C#.Net学习笔记——CLR核心机制
一、CLR基本介绍
(1)C(Common) L(Language) R(Runtime) IL的运行环境
(2)从下图可以看到,我们的计算机会先把我们写的语言,编写成IL语言,再给计算机去读取。为什么我们不直接把我们的语言编写成计算机能够读取的?主要是考虑到我们计算机的不同,比如32位和64位,他们接收到计算机指令都是不一样的。甚至在不同的操作环境下得出的结果也是不一样的。因此,我们就需要有一个中间语言IL。CLR(通用语言进行时)就是IL的运行环境。
(3)metadata是清单数据,里面是描述了dll或者exe内有什么东西,依赖了什么东西。
(4)Exe文件的运行。实际上我们的exe文件可以运行,都是由CLR完成的,它为我们加载exe,检查metadata清单和IL。最后JIT(运行时编译)会交给计算机去执行。所以说CLR本质上可以说是一个IL的运行环境。
(5)编译器只要满足CLS规范,编译出来的东西就可以转换成IL语法
(6)使用CLR需要安装.Net Framework

二、堆栈内存分配
(1)基本介绍
什么内存? 程序运行时,进程占有的内存
谁来分配? CLR来分配
1、值类型:struct 枚举
2、引用类型:class 接口 委托
线程栈:栈-stack 先进后出的数据结构,随着线程而分配的,默认执行方法分配1M内存
对象堆:内存,进程中独立画出来的一块内存,有一些对象是不释放的,有些对象需要重用的。类似这种我们就需要堆空间。
(2)关于Struct
通过反编译我们可以看到,struct在中间语言里实际上也是class,但是它继承了父类System.ValueType。也就是说,只要是继承了ValueType的,我们就可以认为是值类型。
1、对于结构体,我们可以把它当作一个变量直接声明,也可以通过构造函数的方式new出来(结构体的构造函数必须包含所有字段和属性),但是无论哪种方式它都是值类型



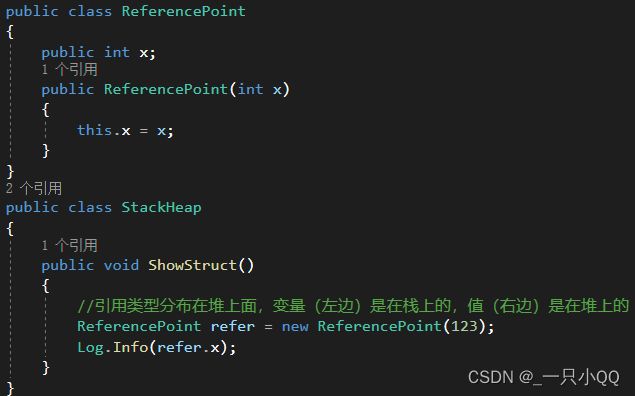
(3)关于Class
引用类型分布在堆上面,变量(左边)是在栈上的,值(右边)是在堆上的
1、new的时候去堆开辟内存,分配一个地址
2、调用构造函数(因为在构造函数里可以使用this),才执行构造函数
3、把引用传给变量
问题思考:
我们有一个类(ReferenceTypeClass),这个类有一个字段int valueTypeField和一个方法Method,方法Method内又声明了一个int valueTypeLocalVariable类型的字段。请问ValueTypeField和ValueTypeLocalVariable分别位于堆还是栈?
答案:valueTypeField是位于堆里,valueTypeLocalVariable是位于栈里。
因为对象都在堆里,那么对象里面的属性也在堆里。而方法内声明的变量是在栈里,当调用我们的方法的时候,线程栈会给声明一个临时变量,是一个全新的局部变量。

总结:方法的局部变量:根据变量自身决定,跟所在环境没关系
对象是引用类型,其属性/字段都在堆里面
对象是值类型,其属性/字段,值类型就在栈里,引用类型就在堆里。
引用类型任何时候都在堆里;值类型都在栈里,除非值类型所在对象是在堆里。
三、拆箱装箱(浪费性能)
1、装箱:值类型->引用类型
int i = 3;
object Value = i;2、拆箱:引用类型->值类型
object Value = 10;
int k = (int)Value;3、拆箱装箱只能发生在父子类里面?因为这样才能转换。
四、特别对象——字符串
1、string是一个引用类型
思考1:string是一个引用类型,下面例子中声明了一个student和student2。student2=student,使得他们指向同一内存 “哈哈” 。但是为什么在student2赋新值后student不会跟着改变。
private void button17_Click(object sender, EventArgs e) { string student = "哈哈"; string student2 = student; Log.Info(student + " " + student2); student2 = "1234"; Log.Info(student + " " + student2); }答案:因为赋值其实new了一个新的string,重新开辟内存,返回引用。
改了student2的值,但不是修改内存;string字符串的内存是不可变的
思考2:看案例,student和student2都是指向不同的内存,当我们重新给studeng2赋值并且这个值与student的值相等。按照上面的理论,他们的指向应该都是各自的内存,只不过他们的值恰好相等。思考一下他们都指向哪?
private void button17_Click(object sender, EventArgs e) { string student = "哈哈"; string student2 = "呵呵"; student2 = "哈哈"; Log.Info(object.ReferenceEquals(student, student2)); }答案:实际上他们还是指向了同一片内存。这就是我们CLR的机制,CLR内存分配字符串的时候,会查找相同值,有就重用。因此他们会指向相同内存以节约内存。
不可变是因为享元,可能有多个变量指向同一字符串,字符串变化了,多个变量都会受影响。
还因为堆里面的内存是连续分配的,如果变长度,会导致大量数据的移动。所以不如重新分配一个。
五、垃圾回收
(1)产生垃圾的原因:
1、值类型出现在线程栈:用完自己就结束,变量-值类型都会释放的。
2、引用类型出现在堆里:全局就一个堆,空间有限,所以才需要垃圾回收。
3、操作系统里面,内存是链式分配的,可能有碎片
4、CLR堆里边:连续分配(数组),空间有限,节约空间
(2)GC发生时机:
1、GC发生在New的时候,New一个对象时,会开辟内存在堆里边
2、New的时候看看空间够不够,不够的话就要GC了
3、定时程序,24小时执行一次,但是对象不会被回收,因为24小时之后你才会new,这个才能发生GC
4、静态不可能被回收 静态持有的引用也不会被回收
5、类似于下图这种情况,我们写了一个方法,方法内声明了Student和Class和一个int类型的变量。当方法执行结束后,值类型的i就会被直接回收,而引用类型的new Class则丢失引用,但是内存不会被自动回收,产生GC。
private static Student _student = new Student() { Id = 1, Name = "Test", }; public static void Show() { Student student = _student; Class @class = new Class() { Id = 1, CLassName = "Test", }; int i = 3; //会被GC }6、主动GC
GC.Collect();怎么回收?
什么是垃圾?垃圾是完全访问不到的东西
new的时候发现内存不够了,就去遍历所有堆的对象,标记访问不到,然后启动一个线程来清理内存。
移除标记了的对象,其他挪动,然后整齐摆放,所有这个时候全部线程停止,不允许操作内存。
为了促进垃圾回收,把对象赋值成null。其实不对,没有意义,垃圾回收是因为访问不到
六、优化策略
1、首次GC前,全部对象都是0级。
2、第一次GC后,还保留的对象叫1级
3、回收先找1级对象,如果空间还不够,再去找1级对象,这之后,还存在的对象变成2级,2级还不够就内存溢出了
4、越是最近分配的,越是会被回收。比如for循环创建对象
因为回收过了,之前的内存可能是常驻内存,所以就从最近开始回收。
七、析构函数
1、~Student 析构函数是用来释放非托管资源的,等着GC的时候去把非托管资源释放掉,系统自动执行。非托管资源就是管理不到的一些资源,包括数据库连接、打开的文档等。
八、Using
1、下面可以说是等同关系,Using本质上来说只是一种语法糖
using(Student student = new Student())
{
Id = 234
}try
{
Student student = new Student()
{
Id=234
}
}
finally
{
//调用的dispose()
}2、Dispose() 主动释放,方法本身是没有意义的,我们需要在方法里面实现堆资源的释放
而不是说对象释放的时候会自动去调用Dispose方法。
3、GC不会调用,而是用对象时,使用者主动调用这个方法。