即可。
事务提交的时候一定保证redolog刷盘,这样可以保障内存中的脏页一定在redolog里面。
就可以把在内存中但是没有刷新到磁盘的数据写到idb文件,这就是故障恢复做的事情。
为什么不在事务提交的时候直接刷盘到idb文件?
redolog是顺序写,速度快。因此采用同步flush redolog,异步flush idb文件的策略。

checkpoint检查点
脏页已经异步flush到idb文件,此时就不是一个脏页了,会更新checkpoint,此时redolog已经不需要记录这个页了。checkpoint之前的数据说明已经写入了idb文件了,这些数据已经没有用了,checkpoint之后的数据说明还没有写入idb文件了或者已经写入但是还没有更新checkpoint。
redolog记录的页的变动信息是幂等的。
3.undolog
undolog并不专门对应一个log文件,而binlog、redolog对应有日志文件的。undolog是一种页的类型。undolog会存储到idb文件里,与其说是一种日志,不如说是起到了日志作用的一种特殊的页。
undolog与事务回滚和MVCC都有关系。
一行数据有3个隐藏字段,rowid、trx_id、roll_pointer,如果没有设置主键,那rowid就作为主键。

上图就是一个版本链。
在事务id是10的事务中,将某个字段值从2改成了3。
事务id是可以不连续的,如果所示无事务8,因为事务8可能没有修改当前这条数据。
版本链的作用:可以做事务的回滚。如果事务10做了回滚,就会回滚到上一个版本事务9。回滚的时候要借助roll_pointer找到上一个版本,然后做回滚。undolog记录了每一条数据的版本链。
undolog对应不同的增删改操作生成的log结构并不相同。
1、insert操作:只记录id,如果需要回滚,直接根据id删除即可。
2、update操作:要记录修改字段之前的原始值,如果字段没有修改,则不需要记录。
3、delete操作:给打一个delete标,并不删除,这条数据还要在B+树里,因为如果删除了,就无法根据这条数据的roll_pointer找上一个版本了,就无法回滚了。事务提交的时候才会做真正的删除。

如上图所示:一条数据指向一个undo页,这个undo页又会指向另一个undo页。
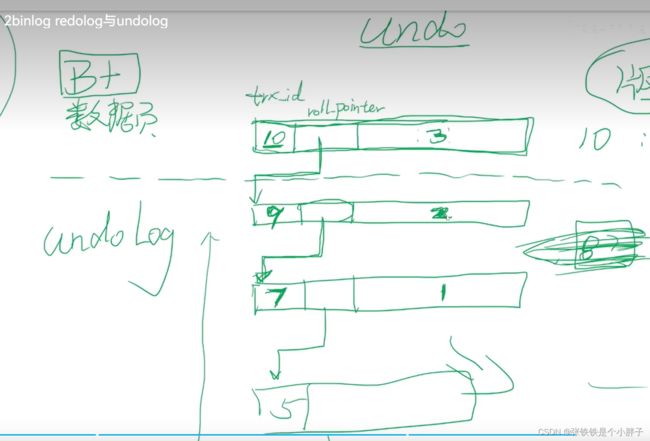
如上图:假如事务10未提交,事务9、事务7、事务5已经提交。
如果事务隔离级别是read commited,那么读取的数据就是事务9的数据。
max_trx_id:下一个要分配的trx_id
min_trx_id:说有活跃的trx_id中最小的id(活跃的就是未提交的)
m_ids:所有活跃的trx_id列表
creator_trx_id:当前事务的id(可能是0,因为可能没有写操作)
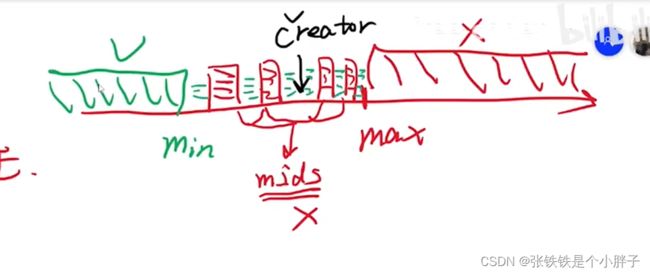
如果是creator_trx_id,说明是当前事务,可以读这个版本的数据。
如果不是:1、在m_ids里,说明未提交,不能读,往上找之前的版本。
2、不在m_ids里,说明已提交,可以读。

如上图所示:如果事务隔离级别是Read Commited,两次读取都会建立新的readview。如果事务隔离级别是Repeatable Read,只有第一次读取会建立新的readview,后面的读取用的都是第一次建立的readview。
假设有一张user表,有一条数据。
| id | name | age |
| 1 | lily | 20 |
步骤如下:
1、窗口一开启事务。
2、窗口二开启事务。
3、窗口一,update user set age = 21 where id = 1;不commit。(不自动commit)
4、窗口二,select * from user where id = 1;查询到age还是20。
5、窗口一,提交事务。
6、窗口二,select * from user where id = 1;查询到age还是20。因为mysql默认的隔离级别是Repeatable Read,和窗口二第一次查询使用的是同一个readview,读到的仍是第一次select建立的试图。
7、窗口二,提交事务。
8、窗口二,select * from user where id = 1;此时查询到age是21。
MVCC是解决读与写冲突的重要方式。
MVCC是乐观锁,可以解决写与写并发的问题。
读:用的是快照读,也就是视图读。(找到版本链上适合自己的一条数据)
写:用的是当前读。(读版本链最新的一条数据)
例如:update user set age = 19 where id = 1; // 当前读
首先是找到id = 1的这条数据,然后修改age为19。
select 语句用的是视图读。
select * from user for update; // 当前读
mysql不能解决当前读的幻读问题,但解决了视图读的幻读问题。
假设有一张user表,有一条数据。
| id | name | age |
| 1 | lily | 20 |
演示一,步骤如下:
窗口二:select * from user;查询到1条数据。
窗口一:执行insert,并commit,再select。查询到2条数据。
窗口二:select * from user;仍然只查询到1条数据,因为select是视图读,读取的仍是第一次select建立的视图,第一次select的时候窗口一的insert并没有提交呢。
演示二,步骤如下(接演示一,此时表中有2条数据):
窗口一:select * from user for update;查询到2条数据。
窗口二:insert 一条数据,会发现,当前操作阻塞住了,无法插入。(for update把资源锁住了)
窗口一:commit;
窗口二:insert成功了。
mysql没有解决当前读的幻读问题和写与写的并发问题,这个问题由锁来解决。
三、五种锁:记录锁、间隙锁、临键锁、插入意向锁、隐式锁。
记录锁:
update user set age = 9 where id = 1; 会把id = 1的数据锁住,使其他的事务不能修改id = 1的数据。此时如果有另一个事务更新id = 1的这条数据就会被阻塞住。
间隙锁:
锁住一个间隙,例如 update user set age = 1 where id < 1;就会锁住负无穷到1这个区间。
update user set age = 1 where id < 1;符合条件的记录数是0。
如果此时另外一个事务执行一个insert操作,插入的记录id是0。
那么满足id < 1的记录数就从0变成了1,这就是幻读。为避免幻读问题,因此要用间隙锁,将id属于(负无穷,1)这个间隙给锁住。
插入意向锁:一个间隙被锁住了,往这个间隙插入数据就会被阻塞,并且分配一把锁给这个事务,当前事务waiting直至间隙锁释放。
临键锁:
例如:update user set age = 1 where id <= 1;id的区间是(负无穷,1],右边是闭区间符号。是(负无穷,1)和id=1的并集。这就是临键锁。
隐式锁:
是针对insert操作的,默认是不加锁的,减少开销。当一个事务访问一条数据的时候,会根据这条数据的隐藏列trx_id判断这条数据是否已经提交。如果没有提交,就要给这条数据加锁。惰性地加记录锁,这就是隐式锁。隐式锁可以减少insert时锁的创建,只有发生竞争的时候由另一个事务惰性地创建,借助了trx_id隐藏列的信息。
独占锁、共享锁
独占锁:只要我占用了,其他的事务既不能读也不能写。
共享锁:其他的事务可以读,但是不能写。
update、delete、insert出现竞争,都是独占锁。只有select in share mode是共享模式。
学习视频:【mysql面试通关】1底层的存储方式_哔哩哔哩_bilibili