mysql多列索引(组合索引)特点和使用场景
mysql多列索引特点和使用场景
- 单列索引
-
- 查看sql的执行计划
- 索引合并
- 多列索引
-
- 再看sql的执行计划
- 多列索引的顺序
-
- 最左前缀
- 添加数据的脚本
首先创建一张表,有姓’first_name’、名’last_name’、父ID等字段:
CREATE TABLE `users` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int NOT NULL COMMENT '用户ID',
`first_name` varchar(32) DEFAULT NULL COMMENT '姓',
`last_name` varchar(32) DEFAULT NULL COMMENT '名',
`parent_id` int NOT NULL COMMENT 'parentID',
`created_by` varchar(32) NOT NULL DEFAULT 'sys' COMMENT '创建者',
`created_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_by` varchar(32) NOT NULL DEFAULT 'sys' COMMENT '修改者',
`updated_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`is_deleted` varchar(1) NOT NULL DEFAULT '0' COMMENT '是否删除:0未删除、1已删除',
PRIMARY KEY (`id`),
KEY `index_user_id` (`user_id`) USING BTREE,
KEY `index_first_name` (`first_name`) USING BTREE,
KEY `index_last_name` (`last_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 COMMENT='用户表';
接下来我们加入一些数据,代码放后边。
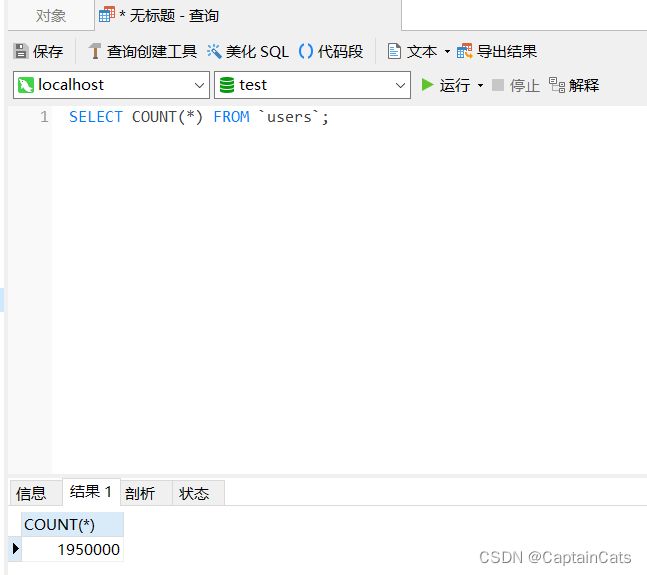
单列索引
我们知道,
where只能使用一个索引,mysql会寻找它认为是最优秀的那个索引,就是限制最严格的索引,
不过对于多个单列索引,mysql5.0及以上会进行索引合并,并将结果进行合并。
查看sql的执行计划
EXPLAIN SELECT * FROM `users` WHERE first_name = 'Vm5' AND last_name = 'utD';
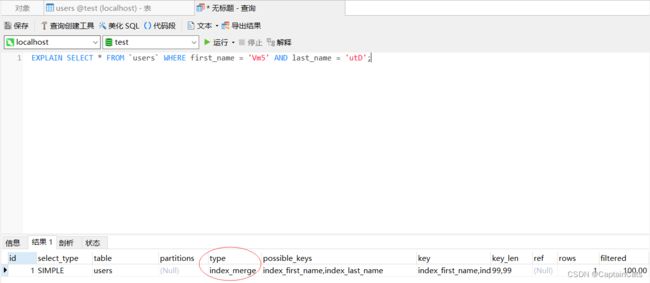
可以看到type是index_merge,这便是索引合并。
索引合并
索引合并能分三种:or联合、and相交、and和or结合,
查询能够同时使用多个单列索引,并将结果进行合并,意味着需要额外消耗cpu、内存等资源,
即便如此也比只用到一个索引的成本低。
索引合并策略是一种优化,若出现这种情况通常,通常说明需要一个包含相关列的多列索引。
多列索引
根据查询需求在多个字段上建立一个索引,一定程度上可以使用多个列的值来定位指定的行。
我们添加一个包含了first_name、last_name的多列索引index_first_last_name:
ALTER TABLE `users` ADD KEY `index_first_last_name` (`first_name`,`last_name`) USING BTREE;
再看sql的执行计划
EXPLAIN SELECT * FROM `users` WHERE first_name = 'Vm5' AND last_name = 'utD';

可见在WHERE first_name = ‘?’ AND last_name = '?'时,
多列索引限制要比之前的单列索引更强,或者说更多,
mysql可以立即找到匹配的first_name然后last_name。
不过要注意:
SELECT * FROM `users` WHERE first_name = 'Vm5' OR last_name = 'utD';
这里’or’是用不到多列索引的。
多列索引相比多个单列索引,会占用更少的磁盘空间。
有兴趣可以看下
通过B+Tree平衡多叉树理解InnoDB引擎的聚集和非聚集索引
多列索引的顺序
多列索引的顺序至关重要,
经验告诉我们,将选择性高的列放在左边(但不是绝对的),
需要考虑全局的查询需求,而不是某个具体的查询。
像:
KEY index_first_last_name (first_name,last_name)
有时候我们只需要知道用户的姓,
有时候可能还会统计某一个姓的人有多少,所以这里first_name放左边。
SELECT * FROM `users` WHERE last_name = 'utD';
只有last_name作为过滤条件时,也是用不到多列索引的。
最左前缀
对于:
KEY a_b_c (a,b,c)
多列索引最左边的列必须出现在过滤条件中,并且不能跳跃,
不然最左前缀会失效,大大降低查询效率。
可以用到最左前缀的场景有:a、a&b、a&b&c,
a&c、b&c这种是使用不到的。
添加数据的脚本
我是通过main函数来打印sql,然后输出console到文件,保存为脚本。
public static void main(String[] args) {
System.out.println("INSERT INTO `users` (`user_id`, `first_name`, `last_name`, `parent_id`) VALUES");
for (int i = 1; i < 130001; i++) {
StringBuilder sqlSb = new StringBuilder();
sqlSb.append("(");
sqlSb.append(i + ", ");
sqlSb.append("'" + RandomStringUtils.randomAlphanumeric(3) + "', ");
sqlSb.append("'" + RandomStringUtils.randomAlphanumeric(3) + "', ");
sqlSb.append(i/1000);
sqlSb.append(")");
if (i < 130000) {
sqlSb.append(",");
} else {
sqlSb.append(";");
}
System.out.println(sqlSb.toString());
}
}
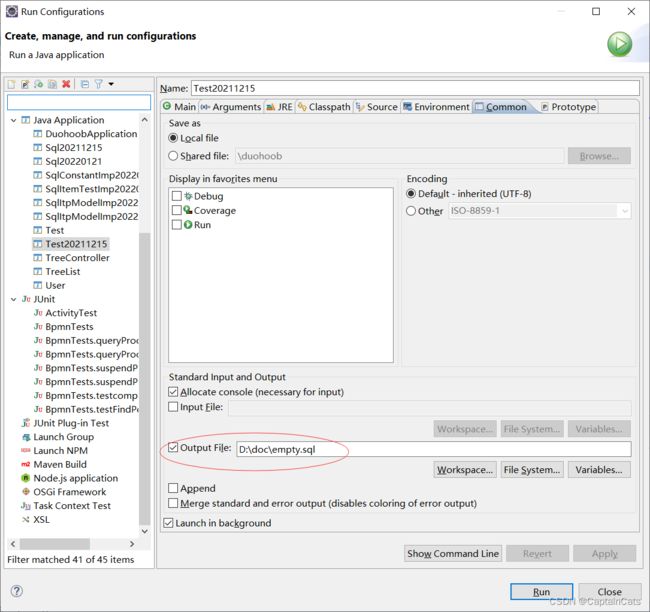
右键类→run configurations→common
参考文章:
果儿妈:MySQL单列索引和组合索引的选择效率与explain分析
雨文100:正确理解Mysql的列索引和多列索引
duanx:mysql索引之五:多列索引