python爬取虎嗅网首页新闻超链接、图片链接、标题
要求:爬取该网站首页内容,即获取每一个超链接、图片链接、标题,以.CSV存储(一行就是一个新闻的超链接、图片链接、标题)
文章目录
-
- 用不上的思考过程
- 正文
-
-
- 1.观察新闻页面源码
- 2.编写代码提取信息
- 3.观察首页源码并编写正则表达式
-
- 源码
建议直接点正文
用不上的思考过程
1.新闻超链接存在于a的herf属性中,/article/408795.html,前面要加上https://www.huxiu.com
2.图片链接暂时还不知道存在哪
https://img.huxiucdn.com/article/cover/202102/06/102020604605.jpg?imageView2/1/w/800/h/450/|imageMogr2/strip/interlace/1/quality/85/format/jpg
3.标题存在于img alt和h5节点下的内容中,h5.string
img alt查了一下,是为了不能正确看到图片而显示出的标签。所以标题存在于h5节点下的内容

功夫不负有心人,在我不断往下滑的时候瞟到了熟悉的题目
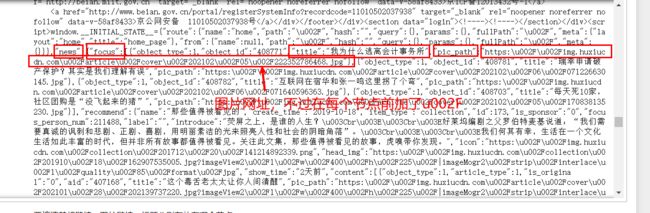
news下的focus下的title是标题,pic_path是图片链接,但在每个节点前加了u002F,第一个\u200F要去掉,后面都要去除u002F
上面属于网站的 新闻聚焦 部分
再往下滑

但是这貌似不是首页的新闻,有些找不到,但是它这个新闻标题,链接和图片链接都能找得到
标题存放于title项
链接存放于share_url
图片链接存放于pic_path
链接和图片链接都要删除掉一定内容(u002F)
正文
首页源代码下有些新闻标签没有标图片链接,有些甚至没标题~~(这就离谱)~~ ,陷入了思考…
我突然想到,可以先进入网址再查看图片和标题
希望他每个网页不要布局不太一样…
仔细观察了几个新闻页面的源代码,所幸,是一样的
所以现在的步骤应该是:
1.用一定的手法找到所有新闻链接
2.获取新闻链接后,进入,获取图片链接和标题
3.按格式存储入文件
现在要在新闻页面中进行操作,提取出标题和图片链接(问了一下我哥,他说要学正则表达式,我就认真看了看正则)
1.观察新闻页面源码
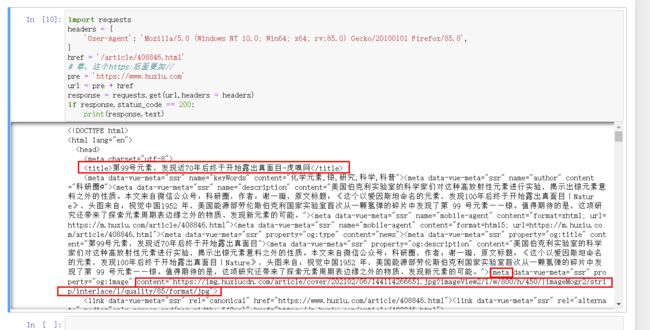
2.编写代码提取信息
通过观察可以得知:
图片链接:meta的content属性
根据网页源码写了正则表达式,可以提取出来。不过findall以列表形式返回,所以[0]取单个元素。
标题:title节点的内容
可由BeautifulSoup直接拿出,soup.title.string,不过显示多了-虎嗅网,通过split方法取出即可
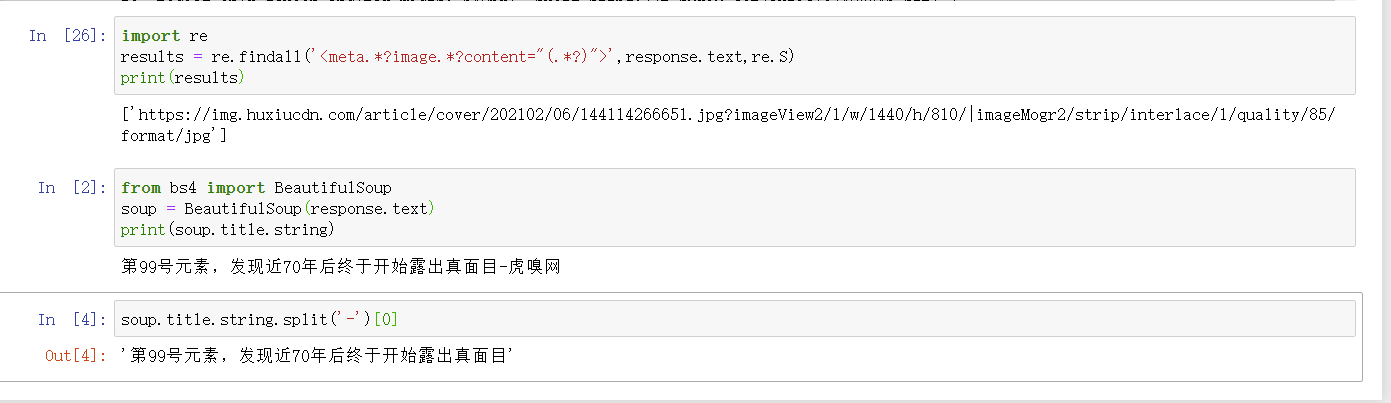
3.观察首页源码并编写正则表达式
现在已经搞定一个新闻的了,现在就是差得到新闻链接了~
所以我要写一个提取新闻网址的正则表达式
所以我们得观察一下新闻网址前后的内容
首页源代码的新闻网址在a节点的href属性中

首页的新闻
视频新闻部分的a节点是这样的
![用1000块竟然就能得到新年超跑?]()
草,还有可能提取到用户页面,但是这个href属性是完整的。
普通新闻的a节点是这样的
在源代码中看到有一部分是这样写的
如果正则只写到a.*?href会有很多干扰项
最终确定为a.*?href="/article(.*?)",这样可以保证提取出来的是新闻页面链接(相对的)
href="/article/408717.html"
import re
results = re.findall('a.*?href="/article(.*?)"',html,re.S)
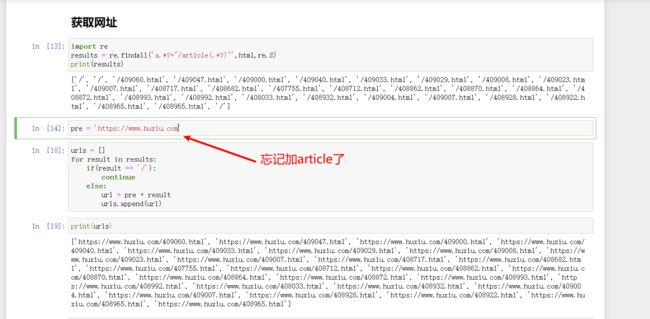
最后还要加上前缀https:/ww.huxiu.com/article
出现了一个错误:由于正则中精准到article,而我前缀pre只到.com,所以出来的网址访问不了。改一下就好了
源码
# 库导入
import requests
from bs4 import BeautifulSoup
import re
import csv
# 获取每个新闻的网址
# Chrome可以通过about::version查看user-agent信息,在 代理信息 处
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 不同网站对headers内容要求不同,虎嗅 有user-agent即可
r = requests.get('https://www.huxiu.com/',headers = headers)
# 调用BeautifulSoup对响应进行初始化,此处解析器选用lxml
soup = BeautifulSoup(r.text,'lxml')
html = soup.prettify()
# 通过正则表达式找到网址
results = re.findall('a.*?="/article(.*?)"',html,re.S)
# 由于提取出来的内容是相对路径,所以得给他加上前缀
pre = 'https://www.huxiu.com/article'
urls = []
# 将url存入列表中
for result in results:
if(result == '/'):
continue
else:
url = pre + result
urls.append(url)
# 访问与存储
# 写入模式下创建一个空头,下面存储的时候改为追加模式a
with open('imawork.csv','w',encoding = 'utf-8') as csvfile:
fieldnames = ['超链接','图片链接','标题']
writer = csv.DictWriter(csvfile,fieldnames = fieldnames)
writer.writeheader()
for url in urls:
# 请求新闻网址
response = requests.get(url,headers = headers)
# 获取标题
soup = BeautifulSoup(response.text)
_title = soup.title.string.split('-')[0]
# 获取图片链接
imglink = re.findall('' ,response.text,re.S)[0]
# 存储入csv文件
with open('imawork.csv','a',encoding = 'utf-8') as csvfile:
fieldnames = ['超链接','图片链接','标题']
writer = csv.DictWriter(csvfile,fieldnames = fieldnames)
_dict = {'超链接':url,'图片链接':imglink,'标题':_title}
writer.writerow(_dict)
运行之后就可以看到程序目录下生成了imawork.csv文件啦。
最后,感谢学习过程中开哥不厌其烦的回答我一些琐碎的问题。
��������