【微服务】日志搜集elasticsearch+kibana+filebeat(单机)
日志搜集es+kibana+filebeat(单机)
日志直接输出到es中,适用于日志量小的项目
基于7.17.16版本
主要配置在于filebeat, es kibana配置改动不大
环境部署
es kibana单机环境部署
略
解压即可
常见报错,百度即可。
记录一个今天碰到的错误,
es可以正常启动,但是Head插件访问索引,点不了
这块会无法点击

org.elasticsearch.ElasticsearchException: not all primary shards of [.geoip_databases] index are active
解决
#增加配置elasticsearch,yml
#关闭geoip数据库的更新 重启即可
ingest.geoip.downloader.enabled: false
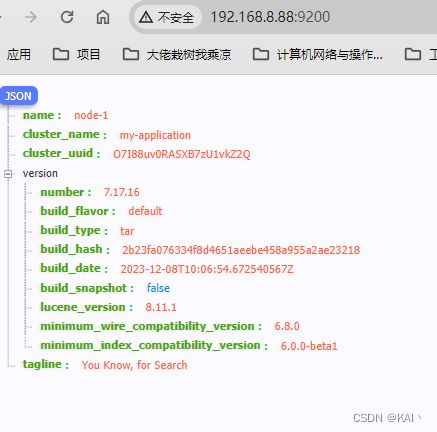
访问es ip:9200
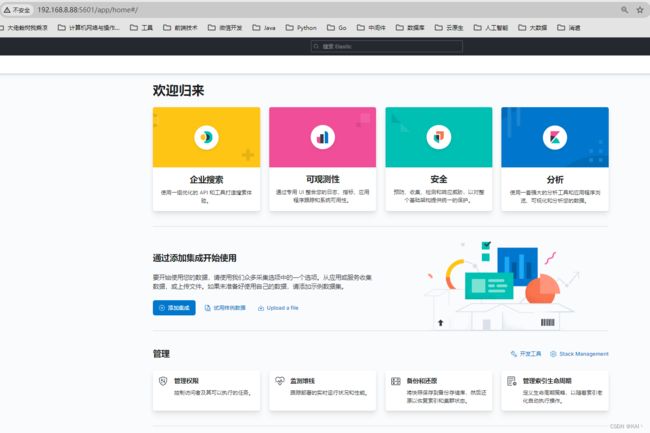
访问Kibana
ip:5601
filebeat
全部配置
filebeat.inputs:
# 采集多个服务的日志,配置多个数组即可,
- type: log
id: kw_server
enabled: true
paths:
# 多个目录配置,配置多个数组元素即可,不知道filebeat是否支持多级目录匹配 /**/*.log
- /usr/local/kw-microservices/*.log
- /usr/local/nginx/*.log
# 设置fields,标记此日志 注意字段区分,方便后面添加索引
fields:
app: kw_server
# 日志首行匹配方式
multiline.type: pattern
multiline.pattern: '^\d{4}-\d{2}-\d{2}'
multiline.negate: true
multiline.match: after
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ======================= Elasticsearch template setting =======================
setup.ilm.enabled: false # 如果要创建多个索引,需要将此项设置为 false
# 这块的配置还不太懂,貌似是为了使用自定义索引模版用的,貌似这块的配置目前是没什么用的,我没有在es中创建索引模版
setup.template.name: kw_server_index # 设置模板的名称
setup.template.pattern: kw_server-* # 设置模板的匹配方式,索引的前缀要和这里保持一致
setup.template.overwrite: true # 开启新设置的模板
setup.template.enabled: false # 关掉默认的模板配置
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# ================================== Outputs ===================================
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
index: kw_server-%{[fields.type]}-%{+yyyy.MM.dd} # 设置索引名称,后面引用的 fields.type 变量。此处的配置应该可以省略(不符合下面创建索引条件的日志,会使用该索引)
indices: # 使用 indices 代表要创建多个索引
- index: kw_server-log-%{+yyyy.MM.dd} # 设置 日志的索引,注意索引前面的 station_log 要与setup.template.pattern 的配置相匹配
when.equals: # 设置创建索引的条件:当 fields.type 的值等于 newframe-log-access 时才生效
fields.app: kw_server
# 这里是用的pipeline 过滤日志添加字段TraceId链路ID用得,之前是好使的,不知道为什么这版本不好使了,也没报错,就是字段加不上
# 改用后面的processors.script方式处理了
# pipeline: "extract-traceid-pipeline"
# ================================= Processors =================================
processors:
# 添加字段,可以增加条件判断,具体看官网文档
- add_fields:
target: ""
fields:
label: "kw-microservices"
# 日志过滤脚本,这里用得是js语法
# 处理时间问题,提取链路ID TID
- script:
lang: javascript
id: my_filter1
tag: enable
source:
function process(event) {
var str= event.Get("message");
var time =str.split(" ").slice(0,2).join(" ");
event.Put("start_time",time);
var pattern = /(TID:[\w]+)/;
var match = str.match(pattern);
if (match) {
event.Put("TID", match[1].slice(4));
}
}
# 格式化日期
- timestamp:
# 格式化时间值 给 时间戳
field: start_time
# 使用我国东八区时间 解析log时间
timezone: Asia/Shanghai
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
# 删除字段
- drop_fields:
# when: 可以设置去除的条件
# condition
fields: ["log","host","input","agent","ecs","start_time"]
filebeat timestamp字段值不对
两种解决方式
- filebeat processors
- es pipeline
processors.script
注意 这里面得javascript ,不能使用let 只能使用var
在source中,不要使用 #代码注释,会报错。
processors:
- script:
lang: javascript
id: my_filter1
tag: enable
source:
function process(event) {
var str= event.Get("message");
var time =str.split(" ").slice(0,2).join(" ");
event.Put("start_time",time);
}
- timestamp:
# 格式化时间值 给 时间戳
field: start_time
# 使用我国东八区时间 解析log时间,必须配置,否则在kibana中查看到的会多8小时
timezone: Asia/Shanghai
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
- drop_fields:
# when: 可以设置去除的条件
# condition
fields: ["log","host","input","agent","ecs","start_time"]
es pipline
在es中创建pipline ,这个我没有试过,用的第一种方式

output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
index: kw_server-%{[fields.type]}-%{+yyyy.MM.dd} # 设置索引名称,后面引用的 fields.type 变量。此处的配置应该可以省略(不符合下面创建索引条件的日志,会使用该索引)
indices: # 使用 indices 代表要创建多个索引
- index: kw_crm_server-log-%{+yyyy.MM.dd} # 设置 日志的索引,注意索引前面的 station_log 要与setup.template.pattern 的配置相匹配
when.equals: # 设置创建索引的条件:当 fields.type 的值等于 newframe-log-access 时才生效
fields.app: kw_crm_server
pipeline: "在es中创建的pipeline名称"
添加字段
es pipline方式
之前使用7.13版本,这种方式是添加TID字段成功过的,今天使用了7.17版本不好使了,也不报错。
在开发工具中,添加模版
PUT /_ingest/pipeline/extract-traceid-pipeline
{
"description" : "extract-traceid-pipeline",
"processors" : [
{
"grok" :{
"field" : "message",
"patterns" : ["\\[(?:TID:)%{DATA:TID}\\]"],
//匹配增加忽略 表示当filebeat输入的数据没有该字段时,则不作任何处理便将文档ES,如果不配置则会抛出字段缺失的异常,文档不会正常写入。
"ignore_missing": true,
"ignore_failure": true
}
}
]
}
查看创建的结果
GET /_ingest/pipeline/extract-traceid-pipeline
filebeat processors
增加script,具体的pattern ,要看实际的过滤字段的格式
processors:
- script:
lang: javascript
id: my_filter1
tag: enable
source:
function process(event) {
var pattern = /(TID:[\w]+)/;
var match = log_message.match(pattern);
if (match) {
event.set("TID", match[1].slice(4));
}
}
kibana
在开发工具中,有grok,可以测试日志的正则表达式
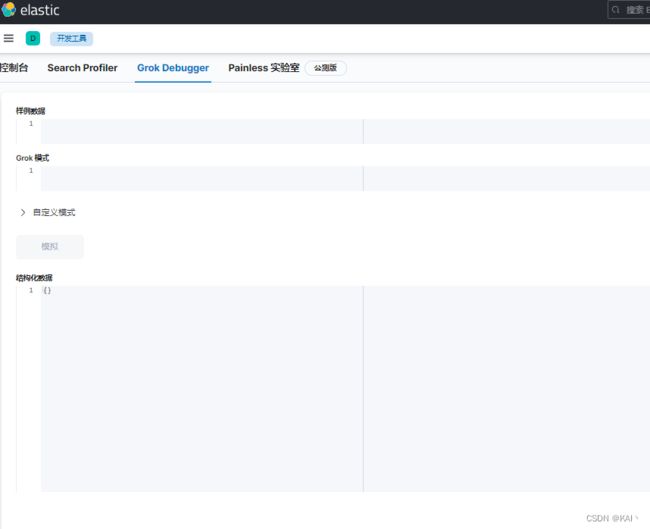
测试效果
创建索引模式

discover中,查询日志信息
- 可以看到TID被加上了
- message中的时间和timestamp是一致的
