Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2)
——解读Hello World
上一章中,我们把hadoop下载、安装、运行起来,最后还执行了一个Hello world程序,看到了结果。现在我们就来解读一下这个Hello Word。
OK,我们先来看一下当时在命令行里输入的内容:
-
$mkdir input
-
$cd input
-
$echo "hello world">test1.txt
-
$echo "hello hadoop">test2.txt
-
$cd ..
-
$bin/hadoop dfs -put input in
-
$bin/hadoop jar build/hadoop-0.20.2-examples.jar wordcount in out
-
$bin/hadoop dfs -cat out/*
第1行,容易理解,我们在hadoop文件夹下建了一个input子文件夹;
第2行,进入input文件夹;
第3行,echo是指回显示,可以理解为print, 大于符(>)为重定向,正常echo是显示在屏幕上,而用了重定向后,即内容显示在了text1.txt文件里。那这句话意思是,创建一个test1.txt文件,其内容是"hello world"。 第4行类同;
第5行,回上一级目录
第6行,这里运行了一个hadoop命令, 参数为 dfs –put input in 意思是将input文件夹上传到hadoop文件系统中,并存于目录in中。
第7行,同样是hadoop命令,参数 jar XXX.jar wordcount in out 是指运行jar程序中wordcount类的程序,并传入参数 in out。 in 为输入目录 out 为输出结果目录,两个目录皆为hadoop文件系统中的目录,而并不是当前操作系统目录了。在第7行后,会看到屏幕在刷,是在计算。
第8行,cat是linux常用的命令,是将指定文件中的文本内容输出。 所以这里 cat out/* 是指把out文件夹下所有文件的文本内容输出,同时注意这里是dfs即是在hadoop文件系统中,且这个out正是第7步程序中输出的目录。所以输入该命令后,我们看到了下面的结果:

这个简单的程序目的是什么,其实比较容易看出来了,就是统计每个文件中的单词出现的数量,并将结果合并后显示出来。
可能有人就想,有什么啊,这程序我们C#、java几行代码也就实现了,有什么特别的?的确,初看过程就是。但我们深入来看一下。Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS就是分布式数据存储,这就不一样了,也就是说我的这里需要统计的文件很多的话,可能就不存在一台机器上了,而且存在不同机器上,不需要我们人为控制,而是交给Hadoop自动完成,而我们,只需要统一的接口(bin/Hadoop dfs)来访问:
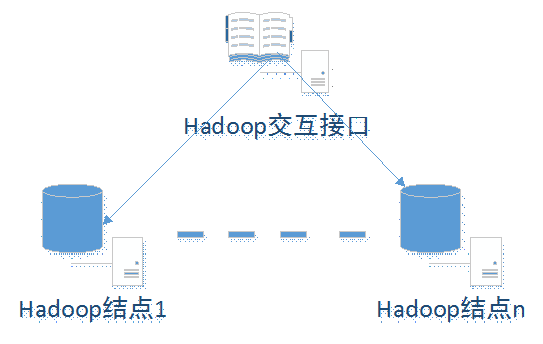
MapReduce当然就是负责计算咯,回头一想,的确这程序不简单,统计一个文件单词出现的频率容易,但时如果这些文件是分布在不同机器上,然后又需要将结果能很方便的合并起来,那就不是简单几行代码就能搞定的了。所以MapReduce就是来负责这一块的。
看到这里,我们就理解了上面的hello world,但是马上会想,这个hadoop有哪些应用场景呢?或为什么它这现在这么牛,这么流行?
现在是一个大数据时代,首先是一个存储问题,hadoop提供了一个很好的分布式文件系统,方便我们存大量数据,同时提供了统一接口。
其次,拥有了大数据,不代表能产生价值,在产生价值,就必须利用这些数据进行计算(查询、分析等),但时传统的计算就是在一台或多台机器上部署程序,然后把数据获通过接口抓取到程序里进行分析,这称之为移动数据。而hadoop不是,而是把程序自动分发到各hadoop结点上进行计算,然后通过一定机制把结果进行汇总最后返回出来,这称之为移动计算。显然,移动计算要比移动数据成本要低得多。
应用场景之一:就是搜索引擎,现在互联网数据海量,如何存储并搜索成为难点,那hadoop的两大核心框架就正符合这用处,用网络爬虫取来的海量网页数据存于分布式库,然后当去搜索时,通过各子结点并发搜索,将数据返回合并后展示。 而hadoop的产生,也就是在google在2003年到2004年公布了关于GFS、MapReduce和BigTable三篇技术论文,即google的三驾马车。Hadoop的HDFS对就google的GFS,MapReduce对就google的MapReduce,Hadoop的HBase对应google的BigTable。 (注:HBase是其于hadoop开发的类似数据操作的软件)。
应用场景之二:生物医疗,大量DNA数据存储,同时要进行比对工作,用Hadoop再合式不过了。
当然还有N多其他应用场景……
到现在hadoop的核心价值总算摸清了,一是分布式存储,二是移动计算。
为了支撑这些功能,肯定会用到不少的进程,现在我们就来了解下这些进程以及相应的命令。
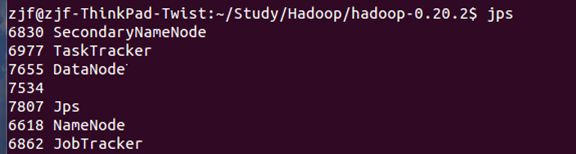
我们知道,运行$bin/start-all.sh来启动整个hadoop。然后运行$bin/jps可以看到所有运行的进程:
这些进程现在是安装在同一台机器上的,而实际分布式部署时,如下图:
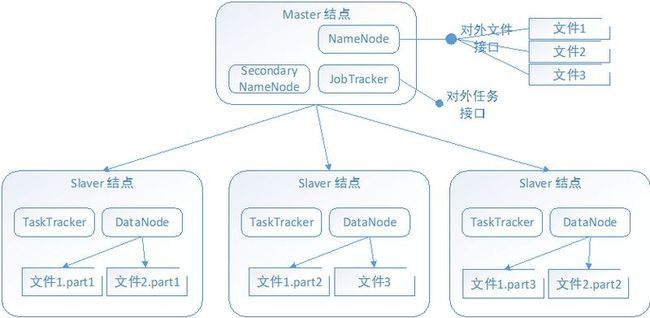
NameNode:是HDFS的守护进程,负责记录文件是如何分割成数据块以及分配存储到哪个DataNode节点上,对内存及I/O进行集中管理。一个系统中只会有一个NameNode。
DataNode:数据结点,负责将数据包读写到硬盘上。当客户端需要数据通讯时,先问NameNode获取存放到哪个DataNode,然后,客户端直接与DataNode进行通讯。
SecondaryNameNode:用来监控HDFS状态的辅助进程。与NameNode不同的时,它不接收或记录任何实时的数据变化,只与NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过SecondaryNameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时NameNode发生问题时,Secondary NameNode可以及时地作为备用NameNode使用。
JobTracker:应用程序与Hadooop之间的纽带,代码提交到集群上,JobTracker将会确定执行计划,包括决定处理哪些文件,为不同的任务分配节点以及监察所有任务的运行,如果任务失败,JobTracker将会自动重启,但分配的节点可能会不同。
TaskTracker:负责执行由JobTracker分配的单项任务,虽然单个结点上只有一个TaskTracker,但可以利用多个JVM(Java虚拟机)并行处理多个Map或reduce任务。
了解了进程后,我们再来了解下有哪些文件操作命令,
bin/hadoop是一个批处理sh文件(与bat类似),运行时需要输入子命令。子命令列表如下:
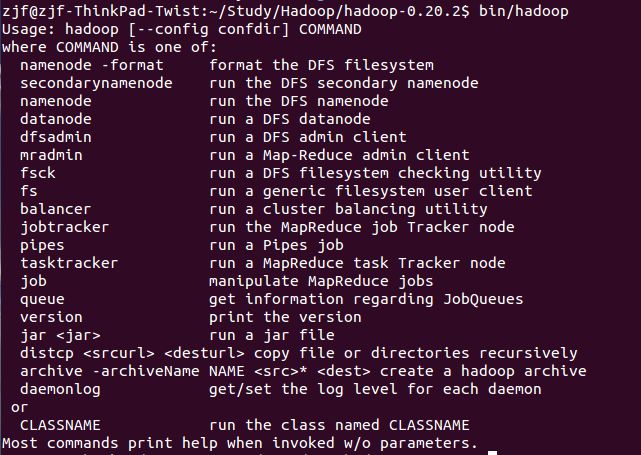
这里比较清楚了,各个子命令的描述,但这里有下fs,是我们常用的,同里里面会还有N多子命令,比如bin/hadoop fs -ls 列出文件内容。
其它fs参数清单如下:
| 命令 |
说明 |
| [-ls <path>] |
列出文件夹下的内容 |
| [-lsr <path>] |
递归列出文件夹下的内容 |
| [-du <path>] |
显示文件点用空间 |
| [-mv <src> <dst>] |
移动文件 |
| [-cp <src> <dst>] |
复制文件 |
| [-rm [-skipTrash] <path>] |
删除文件 |
| [-rmr [-skipTrash] <path>] |
删除文件夹 |
| [-put <localsrc> ... <dst>] |
将本地文件上传到服务器上 |
| [-copyFromLocal <localsrc> ... <dst>] |
将服务器文件下载到本地 |
| [-moveFromLocal <localsrc> ... <dst>] |
将服务器文件移至到本地 |
| [-get [-ignoreCrc] [-crc] <src> <localdst>] |
将服务器文件下载到本地 |
| [-getmerge <src> <localdst> [addnl]] |
将服务器文件夹内文件合并后下载到本地 |
| [-cat <src>] |
显示文件的文本内容 |
| [-text <src>] |
显示文件文本内容 |
| [-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>] |
复制文件(夹)到本地 |
| [-moveToLocal [-crc] <src> <localdst>] |
移动文件(夹)到本地 |
| [-mkdir <path>] |
创建文件夹 |
| [-setrep [-R] [-w] <rep> <path/file>] |
设置文件的复制数量 |
| [-touchz <path>] |
写一个时间戳放在文件同级目录 |
| [-test -[ezd] <path>] |
测试文件是否存在 |
| [-stat [format] <path>] |
返回文件状态 |
| [-tail [-f] <file>] |
显示文件最后1KB的内容 |
| [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] |
修改文件(夹)属性 |
| [-chown [-R] [OWNER][:[GROUP]] PATH...] |
修改文件owner属性 |
| [-chgrp [-R] GROUP PATH...] |
修改文件(夹)属性 |
| [-help [cmd]] |
显示帮助 |