【书生·浦语】大模型实战营——第四课笔记
教程链接:https://github.com/InternLM/tutorial/blob/main/xtuner/README.md
视频链接:https://www.bilibili.com/video/BV1yK4y1B75J/?vd_source=5d94ee72ede352cb2dfc19e4694f7622
本次视频的内容分为以下四部分:

目录
微调简介

微调会使LLM在具体的领域中输出更好的回答。有两种微调模式:
1、增量预训练微调:学会垂类领域的常识(只需要回答)
2、指令跟随微调:学会对话模板(一问一答)
场景与所需的训练数据不一样。
实际对话时,通常会存在三种角色:
1、System:要求系统担任一个具体的角色
2、User:用户进行提问
3、Assistant:根据user输入,结合system上下文,做出回答
这些机械性的工作已经用xtuner打包好了,一键启动即可。
指令跟随微调时,不同的对话模板

不同的模型在微调时的数据会使用不同的prompt模板。
比如LlaMa2,会用sys的块来表示system内容,INST的块来表示User指令部分。而InternLM的模板则有五个。
而在部署时,system部分是由模板自动添加的,用户的输入则放入user部分,而system部分使用的模板可以自行更改。
增量预训练微调
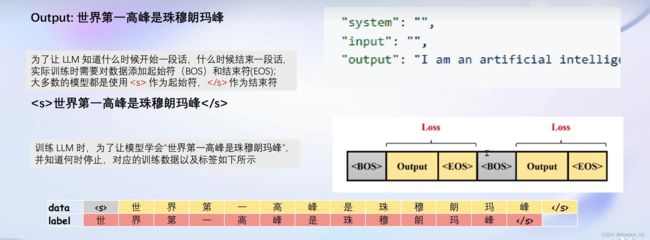
只需要计算assistant部分的损失
微调原理
 原来的大模型权重参数主要集中于linear中,这个linear形状非常大,如果对其进行微调,那么所需的显存非常高,训练非常贵。
原来的大模型权重参数主要集中于linear中,这个linear形状非常大,如果对其进行微调,那么所需的显存非常高,训练非常贵。
lora是在原来的linear旁边加了一个支路(由两个小的linear组成),通常叫作Adapter。
微调时只对Adapter进行训练,而预训练的权重冻住,就能降低很多显存占用。
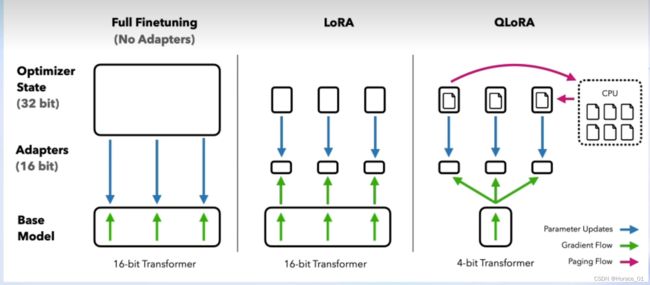
QLoRA是加载模型时使用4bit量化的方式进行加载。
正常模型训练时一般都是使用float32,相当于降低了精度。降低了表达精度,自然能力会下降些。
XTuner微调框架
简介图片就不介绍了。

xtuner数据引擎弄了很多个数据集的映射函数,方便开发者多关注模型,不用费心处理数据格式。
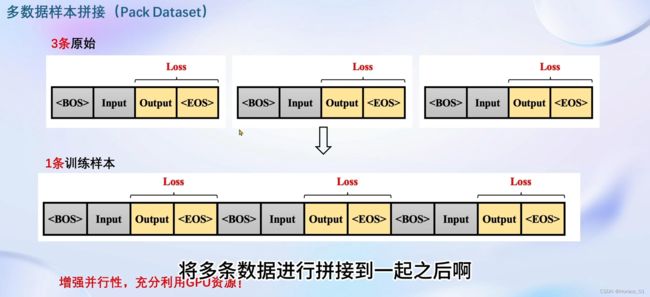
当显卡显存更大时,当然要尽可能利用显卡的资源,增加其并行性。这里xtuner可以做多样本的数据拼接,一下子输入好几个数据,占满显存,提升效率。
8GB显存玩转LLM
Flash Attention和DeepSpeed ZeRO是xtuner最重要的两个优化技巧。


动手实战环节
ssh连接开发机后敲bash进入环境。

创建环境与激活
敲入以下命令,新建一个conda环境,这个环境叫xtuner0.1.9
conda create --name xtuner0.1.9 python=3.10 -y
键入以下命令,进入环境
conda activate xtuner0.1.9

安装xtuner源码


下载过程会有点久,需要耐心等待。
下载完成后,创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
微调
准备配置文件
xtuner list-cfg
可以列出所有内置的配置文件。如下图所示
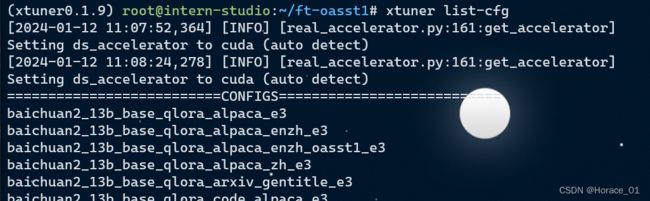
其中,每个字符串的含义如下:
第一个字符串代表是哪个大模型,如baichuan2
第二个字符串代表模型参数,如13B
第三个字符串代表模型类型,如base基座模型或chat聊天模型
第四个字符串代表微调算法,使用lora还是qlora还是全参数微调
第五个字符串代表在哪个数据集上微调,如alpaca
第六个字符串代表跑几个epoch
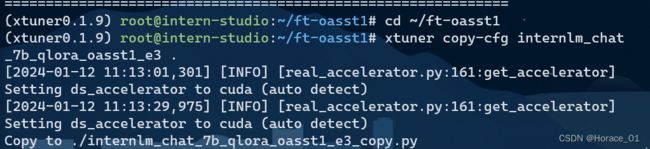
通过xtuner的copy-cfg命令拷贝一个配置文件到指定目录中,是internlm7b,用qlora微调,在oasst1数据集上微调,跑3个epoch
这个过程会比较久,要等一两分钟。
模型下载
用教学平台的同学直接从目录中进行复制
数据集下载
本身数据集在hugging face上,平台已经提前下载好放到share目录里了。直接拷贝即可。
修改配置文件
修改配置文件py里的预训练模型路径和数据路径。
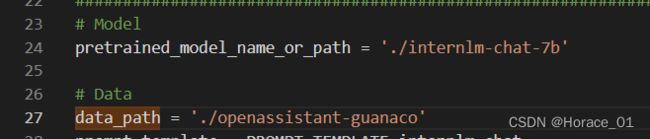
再改epoch参数为1

常用的超参对应的意义
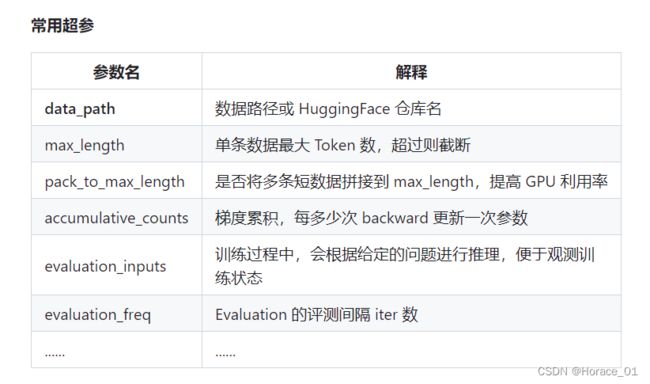
其中max_length和batch_size可以调整所占用的显卡资源。
开始微调
使用以下命令进行微调:
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py

其中的warning信息不用理。
![]()
上图的loading shards指的是加载基座模型的过程。
接下来在准备数据集。

可以看到下图中有个map。Map操作就是将数据集映射到标准训练格式,User,System啥的

看到这个Epoch(train)就说明微调已经开始了。其中eta是剩余的训练时间。这里看到是4:21:51,要接近4个半小时。

此时按Ctrl+C,终止微调过程。我们发现,微调时会多出一个目录叫work_dirs,存储微调时的日志文件。

在进行下一次训练时,最好先删除上次的工作路径。

加上deepspeed参数来加速训练。我们可以从下图看到,加速后的微调预计的剩余时间直接减少了三倍多,变成1:16:44了。可见deepspeed加速训练的效果。

为了保持训练不被中断,引入tmux这个库,引入守护进程。


使用tmux创建一个会话,命令如下
tmux new -s finetune
这个时候进入了一个全新的界面,此时属于一个tmux session中,这个session叫finetune

此时按Ctrl+B,手指松开再按D就可以推出tmux的窗口。
如何重新进入这个session呢?输入tmux attach -t finetune命令即可。
![]()
此时再输入训练命令(带deepspeed参数的),就不怕训练被打断了。
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
此时可以随便进入、退出这个tmux窗口。
一个小时后见!
好的,睡得有点迷糊,感觉睡晕过去了。
tmux窗口中看到类似这样的输出,就算训练成功了。

查看微调后的目录文件
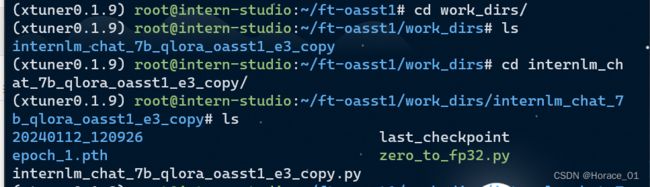
从目录中可以看到一个pth结尾的文件,pth通常是模型参数文件的后缀,因为只训练了一个epoch,所以这里只有一个epoch_1的模型文件。
还可以进入以日期命名的目录,这里存放了日志文件,可以cat进行查看。
将得到的pth模型文件转换为hugging face的lora模型
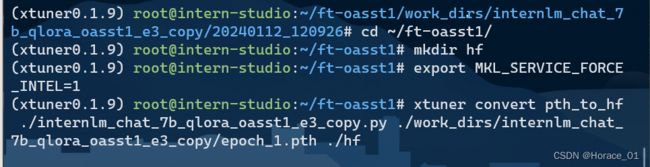
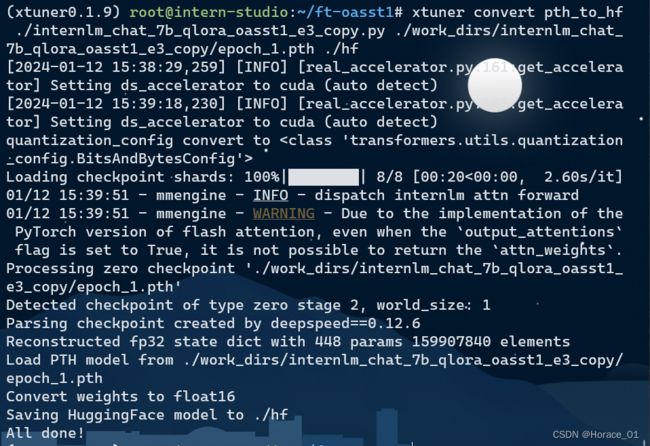
当看到All done! 时,说明转换已经成功。
这个adapter_model.safetensors就是hugging face的lora模型。

部署与测试
将huggingface adapter合并到大语言模型
敲入以下命令并耐心等待,看到All Done,即转换成功。

可以查看merged目录(合并后的目录)有的文件
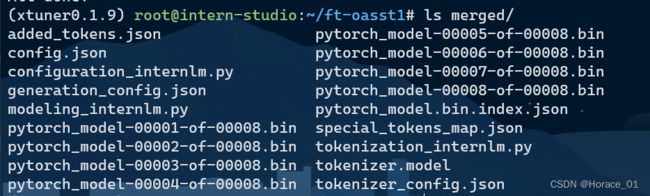
与合并后的模型进行对话
敲以下命令并耐心等待
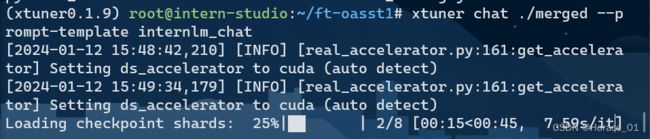
当看见double enter to end input,就可以开始对话了。输完问题后,需要敲两次回车才能开始回复。

从资源监控我们可以看到,占用了17G的显存。

这里可以载入4bit量化后的模型,看看差异。

实际运行时,可以看到4bit量化的模型,回答速度非常快。
