环信服务端下载消息文件---菜鸟教程
前言
在服务端,下载消息文件是一个重要的功能。它允许您从服务器端获取并保存聊天消息、文件等数据,以便在本地进行进一步的处理和分析。本指南将指导您完成环信服务端下载消息文件的步骤。
环信服务端下载消息文件是指在环信服务端上,通过调用相应的API接口,从服务器端下载聊天消息、文件等数据的过程。因环信服务端保存的消息漫游是有时间限制,有用户需要漫游全部的消息或者自己服务端做所有消息记录的备份。可以从环信服务端下载消息文件来进行解压,读取消息文件内容进行存储到自己的服务端。
前提条件
- 已在环信即时通讯控制台 开通配置环信即时通讯 IM 服务。
注册环信即时通讯IM - 了解环信 IM REST API 的调用频率限制
- 环信接口文档介绍:
一、下载消息文件
以下将介绍如何通过环信接口获取到的URL来进行下载文件,解压文件,读取文件。
注:
time参数: 历史消息记录查询的起始时间。UTC 时间,使用 ISO8601 标准,格式为 yyyyMMddHH。例如 time 为 2018112717,则表示查询 2018 年 11 月 27 日 17 时至 2018 年 11 月 27 日 18 时期间的历史消息。若海外集群为 UTC 时区,需要根据自己所在的时区进行时间转换。

上图是环信官方文档中给出的获取历史消息记录响应示例。从示例中可以看出我们请求以后可以得到一个URL,这个URL为消息文件的下载URL。
1、下载消息文件环信rest 接口请求代码如下:
String url = "https://{{RestApi}}/{{org_name}}/{{app_name}}/chatmessages/2023122010";
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Type","application/json");
headers.add("Authorization","Bearer Authorization");
Map<String, String> body = new HashMap<>();
HttpEntity<Map<String, String>> entity = new HttpEntity<>(body, headers);
ResponseEntity<Map> response;
try {
response = restTemplate.exchange(url, HttpMethod.GET, entity, Map.class);
System.out.print("消息文件下载成功---"+response.toString());
} catch (Exception e) {
System.out.print("消息文件下载失败---"+e.toString());
}
2、消息文件下载,通过请求环信下载历史消息文件接口获取到的URL 进行下载。
示例代码:
String url = "";
String targetUrl = "";
download(url,targetUrl);
/**
* 根据url下载文件,保存到filepath中
*
* @param url 文件的url
* @param diskUrl 本地存储路径
* @return
*/
public static String download(String url, String diskUrl) {
String filepath = "";
String filename = "";
try {
HttpClient client = HttpClients.createDefault();
HttpGet httpget = new HttpGet(url);
// 加入Referer,防止防盗链 httpget.setHeader("Referer", url);
HttpResponse response = client.execute(httpget);
HttpEntity entity = response.getEntity();
InputStream is = entity.getContent();
if (StringUtils.isBlank(filepath)){
Map<String,String> map = getFilePath(response,url,diskUrl);
filepath = map.get("filepath");
filename = map.get("filename");
}
File file = new File(filepath);
file.getParentFile().mkdirs();
FileOutputStream fileout = new FileOutputStream(file);
byte[] buffer = new byte[cache];
int ch = 0;
while ((ch = is.read(buffer)) != -1) {
fileout.write(buffer, 0, ch);
}
is.close();
fileout.flush();
fileout.close();
} catch (Exception e) {
e.printStackTrace();
}
return filename;
}
/**
* 获取response要下载的文件的默认路径
*
* @param response
* @return
*/
public static Map<String,String> getFilePath(HttpResponse response, String url, String diskUrl) {
Map<String,String> map = new HashMap<>();
String filepath = diskUrl;
String filename = getFileName(response, url);
String contentType = response.getEntity().getContentType().getValue();
if(StringUtils.isNotEmpty(contentType)){
// 获取后缀 String regEx = ".+(.+)$";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(filename);
if (!m.find()) {
// 如果正则匹配后没有后缀,则需要通过response中的ContentType的值进行匹配 filename = filename +".gz";
}else{
if(filename.length()>20){
filename = getRandomFileName() + ".gz";
}
}
}
if (filename != null) {
filepath += filename;
} else {
filepath += getRandomFileName();
}
map.put("filename", filename);
map.put("filepath", filepath);
return map;
}
/**
* 获取response header中Content-Disposition中的filename值
* @param response
* @param url
* @return
*/
public static String getFileName(HttpResponse response,String url) {
Header contentHeader = response.getFirstHeader("Content-Disposition");
String filename = null;
if (contentHeader != null) {
// 如果contentHeader存在 HeaderElement[] values = contentHeader.getElements();
if (values.length == 1) {
NameValuePair param = values[0].getParameterByName("filename");
if (param != null) {
try {
filename = param.getValue();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}else{
// 正则匹配后缀 filename = getSuffix(url);
}
return filename;
}
/**
* 获取随机文件名
*
* @return
*/
public static String getRandomFileName() {
return String.valueOf(System.currentTimeMillis());
}
/**
* 获取文件名后缀
* @param url
* @return
*/
public static String getSuffix(String url) {
// 正则表达式“.+/(.+)$”的含义就是:被匹配的字符串以任意字符序列开始,后边紧跟着字符“/”, // 最后以任意字符序列结尾,“()”代表分组操作,这里就是把文件名做为分组,匹配完毕我们就可以通过Matcher // 类的group方法取到我们所定义的分组了。需要注意的这里的分组的索引值是从1开始的,所以取第一个分组的方法是m.group(1)而不是m.group(0)。 String regEx = ".+/(.+)$";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(url);
if (!m.find()) {
// 格式错误,则随机生成个文件名 return String.valueOf(System.currentTimeMillis());
}
return m.group(1);
}
- url为第一步中从环信下载历史消息文件接口中请求返回的url(消息文件下载地址)
- targetUrl 为下载的本地存储路径
下载以后从对应的路径下就可以看到所下载的文件。

3、消息文件解压,下载完的文件是以.gz结尾的压缩文件,需要对压缩文件进行解压
public static void unGzipFile(String gzFilePath,String directoryPath) {
String ouputfile = "";
try {
//建立gzip压缩文件输入流 FileInputStream fin = new FileInputStream(gzFilePath);
//建立gzip解压工作流 GZIPInputStream gzin = new GZIPInputStream(fin);
//建立解压文件输出流// ouputfile = sourcedir.substring(0,sourcedir.lastIndexOf('.'));// ouputfile = ouputfile.substring(0,ouputfile.lastIndexOf('.')); FileOutputStream fout = new FileOutputStream(directoryPath);
int num;
byte[] buf=new byte[1024];
while ((num = gzin.read(buf,0,buf.length)) != -1) {
fout.write(buf,0,num);
}
gzin.close();
fout.close();
fin.close();
} catch (Exception ex){
System.err.println(ex.toString());
}
return;
}
gzFilePath:压缩文件路径
directoryPath:加压到的文件目录路径
解压后的文件如下图所示:

4、文件读取,将解压后的文件读取出来
FileInputStream inputStream = null;
try {
inputStream = new FileInputStream("/Users/liupeng/Downloads/download/1234567890");
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String str = null;
long i = 0;
while(true){
try {
if (!((str = bufferedReader.readLine()) != null)) break;
} catch (IOException e) {
e.printStackTrace();
}
JSONObject jo = JSONObject.parseObject(str);
System.out.println("==========================================" + i);
System.out.println("消息id:" + jo.get("msg_id"));
System.out.println("发送id:" + jo.get("from"));
System.out.println("接收id:" + jo.get("to"));
System.out.println("服务器时间戳:" + jo.get("timestamp"));
System.out.println("会话类型:" + jo.get("chat_type"));
System.out.println("消息扩展:" + jo.getJSONObject("payload").get("ext"));
System.out.println("消息体:" + jo.getJSONObject("payload").getJSONArray("bodies").get(0));
i ++;
if (i > 100) break;
}
//close try {
inputStream.close();
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
解析完以后日志打印如下:
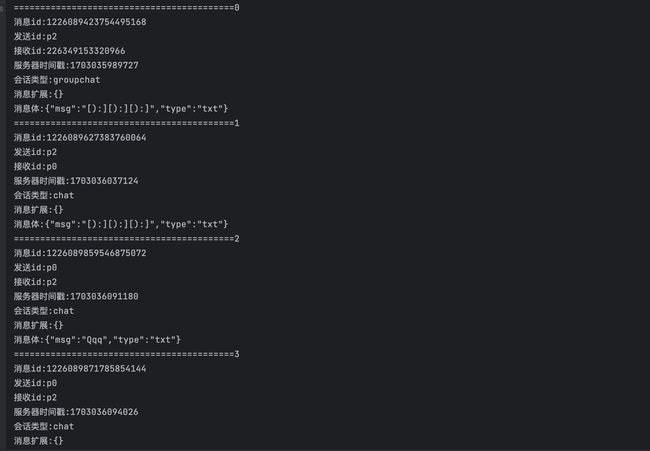
至此,解析完以后可以将解析的数据进行存储。
相关文档:
注册环信即时通讯IM:https://console.easemob.com/user/register
环信IM集成文档:https://docs-im-beta.easemob.com/document/ios/quickstart.html
IMGeek社区支持:https://www.imgeek.net/