爬虫课程笔记(二)Requests、代理、cookie和session
爬虫课程笔记
- Requests 使用入门
-
- Requests作用
- 发送简单的请求
-
- content和text 区别
- 发送带header的请求
- 发送带参数的请求
- 发送POST请求
- 贴吧爬虫案例
- 使用代理
- cookie和session
-
- 区别
- 利弊
- 处理cookies 、session请求
- 重点
Requests 使用入门
问题:
为什么要学习requests,而不是urllib?
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
- Requests能够自动帮助我们解压(gzip压缩的等)网页内容
Requests作用
作用:发送网络请求,返回响应数据
中文文档 API:http://docs.python-requests.org/zh_CN/latest/index.html
需要解决的问题:如何使用requests来发送网络请求
发送简单的请求
需求:通过requests向百度首页发送请求,获取百度首页的数据
response = requests.get(url)
response的常用方法:
• response.text
• respones.content
• response.status_code
• response.request.headers
• response.headers
content和text 区别

保存图片.py
# coding=utf-8
import requests
#发送请求
response = requests.get("https://www.baidu.com/img/bd_logo1.png")
#保存
with open("a.png","wb") as f:
f.write(response.content)
发送带header的请求
为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
• header的形式:字典
• headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”}
• 用法: requests.get(url,headers=headers)
发送带参数的请求
什么叫做请求参数:
例1: http://www.webkaka.com/tutorial/server/2015/021013/ ☓
例2: https://www.baidu.com/s?wd=python&c=b
• 参数的形式:字典
• kw = {‘wd’:‘长城’}
• 用法:requests.get(url,params=kw)
# coding=utf-8
import requests
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
# p = {"wd":"传智播客"}
# # url_temp = "https://www.baidu.com/s?"
# url_temp = "https://www.baidu.com/s"
#
# r = requests.get(url_temp,headers=headers,params=p)
# print(r.status_code)
# print(r.request.url)
url = "https://www.baidu.com/s?wd={}".format("传智播客")
r = requests.get(url,headers=headers)
print(r.status_code)
print(r.request.url)

发送POST请求
哪些地方我们会用到POST请求:
• 登录注册( POST 比 GET 更安全)
• 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
用法:
response = requests.post("http://www.baidu.com/", data = data,headers=headers)
data 的形式:字典
下面我们通过百度翻译的例子看看post请求如何使用
案例:翻译英文
# coding=utf-8
import requests
import json
import sys
query_string = sys.argv[1]
headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"}
post_data = {
"query":query_string,
"from":"zh",
"to":"en",
}
post_url = "http://fanyi.baidu.com/basetrans"
r = requests.post(post_url,data=post_data,headers=headers)
# print(r.content.decode())
dict_ret = json.loads(r.content.decode())
ret = dict_ret["trans"][0]["dst"]
print("result is :",ret)
贴吧爬虫案例

# coding=utf-8
import requests
class TiebaSpider:
def __init__(self, tieba_name):
self.tieba_name = tieba_name
self.url_temp = "https://tieba.baidu.com/f?kw=" + tieba_name + "&ie=utf-8&pn={}"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
def get_url_list(self): # 1.构造url列表
# url_list = []
# for i in range(1000):
# url_list.append(self.url_temp.format(i*50))
# return url_list
return [self.url_temp.format(i * 50) for i in range(1000)]
def parse_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode()
def save_html(self, html_str, page_num): # 保存html字符串
file_path = "{}—第{}页.html".format(self.tieba_name, page_num)
with open(file_path, "w", encoding="utf-8") as f: # "李毅—第4页.html"
f.write(html_str)
def run(self): # 实现主要逻辑
# 1.构造url列表
url_list = self.get_url_list()
# 2.遍历,发送请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
# 3.保存
page_num = url_list.index(url) + 1 # 页码数
self.save_html(html_str, page_num)
if __name__ == '__main__':
tieba_spider = TiebaSpider("lol")
tieba_spider.run()
使用代理


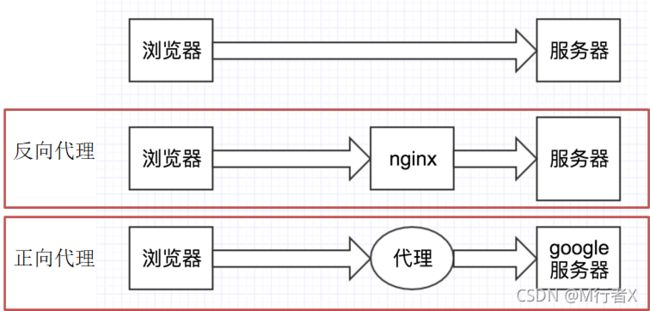
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
import requests
# 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
代理网站:https://proxy.mimvp.com/
案例
# coding=utf-8
import requests
proxies = {"http":"http://163.177.151.23:80"}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
r = requests.get("http://www.baidu.com",proxies=proxies,headers=headers)
print(r.status_code)
cookie和session
区别
• cookie数据存放在客户的浏览器上,session数据放在服务器上。
• cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
• session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。
• 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
利弊
带上cookie、session的好处:
能够请求到登录之后的页面
带上cookie、session的弊端:
一套cookie和session往往和一个用户对应
请求太快,请求次数太多,容易被服务器识别为爬虫
不需要cookie的时候尽量不去使用cookie
但是为了获取登录之后的页面,我们必须发送带有cookies的请求
处理cookies 、session请求

3种方式登录
# coding=utf-8
import requests
session = requests.session()
post_url = "http://www.renren.com/PLogin.do"
post_data = {"email":"[email protected]", "password":"alarmchime"}
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"
}
#使用session发送post请求,cookie保存在其中
session.post(post_url,data=post_data,headers=headers)
#在使用session进行请求登陆之后才能访问的地址
r = session.get("http://www.renren.com/327550029/profile",headers=headers)
#保存页面
with open("renren1.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
# coding=utf-8
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
"Cookie":"anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; [email protected]; depovince=BJ; jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw; ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1; ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg; t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9; id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
}
r = requests.get("http://www.renren.com/327550029/profile",headers=headers)
#保存页面
with open("renren2.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
字典推导式

# coding=utf-8
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36",
}
cookies="anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; [email protected]; depovince=BJ; jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw; ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1; ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg; t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9; id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}
print(cookies)
r = requests.get("http://www.renren.com/327550029/profile",headers=headers,cookies=cookies)
#保存页面
with open("renren3.html","w",encoding="utf-8") as f:
f.write(r.content.decode())
重点
### 判断请求否是成功
assert response.status_code==200
### url编码
https://www.baidu.com/s?wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2
### 字符串格式化的另一种方式
"传{}智播客".format(1)
### 使用代理ip
- 准备一堆的ip地址,组成ip池,随机选择一个ip来时用
- 如何随机选择代理ip,让使用次数较少的ip地址有更大的可能性被用到
- {"ip":ip,"times":0}
- [{},{},{},{},{}],对这个ip的列表进行排序,按照使用次数进行排序
- 选择使用次数较少的10个ip,从中随机选择一个
- 检查ip的可用性
- 可以使用requests添加超时参数,判断ip地址的质量
- 在线代理ip质量检测的网站
### 携带cookie请求
- 携带一堆cookie进行请求,把cookie组成cookie池
### 使用requests提供的session类来请求登陆之后的网站的思路
- 实例化session
- 先使用session发送请求,登录对网站,把cookie保存在session中
- 再使用session请求登陆之后才能访问的网站,session能够自动的携带登录成功时保存在其中的cookie,进行请求
### 不发送post请求,使用cookie获取登录后的页面
- cookie过期时间很长的网站
- 在cookie过期之前能够拿到所有的数据,比较麻烦
- 配合其他程序一起使用,其他程序专门获取cookie,当前程序专门请求页面
### 字典推导式,列表推导式
cookies="anonymid=j3jxk555-nrn0wh; _r01_=1; _ga=GA1.2.1274811859.1497951251; _de=BF09EE3A28DED52E6B65F6A4705D973F1383380866D39FF5; [email protected]; depovince=BJ; jebecookies=54f5d0fd-9299-4bb4-801c-eefa4fd3012b|||||; JSESSIONID=abcI6TfWH4N4t_aWJnvdw; ick_login=4be198ce-1f9c-4eab-971d-48abfda70a50; p=0cbee3304bce1ede82a56e901916d0949; first_login_flag=1; ln_hurl=http://hdn.xnimg.cn/photos/hdn421/20171230/1635/main_JQzq_ae7b0000a8791986.jpg; t=79bdd322e760beae79c0b511b8c92a6b9; societyguester=79bdd322e760beae79c0b511b8c92a6b9; id=327550029; xnsid=2ac9a5d8; loginfrom=syshome; ch_id=10016; wp_fold=0"
cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}
[self.url_temp.format(i * 50) for i in range(1000)]
### 获取登录后的页面的三种方式
- 实例化session,使用session发送post请求,在使用他获取登陆后的页面
- headers中添加cookie键,值为cookie字符串
- 在请求方法中添加cookies参数,接收字典形式的cookie。字典形式的cookie中的键是cookie的name对应的值,值是cookie的value对应的值
