JavaScript 数据结构(八):散列表
JavaScript 数据结构系列目录
JavaScript 数据结构(一): 数组
JavaScript 数据结构(二): 栈
JavaScript 数据结构(三):队列
JavaScript 数据结构(四):双端队列
JavaScript 数据结构(五):链表
JavaScript 数据结构(六):集合
JavaScript 数据结构(七):字典
JavaScript 数据结构(八):散列表
JavaScript 数据结构(九): 树
JavaScript 数据结构(十):二叉堆和堆排序
JavaScript 数据结构(十一):图
文章目录
- JavaScript 数据结构系列目录
- 一、散列表的概述
- 二、创建散列表类
- 三、为散列表类补充方法
-
- 1、loseloseHashCode 方法
- 2、put 方法
- 3、get 方法
- 4、remove 方法
- 四、使用 HashTable 类
- 五、散列集合
- 六、处理散列表中的冲突
-
- 1、分离链接
-
- (1)、put 方法
- (2)、get 方法
- (3)、remove 方法
- 2、线性探查
-
- 1、put 方法
- 2、get 方法
- 3、remove 方法
- 3、创建更好的散列函数
- 相关文章
一、散列表的概述
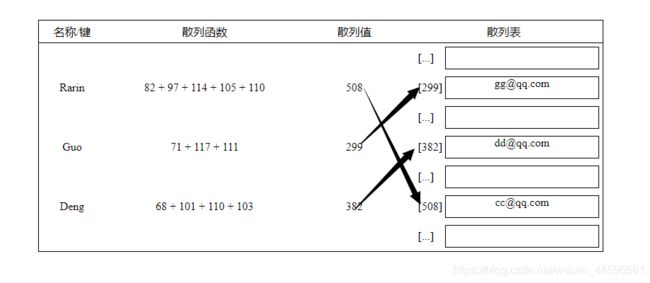
散列表(Hash table) 又称 哈希表,其是根据关键码值(Key Value)而直接进行访问的一种数据结构。
也就是说,它通过将关键码值映射到表中的某个位置来访问记录,方便加快查找速度。
那么这个映射函数叫做 散列函数。
如图所示:
二、创建散列表类
知道了散列表的概念后,那我们像往常一眼动手创建一个表示散列表的类。
当然我们还需要一个辅助函数 auxiliaryFn 与一个辅助类 ValuePair。
const auxiliaryFn = item => {
if ( item === null ) return 'NULL';
else if ( item === undefined ) return "UNDEFINED";
else if ( typeof item === "string" || item instanceof String ) return `${item}`;
return item.toString();
}
class ValuePair {
constructor(key,value) {
this.key = key;
this.value = value;
}
toString() {
return `[#${this.key}: ${this.value}]`;
}
}
class HashTable {
constructor(toStrFn = auxiliaryFn) {
this.toStrFn = toStrFn;
this.table = {}
}
}
然后为类添加一些基本方法 ( put,remove,get )。
三、为散列表类补充方法
1、loseloseHashCode 方法
在实现这几个基本方法前,我们首先要实现的第一个方法是散列函数。
loseloseHashCode(key) {
if ( typeof key === 'number' ) return key;
let tableKey = this.toStrFn(key),
hash = 0;
for ( let i = 0; i < tableKey.length; i++ ) hash += tableKey.charCodeAt(i);
return hash % 37;
}
hashCode(key) {
return this.loseloseHashCode(key);
}
hashCode 方法简单的调用了 loseloseHashCode 方法,将 key 作为参数传入,获取 loseloseHashCode 返回回来的 key 值并返回。
在 loseloseHashCode 方法中,其作用是将我们传过来的 key 值转化成 ASCII 码方便我们直接去散列表里查找记录。
如果它传回来的是数字类型的 key 话我们就直接返回。
如果不是,那么我们先通过辅助函数将其转化成字符串,并且声明一个变量 hash 保存该字符里每个字符的 ASCII 码。
声明完毕后我们通过循环将字符串里的每个字符都迭代一次。
最后返回这个字符里的 ASCII 码的总和 余以37避免超过数值变量最大表示范围的风险(当然可能会出现重复情况,这个我们留到下面再讲)。
2、put 方法
put(key,value) {
if ( key === null || value === null ) return false;
let position = this.hashCode(key);
this.table[position] = new ValuePair(key,value);
return true;
}
put 方法与我们上一篇所讲的 Dictionary 类中的 set 方法逻辑相似。
因此我们也可以将其命名为 set,但是大多数编程语言会在 HashTable 数据结构中使用 put 方法,因此我们遵循同样的命名方式。
首先第一行我们验证 key 和 value 是否有效,如果无效则返回 false,表示这个操作无法执行。
如果有效,那么我们将 key 转化后,再从散列表里找到一个位置,用 key 和 value 创建出一个 ValuePair 实例并插入。
3、get 方法
get(key) {
let valPair = this.table[this.hashCode(key)];
return valPair === null ? null : valPair.value;
}
在此方法中,我们首先使用 hashCode 获取到 key 参数的 位置,获取后去访问该位置的记录。
如果该位置存在元素则返回元素实例的 value,如果不存在则返回 null。
4、remove 方法
remove(key) {
let hash = this.hashCode(key),
valPair = this.table[hash];
if ( valPair === null ) return false;
delete this.table[hash];
return true;
}
在此方法中,我们首先使用 hashCode 获取到 key 参数的 位置,获取后去访问该位置的记录。
如果该位置存在元素则使用对象的 delete 方法删除该记录并返回 true,如果不存在则返回 false。
四、使用 HashTable 类
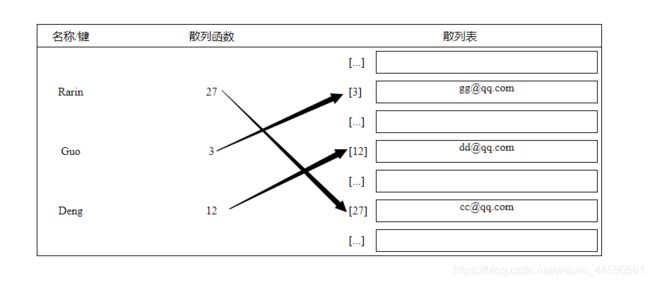
const hash = new HashTable();
hash.put("Rarin","[email protected]");
hash.put("Guo","[email protected]");
hash.put("Deng","[email protected]");
console.log(hash.hashCode('Rarin') + ' - Rarin');
console.log(hash.hashCode('Guo') + ' - Guo');
console.log(hash.hashCode('Deng') + ' - Deng');
执行上述代码,会在控制台中得到如下输出:

示例图:
我们再来执行如下代码
console.log(hash.get("Rarin"));// [email protected]
console.log(hash.get("Gg"));// null
由于 Rarin 在 散列表中存在,所以 get 方法将会返回它的值。
而 Gg 不存在于散列表中,因此它会返回 null。

五、散列集合
散列集合由一个集合构成,但是其插入、移除、获取元素时,使用的是 hashCode 函数。
与集合不同之处的是,不再添加键值对,而是只插入值而没有键。
与集合相似的是,散列集合同样只存储不重复的唯一值。
六、处理散列表中的冲突
有时候,一些键会有一些相同的散列值。
而不同的值在散列表中拥有相同的键时,我们称其为冲突。
例如如下所示的代码:
const hash = new HashTable();
hash.put("Rarin","[email protected]");
hash.put("Gin","[email protected]");
hash.put("Zhen","[email protected]");
hash.put("Guo","[email protected]");
hash.put("Deng","[email protected]");
通过对每个名字调用 hash.hashCode 方法。输出结果如下。
27 - Rarin
27 - Gin
35 - Zhen
3 - Guo
12 - Deng
这里我们可以明显的发现 Rarin 与 Gin 的位置重复了。
为了能够更直观的看出信息,我们来实现 toString 方法并且使用它。
toString() {
if ( !this.isEmpty() ) return "";
const keys = Object.keys(this.table);
let objString = `${keys[0]} => ${this.table[keys[0]].toString()}`;
for ( let i = 1; i < keys.length; i++ )
objString += `,${keys[i]} => ${this.table[keys[i]].toString()}`
return objString;
}
其输出结果

Rarin 和 Gin 有相同的散列值,也就是27。
而由于 Gin 是最后添加的,所以它将原本的 Rarin 覆盖掉了。
这种情况对于其他发送冲突的元素来说是一样的。
但我们使用一个数据结构来保存数据的目的显然不是丢失这些数据,而是通过某种方法将他们全部保存起来。
因此,当这种情况发生的时候,我们需要去解决它。
而解决的情况有几种方法:分离链接、线性探查。
当然还有个双散列法,不过那个本篇不介绍。
1、分离链接
分离链接法包括为散列表的每一个位置创建一个链表并将元素存储里面。它是解决冲突的最简单的方法,但这会造成在 HashTable 实例外还有别的存储空间。
例如,我们在之前的测试代码使用分离链接并用图表示的话,输出的结果将会是这样(为了看上去更简洁,图标中的值被省略了)。
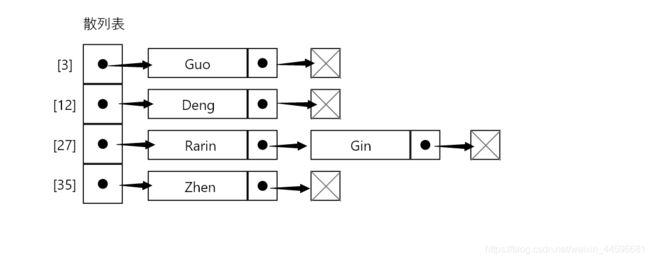
在位置 27 上,将会有包含两个元素的 LinkedList 实例。
对于分离链接和线性探查来说,只需要重写三个方法:put、get 和 remove 这三个方法。
老样子,我们来声明一个 HashTableSeparateChaining 类。
class HashTableSeparateChaining {
constructor(toStrFn = auxiliaryFn) {
this.toStrFn = toStrFn;
this.table = {};
}
}
随后依次把三个方法实现。
(1)、put 方法
put(key,value) {
if ( key === null || value === null ) return false;
let position = this.hashCode(key);
if ( this.table[position] === null ) this.table[position] = new LinkedList();
this.table[position].push(new ValuePair(key,value));
return true;
}
在这个方法中,我们要判定两种情况,一种是新元素位置是否被占据。
如果没有被占据,那么我们会在该位置上初始化一个 LinkedList 类的实例,该类我们已经在本系列的第五篇学过,这里是链接。
然后使用该类里的 push 方法向 LinkedList 实例里添加一个 ValuePair 实例。
(2)、get 方法
get(key) {
let position = this.hashCode(key),
LinkedList = this.table[position];
if ( LinkedList == null || LinkedList.isEmpty() ) return null;
let current = LinkedList.getHead();
while(current != null) {
if ( current.element.key === key ) return current.element.value;
current = current.next;
}
}
在 get 方法里,我们先需要验证在散列表里是否存在该键值。
如果存在我们则找到该键值位置的记录,并且通过循环来迭代 LinkedList 类里的元素。
直到匹配到与 key 值相同的元素,再返回。
(3)、remove 方法
remove(key) {
let position = this.hashCode(key),
LinkedList = this.table[position];
if ( LinkedList == null || LinkedList.isEmpty() ) return false;
let current = LinkedList.getHead();
while(current != null) {
if ( current.element.key === key ) {
LinkedList.remove(current.element);
if ( LinkedList.isEmpty() ) delete this.table[position];
return true;
}
current = current.next;
}
}
在该方法中,我们使用与 get 方法一样的步骤找到要找的元素,并通过 remove 方法删除。
与此同时,如果我们删除的是链表里的最后一个元素,那么我们将通过 delete 方法把该位置的元素一并删除。
2、线性探查
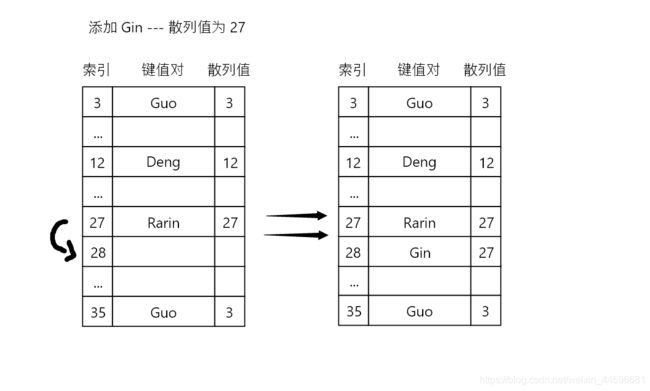
线性探查之所以称之为线性,是因为它处理冲突的方法是将元素直接存储到表中,而不是在单独的数据结构中。
譬如,当你向表中某个位置添加一个新元素的时候,如果索引为 i 的位置已经被占据了。
那么这个方法将尝试 i + 1 的位置,如果 i + 1的位置也被占据了,那么就尝试 i + 2,依此类推。
直到在散列表中找到一个空闲的位置。
下图展现了这个过程:
了解了线性探查后,我们就来将 HashTableSeparateChaining 类的 put,get,remove等方法重写一遍。
1、put 方法
put(key,value) {
if ( key === null || value === null ) return false;
let position = this.hashCode(key);
if ( this.table[position] === null ) this.table[position] = new ValuePair(key,value);
else {
let index = position + 1;
while ( this.table[index] != null ) index++;
this.table[index] = new ValuePair(key,value);
}
return true;
}
和之前一样,我们先获取由散列函数生产的位置。
获取到位置后再去验证这个位置是否存在。
如果不存在,那么我们就直接在这个新位置添加元素。
反之,我们则在这个位置上递增,去查找这个位置之后的空位,然后将新值赋上。
2、get 方法
get(key) {
let position = this.hashCode(key),
element = this.table[position];
if ( element == null ) return null;
else if ( element.key === key ) return element.value;
else {
let index = position + 1;
while( this.table[index] != null && this.table[index].key !== key ) index++;
if ( this.table[index] != null && this.table[index].key === key )
return this.table[index].value;
}
}
3、remove 方法
remove(key) {
let position = this.hashCode(key),
element = this.table[position];
if ( element == null ) return false;
else if ( element.key === key ) delete this.table[position];
else {
let index = position + 1;
while( this.table[index] != null && this.table[index].key !== key ) index++;
if ( this.table[index] != null && this.table[index].key === key )
delete this.table[index];
}
return true;
}
3、创建更好的散列函数
其实有关上述的 loseloseHashCode 散列函数并不是一个很好的散列函数,因为它会产生太多冲突。
而一个优秀的散列函数是由几方面构成的:插入和检索元素的时间(即性能),以及较低的冲突可能性。
我们可以在网上找不同的实现方法,也可以自己实现。
而另一个可以实现,比 loseloseHashCode 更好的散列函数是 djb2:
djb2HashCode(key) {
let tableKey = this.toStrFn(key),
hash = 5381;
for ( let i = 0; i < tableKey.length; i++ )
hash = (hash * 33) + tableKey.charCodeAt(i);
return hash % 1013;
}
在将键转化为字符串后,djb2HashCode 方法初始化一个变量 hash 并赋值为一个质数,然后迭代参数 key,将 hash 与 33相乘,并和当前迭代到的字符的 ASCII 码相加。
最后我们将使用相加的和与另一个随机质数相除的余数,比我们认为的散列表大小要大。(在这个例子中,我们认为散列表的大小为1000。)
相关文章
暂无