基于MobileNet的人体姿态站立行走跌倒检测系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着移动互联网和智能设备的普及,人们对于智能化技术的需求越来越高。人体姿态检测作为计算机视觉领域的一个重要研究方向,可以广泛应用于人机交互、健康监测、安全监控等领域。特别是在老年人和残障人士的照护中,人体姿态检测可以起到重要的辅助作用。
在老年人和残障人士的日常生活中,跌倒是一个常见但危险的事件。跌倒不仅会导致身体受伤,还可能造成心理上的恐惧和社交上的障碍。因此,开发一种能够及时检测人体姿态并判断是否发生跌倒的系统,对于提高老年人和残障人士的生活质量具有重要意义。
目前,人体姿态检测的研究主要集中在使用传统的计算机视觉算法和深度学习方法。然而,传统的计算机视觉算法往往需要大量的特征工程和手动调参,且对于复杂场景和多人姿态的检测效果不佳。而深度学习方法虽然在人体姿态检测方面取得了很大的进展,但其模型复杂度高、计算量大,对于移动设备的实时性要求较高的应用场景仍然存在一定的挑战。
因此,本研究将基于MobileNet的人体姿态站立行走跌倒检测系统作为研究主题,旨在通过结合深度学习和移动设备的优势,提出一种高效、准确且实时的人体姿态检测系统。MobileNet是一种轻量级的卷积神经网络模型,具有较小的模型大小和较低的计算复杂度,适合在移动设备上进行实时的姿态检测。
本研究的主要目标包括以下几个方面:
- 设计和实现基于MobileNet的人体姿态检测模型,通过对人体关键点的检测和跟踪,实现对人体姿态的准确识别。
- 开发一个移动设备上的应用程序,将人体姿态检测模型应用于实际场景中,实现对人体站立、行走和跌倒等动作的实时检测。
- 评估和优化所提出的系统在准确性、实时性和稳定性等方面的性能,确保其在实际应用中的可靠性和有效性。
- 在老年人和残障人士的照护中进行实地测试和应用,验证所提出系统的实际效果和价值。
通过本研究的开展,我们可以为老年人和残障人士提供一种实用的、可靠的人体姿态检测系统,帮助他们及时发现和预防跌倒事件,提高他们的生活质量和安全性。同时,本研究还可以为计算机视觉领域的人体姿态检测研究提供一种新的思路和方法,推动该领域的进一步发展和应用。
2.图片演示

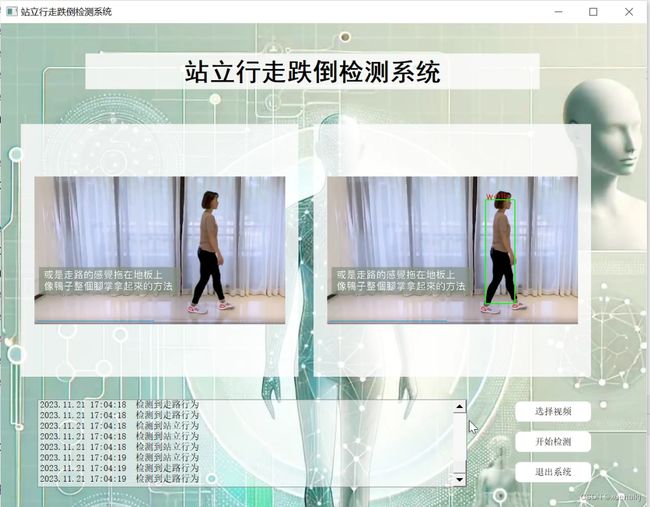

3.视频演示
基于MobileNet的人体姿态站立行走跌倒检测系统_哔哩哔哩_bilibili
4.人体姿态估计(Human Posture Estimation)
人体姿态估计可以分为单人姿态估计[4]与多人姿态估计3,其中多人姿态估计的技术路线分为自顶向下[4]与自底向上[5]两种。两种技术路线的优缺点对比如表所示。本文研究的羽毛球人体姿态估计主要在多人场景下应用,单人场景可以视为多人场景的特例。下面对多人姿态估计的两种不同的技术方法进行介绍。

计算效率高,速度与图像中的人与人相距较近时,容易出现自底向上人数无明显相关关系,适用于误判,精度不高。多人的复杂环境。精度高,适用于人数不多,且稳健性差,计算效率低,速度自顶向下图像背景清晰的情况与图像中人数呈反比关系。
自顶向下方法
在自顶向下的人体姿态估计任务中,需要通过目标检测算法检测出环境中每一个人体的检测框,姿态检测的准确度高度依赖目标区域框检测的质量。交并比(Intersection over Union, loU)表示人体目标检测框与真实人体边界框的重叠程度,是一种目标区域框检测质量的评价指标,其计算如公式所示。

其中,S为人体检测器所得人体框面积,S,为真实人体框面积,S,为S与S,的重叠面积。在人体目标检测领域,检测模型的IoU>0.5即可认为该模型已准确检测出人体边界框。
如图所示,黄色虚线框是经过Faster-RCNN检测出来的人体边界,红色虚线框是真实人体边界框,此时黄色虚线框与红色虚线框的IoU已经大于0.5,但是通过黄色虚线框的SPPE仍不能检测出人体关节点的位置。

自底向上方法
相比于自顶向下的方法,自底向上的方法将运行时间与图像中的人数解耦,同时也摆脱了自顶向下方法对人体精准检测这一要求的依赖。自底向上方法直接定位图像中所有骨骼关键点,通过聚类的方式将这些骨骼关键点拼接成不同个体,实现多人姿态估计。在自底向上的姿态估计任务中,首先要进行骨骼关键点的检测[5]。CPM、Hourglass等模型都是效果较好的骨骼点检测方法,在上节中已经介绍。对人体关节点进行聚类表现较好的算法有联想嵌入法(AssociativeEmbedding,AE)、部位亲和场(Part Affinity Fields,PAF)等。
(1)联想嵌入法[2将待检测人体关节点用标签进行标记,类似的人体关节标签将被分入同组形成一个人。该模型为每个身体关节点提供一个热图,除了生成全部关键点检测外,该模型将检测结果自动分组为不同个体。在网络的训练阶段,在每个输出热图上均加入损失函数,若h∈Rw*h对应的是第k个人体关键点的热力图,身体关节位置为T一{(xn,k)},n = 1… N ,k = 1…, K ,其中xnx是第n个人的关节点k的真实像素位置,则第n个人的关节预测结果为:

5.核心代码讲解
5.1 detect.py
封装为类后的代码如下:
class PoseDetector:
def __init__(self, weight_path, cpu=False, track=1, smooth=1, height_size=256):
self.net = PoseEstimationWithMobileNet()
self.cpu = cpu
self.track = track
self.smooth = smooth
self.height_size = height_size
checkpoint = torch.load(weight_path, map_location='cpu')
load_state(self.net, checkpoint)
self.net = self.net.eval()
if not self.cpu:
self.net = self.net.cuda()
def angle_between_points(self, pose, k1, k2, k3):
x1, y1 = pose.keypoints[k1][0], pose.keypoints[k1][1]
x2, y2 = pose.keypoints[k2][0], pose.keypoints[k2][1]
x3, y3 = pose.keypoints[k3][0], pose.keypoints[k3][1]
v1 = (x1 - x2, y1 - y2)
v2 = (x3 - x2, y3 - y2)
dot_product = v1[0] * v2[0] + v1[1] * v2[1]
norm_v1 = math.sqrt(v1[0] ** 2 + v1[1] ** 2)
norm_v2 = math.sqrt(v2[0] ** 2 + v2[1] ** 2)
cos_theta = dot_product / (norm_v1 * norm_v2)
theta = math.acos(cos_theta)
angle = math.degrees(theta)
return angle
def infer_fast(self, img, stride, upsample_ratio, pad_value=(0, 0, 0), img_mean=np.array([128, 128, 128], np.float32), img_scale=np.float32(1/256)):
height, width, _ = img.shape
scale = self.height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [self.height_size, max(scaled_img.shape[1], self.height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float()
if not self.cpu:
tensor_img = tensor_img.cuda()
stages_output = self.net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
def detect(self, img):
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts
previous_poses = []
delay = 1
orig_img = img.copy()
heatmaps, pafs, scale, pad = self.infer_fast(img, stride, upsample_ratio)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(num_keypoints):
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs)
for kpt_id in range(all_keypoints.shape[0]):
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0:
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
current_poses.append(pose)
if self.track:
track_poses(previous_poses, current_poses, smooth=self.smooth)
previous_poses = current_poses
status = ''
for pose in current_poses:
try:
angel = self.angle_between_points(pose, 10, 1, 13)
except:
angel = 0
x, y, w, h = pose.bbox
sho_r = pose.keypoints[2]
sho_l = pose.keypoints[5]
sho_y = round((sho_l[1] + sho_r[1]) / 2)
ank_r = pose.keypoints[10]
ank_l = pose.keypoints[13]
ank_y = round((ank_l[1] + ank_r[1]) / 2)
status = ""
......
该程序文件名为detect.py,主要功能是使用轻量级人体姿态估计模型进行姿态检测。具体功能如下:
- 导入所需的库和模块。
- 定义了一个函数angle_between_points,用于计算三个关键点之间的夹角。
- 初始化网络模型和相关参数。
- 加载预训练模型权重。
- 定义了一个函数infer_fast,用于快速进行姿态推断。
- 定义了一个函数detect,用于检测姿态并绘制结果。
- 在detect函数中,首先对输入图像进行预处理和推断,得到关键点热图和关键点连接图。
- 根据关键点热图和关键点连接图,提取关键点并进行分组。
- 对每个检测到的姿态进行处理,包括坐标转换、跟踪和状态判断。
- 根据判断的状态,在图像上绘制相应的文本和边界框。
- 返回检测到的状态和绘制了结果的图像。
5.2 detector_CPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.1
self.stride = 1
self.weights = './weights/output_of_small_target_detection.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.float()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
pedestrian = 0
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if lbl not in ['car', 'bus', 'truck','motorcycle','bicycle']:
continue
if lbl in ['car', 'bus', 'truck','motorcycle','bicycle']:
pedestrian += 1
pass
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes, pedestrian
这个程序文件名为detector_CPU.py,它是一个目标检测器的类。这个类有以下几个方法:
-
__init__方法:初始化目标检测器的参数,包括图像大小、阈值、步长、权重文件路径等。它还加载模型并将其移动到可用的设备上。 -
preprocess方法:对输入的图像进行预处理,包括调整图像大小、转换颜色通道、转换为张量等操作。 -
detect方法:对输入的图像进行目标检测,返回检测到的目标框和行人数量。它首先调用preprocess方法对图像进行预处理,然后使用加载的模型对图像进行推理,得到预测结果。最后,根据预测结果筛选出行人目标框,并统计行人数量。
整个程序文件的功能是使用预训练的目标检测模型对输入的图像进行行人检测,并返回检测到的行人目标框和行人数量。
5.3 detector_GPU.py
class Detector:
def __init__(self):
self.img_size = 640
self.threshold = 0.1
self.stride = 1
self.weights = './weights/Attention_mechanism.pt'
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.names
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.4)
boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
if lbl not in ['bicycle','car', 'bus', 'truck']:
continue
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
xm = x2
ym = y2
if ym +0.797* xm -509.77 > 0:
boxes.append((x1, y1, x2, y2, lbl, conf))
return boxes
这个程序文件名为detector_GPU.py,它是一个用于目标检测的类Detector的定义。该类包含了一些属性和方法,用于加载模型、预处理图像、进行目标检测等操作。
在初始化方法__init__中,定义了一些属性,如图像大小、阈值、步长、模型权重文件路径等。通过调用select_device方法选择设备,并加载模型。加载的模型会被移动到选择的设备上,并设置为评估模式。模型的一些属性也会被保存,如类别名称。
preprocess方法用于对图像进行预处理。首先将图像进行缩放,使其长宽比保持不变,并将其转换为numpy数组。然后将数组转换为torch张量,并进行归一化处理。最后,如果图像维度为3,则在第0维上添加一个维度。
detect方法用于进行目标检测。首先调用preprocess方法对输入图像进行预处理。然后将预处理后的图像输入模型,得到预测结果。对预测结果进行非最大抑制处理,得到最终的检测框。遍历检测框,根据类别名称进行筛选,将满足条件的检测框添加到列表中。最后返回检测框列表。
整个程序文件的功能是使用GPU进行目标检测。它加载了一个预训练的模型,对输入图像进行预处理,并使用模型进行目标检测,返回检测框的坐标和类别信息。
5.4 mysql_connect.py
class DatabaseConnection:
def __init__(self):
self.host = 'localhost'
self.user = 'root'
self.password = 'root'
self.database = 'openpose_data'
self.charset = 'utf8'
self.connection = None
self.cursor = None
def connect(self):
# 连接数据库
self.connection = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
charset=self.charset
)
# 创建游标
self.cursor = self.connection.cursor()
def execute_query(self, sql):
# 执行查询语句
self.cursor.execute(sql)
# 获取所有记录
result = self.cursor.fetchall()
return result
def close(self):
# 关闭游标
self.cursor.close()
# 关闭数据库连接
self.connection.close()
这个程序文件名为mysql_connect.py,它是一个用于连接MySQL数据库的Python程序。程序使用pymysql库来连接数据库。在connect()函数中,程序连接到名为openpose_data的数据库,使用root用户和密码root。连接成功后,程序创建了一个游标对象cur,用于执行SQL查询。程序执行了一个查询语句,从名为data的表中获取所有记录,并将结果存储在变量all中。最后,程序打印出查询结果,并关闭游标和数据库连接。
5.5 tracker.py
class DeepSortTracker:
def __init__(self):
cfg = get_config()
cfg.merge_from_file("./deep_sort/configs/deep_sort.yaml")
self.deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
def draw_bboxes(self, image, bboxes, line_thickness):
line_thickness = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) * 0.5) + 1
list_pts = []
point_radius = 4
for (x1, y1, x2, y2, cls_id, pos_id) in bboxes:
color = (0, 255, 0)
# 撞线的点
check_point_x = x1
check_point_y = int(y1 + ((y2 - y1) * 0.6))
c1, c2 = (x1, y1), (x2, y2)
cv2.rectangle(image, c1, c2, color, thickness=line_thickness, lineType=cv2.LINE_AA)
font_thickness = max(line_thickness - 1, 1)
t_size = cv2.getTextSize(cls_id, 0, fontScale=line_thickness / 3, thickness=font_thickness)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(image, '{} ID-{}'.format(cls_id, pos_id), (c1[0], c1[1] - 2), 0, line_thickness / 3,
[225, 255, 255], thickness=font_thickness, lineType=cv2.LINE_AA)
list_pts.append([check_point_x - point_radius, check_point_y - point_radius])
list_pts.append([check_point_x - point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y + point_radius])
list_pts.append([check_point_x + point_radius, check_point_y - point_radius])
ndarray_pts = np.array(list_pts, np.int32)
cv2.fillPoly(image, [ndarray_pts], color=(0, 0, 255))
list_pts.clear()
return image
def update(self, bboxes, image):
bbox_xywh = []
confs = []
bboxes2draw = []
if len(bboxes) > 0:
for x1, y1, x2, y2, lbl, conf in bboxes:
obj = [
int((x1 + x2) * 0.5), int((y1 + y2) * 0.5),
x2 - x1, y2 - y1
]
bbox_xywh.append(obj)
confs.append(conf)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = self.deepsort.update(xywhs, confss, image)
for x1, y1, x2, y2, track_id in list(outputs):
# x1, y1, x2, y2, track_id = value
center_x = (x1 + x2) * 0.5
center_y = (y1 + y2) * 0.5
label = self.search_label(center_x=center_x, center_y=center_y,
bboxes_xyxy=bboxes, max_dist_threshold=20.0)
bboxes2draw.append((x1, y1, x2, y2, label, track_id))
pass
pass
return bboxes2draw
def search_label(self, center_x, center_y, bboxes_xyxy, max_dist_threshold):
"""
:return: 字符串
"""
label = ''
# min_label = ''
min_dist = -1.0
for x1, y1, x2, y2, lbl, conf in bboxes_xyxy:
center_x2 = (x1 + x2) * 0.5
center_y2 = (y1 + y2) * 0.5
# 横纵距离都小于 max_dist
min_x = abs(center_x2 - center_x)
min_y = abs(center_y2 - center_y)
if min_x < max_dist_threshold and min_y < max_dist_threshold:
# 距离阈值,判断是否在允许误差范围内
# 取 x, y 方向上的距离平均值
avg_dist = (min_x + min_y) * 0.5
if min_dist == -1.0:
# 第一次赋值
min_dist = avg_dist
# 赋值label
label = lbl
pass
else:
# 若不是第一次,则距离小的优先
if avg_dist < min_dist:
min_dist = avg_dist
# label
label = lbl
pass
pass
pass
return label
该程序文件名为tracker.py,它包含了目标跟踪的相关代码。程序导入了cv2、torch和numpy等库,并从deep_sort.utils.parser和deep_sort.deep_sort模块中导入了一些函数和类。
程序定义了一个名为draw_bboxes的函数,用于在图像上绘制边界框和标签。函数接受图像、边界框列表和线条粗细作为参数,并返回绘制了边界框和标签的图像。
程序还定义了一个名为update的函数,用于更新目标跟踪器。函数接受边界框列表和图像作为参数,并返回更新后的边界框列表。在更新过程中,函数将边界框转换为xywh格式,并使用deepsort模型进行更新,然后将更新后的边界框转换为(x1, y1, x2, y2, label, track_id)的格式。
程序还定义了一个名为search_label的函数,用于在MobileNet的边界框中搜索最接近给定中心点的标签。函数接受中心点坐标、边界框列表、最大距离阈值作为参数,并返回最接近的标签。
总之,该程序文件实现了目标跟踪的相关功能,包括绘制边界框和标签、更新目标跟踪器以及搜索最接近的标签。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于MobileNet的人体姿态站立行走跌倒检测系统。它使用了多个程序文件和模块来实现不同的功能,包括目标检测、人体姿态估计、目标跟踪、数据库连接、训练模型等。
程序文件功能整理如下:
| 文件路径 | 功能概述 |
|---|---|
| detect.py | 使用轻量级人体姿态估计模型进行姿态检测 |
| detector_CPU.py | 使用预训练的目标检测模型进行行人检测(CPU版本) |
| detector_GPU.py | 使用预训练的目标检测模型进行行人检测(GPU版本) |
| mysql_connect.py | 连接MySQL数据库,执行查询操作 |
| tracker.py | 实现目标跟踪的相关功能,包括绘制边界框和标签、更新目标跟踪器、搜索最接近的标签 |
| train.py | 训练YOLOv5模型 |
| ui.py | 实现用户界面的相关功能 |
| val.py | 在验证集上评估模型性能 |
| datasets\coco.py | 提供COCO数据集的加载和处理功能 |
| datasets\transformations.py | 提供数据集的转换和增强功能 |
| datasets_init_.py | 数据集模块的初始化文件 |
| deep_sort\deep_sort\deep_sort.py | 实现Deep SORT目标跟踪算法 |
| deep_sort\deep_sort_init_.py | Deep SORT模块的初始化文件 |
| deep_sort\deep_sort\deep\evaluate.py | 评估Deep SORT模型的性能 |
| deep_sort\deep_sort\deep\feature_extractor.py | 提取特征的功能 |
| deep_sort\deep_sort\deep\model.py | Deep SORT模型的定义 |
| deep_sort\deep_sort\deep\original_model.py | 原始模型的定义 |
| deep_sort\deep_sort\deep\test.py | 测试Deep SORT模型的功能 |
| deep_sort\deep_sort\deep\train.py | 训练Deep SORT模型的功能 |
| deep_sort\deep_sort\deep_init_.py | deep模块的初始化文件 |
| deep_sort\deep_sort\sort\detection.py | 目标检测的相关功能 |
| deep_sort\deep_sort\sort\iou_matching.py | IOU匹配的功能 |
| deep_sort\deep_sort\sort\kalman_filter.py | 卡尔曼滤波的功能 |
| deep_sort\deep_sort\sort\linear_assignment.py | 线性分配的功能 |
| deep_sort\deep_sort\sort\nn_matching.py | NN匹配的功能 |
| deep_sort\deep_sort\sort\preprocessing.py | 预处理的功能 |
| deep_sort\deep_sort\sort\track.py | 跟踪的功能 |
| deep_sort\deep_sort\sort\tracker.py | 跟踪器的定义 |
| deep_sort\deep_sort\sort_init_.py | sort模块的初始化文件 |
| deep_sort\utils\asserts.py | 断言的功能 |
| deep_sort\utils\draw.py | 绘制边界框和标签的功能 |
| deep_sort\utils\evaluation.py | 评估模型性能的功能 |
| deep_sort\utils\io.py | 输入输出的功能 |
| deep_sort\utils\json_logger.py | 记录日志到JSON文件的功能 |
| deep_sort\utils\log.py | 日志记录的功能 |
| deep_sort\utils\parser.py | 解析命令行参数的功能 |
| deep_sort\utils\tools.py | 工具函数的功能 |
| deep_sort\utils_init_.py | utils模块的初始化文件 |
| models\common.py | 通用模型的定义 |
| models\experimental.py | 实验性模型的定义 |
| models\export.py | 导出模型的功能 |
| models\with_mobilenet.py | 使用MobileNet作为基础模型的定义 |
| models\yolo.py | YOLO模型的定义 |
| models_init_.py | models模块的初始化文件 |
| modules\conv.py | 卷积模块的定义 |
| modules\get_parameters.py | 获取模型参数的功能 |
| modules\keypoints.py | 关键点模块的定义 |
| modules\load_state.py | 加载模型状态的功能 |
| modules\loss.py | 损失函数的定义 |
| modules\one_euro_filter.py | 一阶欧拉滤波器的定义 |
| modules\pose.py | 姿态模块的定义 |
| modules_init_.py | modules模块的初始化文件 |
| scripts\convert_to_onnx.py | 将模型转换为ONNX格式的功能 |
| scripts\make_val_subset.py | 创建验证集子集的功能 |
| scripts\prepare_train_labels.py | 准备训练标签的功能 |
| utils\activations.py | 激活函数的定义 |
| utils\autoanchor.py | 自动锚框的功能 |
| utils\datasets.py | 数据集的定义 |
| utils\general.py | 通用功能函数 |
| utils\google_utils.py | Google云存储的功能 |
| utils\loss.py | 损失函数的定义 |
| utils\metrics.py | 模型性能指标的计算 |
| utils\plots.py | 绘制图表的功能 |
| utils\torch_utils.py | PyTorch工具函数的功能 |
| utils_init_.py | utils模块的初始化文件 |
7.OpenPose算法(OpenPose Algorithm)
算法概述
OpenPose算法是2016年卡内基梅隆大学提出的自底向上的多人姿态估计算法,该算法获得了2016年COCO比赛冠军,其执行效率不受图像中人数的影响。OpenPose算法首先使用卷积位姿机(Convolutional Pose Machines, CPM)对图像中所有人体骨骼关键点进行定位,并提出一种新的非参数编码方式部位亲和力向量场PAF,将肢体的两端进行矢量编码,实现身体部位与图像中的人体相关联,并以此为依据对图像中所有人的关键点进行组装,可以很好地实现多人姿态估计。
如图2-6所示为OpenPose算法的总体流程图。该算法将图像输入至一个并联的二分支CNN 网络结构。图2-6(a)表示输入图像是尺寸为w>h的彩色图像;图2-6(b)表示前导网络预测出肢体置信度图集合S=(S,S…,S,),其中,J表示关节点数量,S, ∈ R"h, j e {1.……J八},用于描述图像中像素点与关节点的高斯距离;图2-6©表示部位亲和力向量场L编码了人体各个骨骼关节点之间的联系[53,集合L=(L,L…Lc),每个肢体部位的部位亲和力场向量数量为C﹐L。∈Rwnh2,c e{1…C};图 2-6(d)通过贪心算法对骨骼点进行聚类;图2-6(e)表示输出人体骨骼关节点的定位结果。

OpenPose 网络结构
OpenPose 的网络结构如图所示,网络共有两个分支同时预测了肢体置信度和部位亲和力向量场。首先通过VGG-19网络进行特征提取,通过初始化操作得到特征映射F,作为网络第一阶段的输入[5]。通过网络的第一阶段后,会产生一组肢体置信度的预测S’和一组部位亲和力向量场预测L。
其中p’与(o’是阶段t用于推理的卷积神经网络。在随后的每个阶段,图像的原始特征和前一阶段所产生的两个分支预测共同输入至下一阶段,这样能够充分利用图像的原始特征,使得每一阶段都能对图像进行精准预测。
网络的整个过程共有六个阶段,在网络的早期存在肢体定位不准确的问题,但是通过网络的多次迭代,对肢体的定位会越来越准确。在每个阶段两个分支的尾部都分别应用了损失函数,为防止过拟合现象。

为了评估OpenPose算法性能,在[多人姿态估计数据集coco上进行测试,该数据集有大量训练样本,包含十万人体图像,标记超过100万个人体关节点。其标注方式有三种:目标实例、目标关键点、图像理解,使用JSON文件储存。本文所用到的标注方式为目标关键点标注,即为人体骨骼关键点标注。
人体部分关键点标注根据数据集的不同共分为三种,即16点、18点与25点,身体标注模型如图2-8所示,标签与骨骼点对应关系如表2-2所示。其中25个关键点相较于18个关键点增加了脚部的关键点。

8.人体姿态距离度量(Human Pose Distance Measurement)
姿态距离度量表征了不同姿态的相似性,是进一步发掘人体姿态深度信息的有效工具。在各种相似度计算应用中,姿态距离度量用来对两个姿态间各个维度的距离进行计算。下面对常用的三种距离度量方法进行介绍。
欧氏距离
欧氏距离也称为欧几里德距离(Euclidean Metric),在实际应用中指的是两个点之间的直线距离,源自于欧式空间中两点间的距离公式[6’I,在距离度量领域中应用最为广泛。在二维平面上的两点(x,y)与(x,y,)之间的欧式距离为:

在三维空间上的两点(,y,z)与(x,y2,zz)之间的欧氏距离为:

两个n维向量a(x1,x2…Xn)与b(21,x2,.,x2n)间的欧式距离为:

虽然欧氏距离应用较为广泛,但是由于计算过程含有开方运算,导致结果存在一定误差,并且在计算过程中将所有分量同等对待,当分量中含有位移和角度时也会按照先平方再开方的方式计算,这样的方式有时会丢失重要信息。
9.改进后模型整体结构(The Overall Structure of the ImprovedModel)
本文对OpenPose原模型的改进有以下两点:
一是将OpenPose前十层特征提取网络 VGG19更换为MobileNet,以实现更加轻量级的计算,同时也保证了模型识别的准确性,后面一阶段基于微型卷积结构的改进是为了对模型进一步的轻量化;
二是将预测肢体置信度和部位亲和力向量场的卷积结构进行调整,用四个小卷积核取代原开放式的大卷积核,以降低模型计算的复杂度。
整体模型结构如图所示,输入图像经过MobileNet特征提取后生成一组特征映射F,下一步并行进入 Branch1 与 Branch2分支预测肢体置信度和部位亲和力向量场,经过这样一个stage后得到一组肢体置信度图和一组部位亲和力向量场,随后上一阶段的输出与原始特征映射F再次汇合进入下一阶段,这样的过程会连续执行六次,最终输出图像中的人体骨骼信息。

特征提取网络改进(Feature Extraction Network Improvement)
Howard等人[2]提出的以[深度可分离卷积为核心的移动端轻量级网络MobileNet,主要以生成小型网络为目标。其思想是将标准卷积进行分解,分解为一个深度卷积与一个1×1的点卷积。深度可分离卷积运算具有基于卷积核的分解特征和组合特征以产生新的表示形式的效果,这种方式相较于标准的卷积神经网络参数量更少,运算成本更低。
一个标准的卷积结构如图3-3所示,卷积核尺寸为D×DxM,其中M是输入通道数。标准卷积运算的参数量为:

OpenPose模型前十层使用VGG19进行特征提取,当卷积神经网络的深度过高时,不仅会导致网络的性能降低,还会造成网络的收敛速度变缓,最终导致网络的检测性能降低。VGG19特征提取网络的卷积核尺寸为3×3,即公式(3-5)中DR的值为3,因输出通道数量N较大,此时n~1/9,因此本文采用MobileNet网络替换VGG19,特征提取网络的参数量约为原来的九分之一。
通过对MobileNet 与VGG19网络的参数量分析,本文对OpenPose 原模型的特征提取网络进行改进,MobileNet共有V1、V2、V3三个版本。MobileNetV1使用深度可分离卷积来构建轻量级网络,MobileNetV2提出线性倒置残差单元,虽然层数增加,但是整体网络准确率和速度都有提升,MobileNetV3结合AutoML技术以及人工微调进行更轻量级的网络构建。为测试MobileNet 网络的三个版本与OpenPose模型的契合度。

10.训练结果可视化分析
使用VGG19特征提取网络的动作分类实验结果如表3-4所示。为验证MobileNet 网络的三个版本与UpenPose 快主H0651 M hileNetV3-small)进行实取网络分别更换为MobileNetV1、MobileNetV2OF i进行分析,得出的实验结验,通过对替换后的模型精确率P、召回率R与F分数进行分析,得出的实验结果如表所示。

11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于MobileNet的人体姿态站立行走跌倒检测系统》
12.参考文献
[1]杨凯,尹映集.高校羽毛球运动对学生身心健康的影响[J].当代体育科技.2021,(8).DOI:10.16655/j.cnki.2095-2813.2006-9754-6708 .
[2]余保玲,虞松坤,孙耀然,等.基于DeepPose和Faster RCNN的多目标人体骨骼节点检测算法[J].中国科学院大学学报.2020,(6).DOI:10.7523/j.issn.2095-6134.2020.06.015 .
[3]郑烨,赵杰煜,王翀,等.基于姿态引导对齐网络的局部行人再识别[J].计算机工程.2020,(5).DOI:10.19678/j.issn.1000-3428.0056642 .
[4]郑爽,张轶.利用姿态信息实现异常行为检测[J].现代计算机.2019,(27).DOI:10.3969/j.issn.1007-1423.2019.27.009 .
[5]任文.基于Kinect运动捕捉技术的辅助训练系统的研究[J].电子设计工程.2019,(7).
[6]邓益侬,罗健欣,金凤林.基于深度学习的人体姿态估计方法综述[J].计算机工程与应用.2019,(19).DOI:10.3778/j.issn.1002-8331.1906-0113 .
[7]高丽伟,张元,韩燮.基于Kinect的三维人体建模研究[J].中国科技论文.2018,(2).DOI:10.3969/j.issn.2095-2783.2018.02.016 .
[8]蒋湘之.羽毛球教学中常见的问题及解决措施探析[J].当代体育科技.2017,(21).DOI:10.16655/j.cnki.2095-2813.2017.21.249 .
[9]韩晔彤.人工智能技术发展及应用研究综述[J].电子制作.2016,(12).DOI:10.3969/j.issn.1006-5059.2016.12.082 .
[10]崔建,李强,刘勇,等.基于决策树的快速SVM分类方法[J].系统工程与电子技术.2011,(11).DOI:10.3969/j.issn.1001-506X.2011.11.40 .